Un modèle de Deep Learning doit à la fois optimiser son entraînement et généraliser sa prédiction à l’ensemble des données. Un outil est là pour ça : la Regularization.
La Regularization est un ensemble de méthode qui permet à la fois d’optimiser l’apprentissage d’un modèle de Deep Learning et de contrer l’overfitting (manque de généralisation).
Il existe plusieurs outils pour faire de la Régularisation :
- Dropout
- Batch Normalization
- Weight Decay, aussi appelé L2 Regularization (ou par abus Regularization)
C’est donc de ce dernier dont on va parlé dans cet article !
Qu’est-ce que la Regularization ?
Diminution des poids
La Regularization Weight Decay, en français Diminution des Poids permet d’améliorer la généralisation lors de l’apprentissage du modèle.
De la sorte, le modèle va être performant à la fois sur les données d’entraînements mais aussi sur toutes les autres données.
Comme expliqué dans cet article, lors de l’apprentissage, certaines poids du modèle augmentent tandis que d’autres diminuent.
Le but du Weight Decay est de diminuer la valeur des poids trop important.
C’est une sorte de handicap que l’on donne au poids qui augmentent trop vite. Grâce à cet handicap, le modèle doit performer ailleurs que sur les neurones associés à ces poids. Ainsi, d’autres poids vont pouvoir progresser pour transmettre de l’information.
Voyez le comme ça : si un joueur de tennis est ultra-performant pour envoyer la balle avec son coup droit mais qu’il n’est pas bon sur son revers. Eh bien l’idée de la Regularization serait de lui interdire d’utiliser son coup droit pendant l’entraînement de tel sorte qu’il soit obligé d’améliorer son revers pour atteindre son objectif : battre son adversaire.
Cette technique lui permet au tennisman de généraliser son apprentissage, de tel sorte qu’il pourra jouer les balles venant de sa gauche aussi bien que celle venant sur sa droite.
De la même manière, cette technique permet au modèle de mieux généraliser son apprentissage et donc améliore ses performances sur les données non observées.
L1 & L2 Regularization
En pratique, la Regularization s’effectue après avoir calculé la loss function. On applique la fonction de régularisation qui :
- pour la L1-Regularization la somme des poids en valeur absolue multiplié par une constante α
- pour la L2-Regularization la somme des poids au carré multiplié par une constante α
Écrit sous forme mathématique :
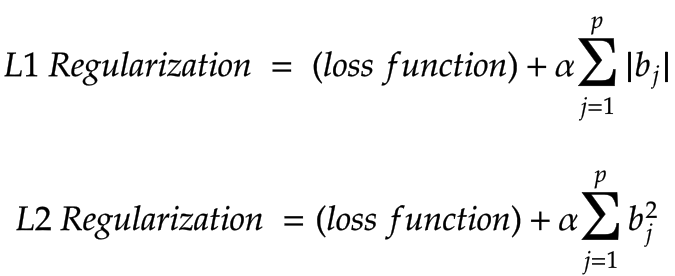
Laquelle utiliser et quand ?
Les avis différent selon la source : livre, kaggle, blog internet.
L’avantage des deux techniquement :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
- L1-Regularization permet d’effectuer une feature selection plus précise (trouver des sous-ensembles de données pertinents)
- L2-Regularization permet d’effectuer un apprentissage plus rapide
Mais pour être honnête, sur le plan pratique, les deux sont tout aussi puissant et fiable ! 🙂
Chez Inside Machine Learning, nous préférons avoir une approche pragmatique qui est plus adapté au Deep Learning. Testez sur votre dataset les deux Regularizations, celle qui vous minimise le plus l’overfitting et le temps de calcul sera la meilleure !

Comment utiliser la Regularization ?
Sur Keras & TensorFlow
Ici, on utilise la L2 Regularization, le processus est le même pour la L1.
L’approche par défaut est de simplement indiquer la régularisation à utiliser :
tf.keras.layers.Dense(32, kernel_regularizer='l2')Une autre approche consiste à indiquer la valeur des biais à utiliser :
tf.keras.layers.Dense(32, kernel_regularizer=l2(0.01), bias_regularizer=l2(0.01))Il y a 3 argument que l’on peut modifier (ou laisser par défaut) :
- kernel_regularizer : applique une pénalité sur le noyau de la couche.
- bias_regularizer : applique une pénalité sur le biais de la couche
- activity_regularizer : Rapplique une pénalité sur la sortie de la couche.
On peut même utiliser la régularisation L1 et L2 en même temps avec simplement :
tf.keras.layers.Dense(32, kernel_regularizer=l1_l2(l1=0.01, l2=0.01))Sur PyTorch
Avec PyTorch l’approche est similaire à l’équation vue plus haut.
On choisit la valeur de α puis on fait la somme des poids au carré :
l2_alpha = 0.001
l2_norm = sum(p.pow(2.0).sum() for p in model.parameters())Ensuite on ajoute ce biais après avoir calculer la loss function :
loss = loss + l2_alpha * l2_norm Voilà ! Vous avez vu comment appliquer une régularisation sur votre modèle.
À noter la Regularization s’applique uniquement de l’entraînement du modèle. Il n’est plus en marche lors de l’évaluation et l’utilisation du modèle.
C’est une méthode à ne pas confondre avec le Dropout qui lui aussi très utilisé mais qui ne s’applique pas de la même manière.
On en parle dans un article juste ici !
Photo by Erik-Jan Leusink on Unsplash
sources :
- L. Antiga, Deep Learning with PyTorch (2020, Manning Publications) – notre lien affilié
- Quora
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :