

Je vous propose aujourd’hui ce tutoriel de Preprocessing NLP pour voir en détail comment nettoyer ses données textes !
Si vous voulez télécharger directement le code, il est disponible sur Github à cet adresse.
On va voir plusieurs approches qui seront adaptable autant aux textes en anglais qu’aux textes en français.
Puis on verra comment encoder ces données en format compréhensible, interprétable par nos modèles de Machine Learning et Deep Learning.
C’est parti !

Preprocessing
Charger les données
Premièrement, comme à notre habitude, on va charger nos données.
Ici on prend un fichier csv tiré de cette compétition Kaggle contenant plusieurs milliers de phrases en anglais.
Parfait pour nous 😉
On charge les phrases depuis ce répertoire Github.
!git clone https://github.com/tkeldenich/NLP_Preprocessing.git &> /dev/nullPuis on insère ces données dans un Dataframe Pandas.
import numpy as np
import pandas as pd
train_data = pd.read_csv('/content/NLP_Preprocessing/train.csv')
train_data.head()
Nettoyer les données
Une fois que les données sont chargées il faut les nettoyer, faire ce qu’on appelle un preprocessing.
Dans la plupart des cas pour du NLP, le preprocessing consiste à enlever les caractères qui ne sont pas des lettres comme « # », « -« , « ! », les chiffres ou bien encore les mots qui n’ont pas de sens ou qui ne font pas partie de la langue analysée.
Garder en tête cependant que pour certains type de problèmes il peut être intéressant de préserver certains types de caractères.
Par exemple : pour analyser si un email est un spam ou non, on peut imaginer que les ‘!’ sont un bon indicateur et donc ne pas les enlever lors du nettoyage.
Nous allons ici coder deux fonctions :
- une pour nettoyer nos phrases en langue anglaise
- une pour nettoyer nos phrases en langue française
Ces deux fonctions ont, par ailleurs, la même architecture.
Texte en anglais
Premièrement on importe toutes les librairies nécessaires :
import nltk
import string
from nltk.stem import WordNetLemmatizer
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('words')
nltk.download('wordnet')Ensuite on initialise :
- les stopwords, ce sont les mots qui apparaissent très fréquemment mais qui n’apporte pas de sens à la phrase (comme « de », « le », « une »)
- les mots (words) qui proviennent d’un dictionnaire anglais (directement intégré à la librairie nltk)
- un lemmatizer, cette objet nous permet de préserver la racine des mots de tel sorte que deux mots ayant une même souche seront considérés comme un seul et même mot (exemple : ‘voisine’ et ‘voisinage’ seront tous deux changer en ‘voisin’)
stopwords = nltk.corpus.stopwords.words('english')
words = set(nltk.corpus.words.words())
lemmatizer = WordNetLemmatizer()Puis on construit notre fonction de preprocessing qui va successivement :
- enlever la ponctuation
- enlever les chiffres
- transformer les phrases en liste de tokens (en liste de mots)
- enlever les stopwords (mots n’apportant pas de sens)
- lemmatizer
- enlever les majuscules
- reformer les phrases avec les mots restants
def Preprocess_listofSentence(listofSentence):
preprocess_list = []
for sentence in listofSentence :
sentence_w_punct = "".join([i.lower() for i in sentence if i not in string.punctuation])
sentence_w_num = ''.join(i for i in sentence_w_punct if not i.isdigit())
tokenize_sentence = nltk.tokenize.word_tokenize(sentence_w_num)
words_w_stopwords = [i for i in tokenize_sentence if i not in stopwords]
words_lemmatize = (lemmatizer.lemmatize(w) for w in words_w_stopwords)
sentence_clean = ' '.join(w for w in words_lemmatize if w.lower() in words or not w.isalpha())
preprocess_list.append(sentence_clean)
return preprocess_list Puis on l’utilise :
preprocess_list = Preprocess_listofSentence(train_data['text'])Ensuite on peut afficher un exemple de phrase nettoyée :
print('Phrase de base : '+train_data['text'][2])
print('Phrase nettoyée : '+preprocess_list[2])- Phrase de base : 13,000 people receive #wildfires evacuation orders in California
- Phrase nettoyée : people receive wildfire evacuation order
Texte en français
Ici on va d’abord installer la librairie FrenchLefffLemmatizer qui permet d’effectuer une lemmatization en français.
!pip install git+https://github.com/ClaudeCoulombe/FrenchLefffLemmatizer.git &> /dev/nullOn importe ensuite les librairies.
import nltk
import string
from french_lefff_lemmatizer.french_lefff_lemmatizer import FrenchLefffLemmatizer
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('stopwords')Ensuite on initialise :
- les stopwords, ce sont les mots qui apparaissent très fréquemment mais qui n’apporte pas de sens à la phrase (comme « de », « le », « une »)
- les mots qui proviennent d’un dictionnaire français (un dictionnaire en .txt est disponible ici)
- un lemmatizer, cette objet nous permet de préserver la racine des mots de tel sorte que deux mots ayant une même souche seront considérés comme un même mot (exemple : ‘voisine’ et ‘voisinage’ seront tous deux changer en ‘voisin’)
french_stopwords = nltk.corpus.stopwords.words('french')
mots = set(line.strip() for line in open('/content/NLP_Preprocessing/dictionnaire.txt'))
lemmatizer = FrenchLefffLemmatizer()Puis on construit notre fonction de preprocessing qui va successivement :
- enlever la ponctuation
- enlever les chiffres
- transformer les phrases en liste de tokens (en liste de mots)
- enlever les stopwords (mots n’apportant pas de sens)
- lemmatizer
- garder seulement les mots présent dans le dictionnaire
- enlever les majuscules
- reformer les phrases avec les mots restant
def French_Preprocess_listofSentence(listofSentence):
preprocess_list = []
for sentence in listofSentence :
sentence_w_punct = "".join([i.lower() for i in sentence if i not in string.punctuation])
sentence_w_num = ''.join(i for i in sentence_w_punct if not i.isdigit())
tokenize_sentence = nltk.tokenize.word_tokenize(sentence_w_num)
words_w_stopwords = [i for i in tokenize_sentence if i not in french_stopwords]
words_lemmatize = (lemmatizer.lemmatize(w) for w in words_w_stopwords)
sentence_clean = ' '.join(w for w in words_lemmatize if w.lower() in mots or not w.isalpha())
preprocess_list.append(sentence_clean)
return preprocess_listOn crée des données pour tester notre fonction :
lst = ['C\'est un test pour lemmatizer',
'plusieurs phrases pour un nettoyage',
'eh voilà la troisième !']
french_text = pd.DataFrame(lst, columns =['text'])Ensuite on l’utilise :
french_preprocess_list = French_Preprocess_listofSentence(french_text['text'])Et on regarde le résultat :
print('Phrase de base : '+lst[1])
print('Phrase nettoyée : '+french_preprocess_list[1])- Phrase de base : plusieurs phrases pour un nettoyage
- Phrase nettoyée : plusieurs phrase nettoyage

Les différents encodages
Une fois qu’on a extrait les informations utiles de nos phrases, on peut passer à la phase d’encodage.
L’encodage est une étape essentielle pour pouvoir faire du Machine Learning.
En effet, il permet de transformer les données texte en chiffres que la machine peut interprérer, que la machine peut comprendre.
Il existe différents types d’encodage et nous allons dès maintenant aborder les plus connus !
One-Hot Encoding
Le One-Hot Encoding est à la fois la méthode la plus connu, la plus simple à réaliser, et celle qui m’a permis d’avoir la meilleure précision dans la plupart de mes travaux personnels en NLP.
Le One-Hot consite à créer un dictionnaire avec tous les mots qui apparaissent dans nos phrases nettoyées.
Ce dictionnaire est en fait un tableau où chaque colonne représente un mot et chaque ligne représente une phrase.
Si tel mot apparaît dans tel phrase, on met une valeur de 1 dans l’élément du tableau, sinon on met une valeur de 0.
On aura donc un tableau composé uniquement de 0 et de 1.
Pour réaliser le One-Hot Encoding en Python, on initialise le dictionnaire avec la fonction CountVectorizer() de la librairie Sklearn.
Puis on utilise la fonction fit_transform() sur nos données preprocessées.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(preprocess_list)X.toarray()[0]En fait la classe vectorizer garde beaucoup d’autres informations sur le dictionnaire.
En outre, si nous voulons encoder de nouvelles phrases pour utiliser notre modèle de Machine Learning entraîné il faudra utiliser la fonction fit() de la classe vectorizer.
On peut ainsi adapter ces nouvelles phrases à notre dictionnaire. Cela implique néanmoins que si ces nouvelles phrases contiennent un mot qui n’est pas dans le dictionnaire, il ne sera pas pris en compte.
On peut voir les mots composants ce dictionnaire avec la fonction get_feature_names() de vectorizer.
vectorizer.get_feature_names()Le seul inconvénient du One-Hot Encoding c’est que l’on perd la hiérarchie, l’ordre des mots.
Cela nous fait donc perdre le contexte, le sens de la phrase et en théorie cela devrait appauvrir les résultats de notre modèle.
En pratique, cela est bien différent, on peut avoir des résultats avec 80-85% de précision ce qui est déjà très intéressant pour du NLP !
Word embeddings
Encodage Hiérarchique
Ici on utilise un autre type d’encodage: l’encodage hiérarchique.
Contrairement au One-Hot Encoding, vous vous en doutez, on garde la hiérarchie, l’ordre des mots et donc le sens de la phrase.
On a un autre type de dictionnaire ici. En fait, chaque mot est représenté par un chiffre.
Chaque phrase sera donc une suite de chiffres.
Un exemple sera plus parlant :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
- « je joue au jeu vidéo » sera [1, 2, 3, 4, 5]
- « je regarde une vidéo » sera [1, 6, 7, 5]
Pour cet encodage on importe la bibliothèque zeugma. Si on est sur Google Colab on utilise la commande suivante :
!pip install zeugma &> /dev/nullSinon on exécute cette même commande, sans le « ! » du début, dans le terminal.
Ensuite, le fonctionnement est à peu près le même que pour le one-hot encoding : on utilise la fonction TextsToSequences() pour créer notre dictionnaire.
Puis on utilise la fonction fit_transform() sur nos phrases preprocessées.
from zeugma import TextsToSequences
sequencer = TextsToSequences()
embedded_sequ = sequencer.fit_transform(preprocess_list)Un exemple de phrase avec l’encodage hiérarchique :
embedded_sequ[0][95, 1, 135, 434, 874]
Une dernière chose à faire : normaliser nos données.
Ehh oui, pour utiliser du Machine Learning il faut que nos données soit en format tenseur.
Cela implique qu’il faut que toutes les phrases encodées aient la même taille.
Pour que nos phrases aient la même taille, on a ici deux choix:
- ajouter du ‘vide’ aux phrases les plus courtes
- tronquer les phrases les plus longues
Pour ces deux choix, une même fonction existe : sequence.pad_sequences()
Elle possède deux paramètres :
- sentences la liste de phrases à remplir/tronquer
- maxlen la longueur finale que chaque phrase aura
En fait cette fonction tronque les phrases ayant une longueur supérieur à maxlen et remplit de 0 les phrases ayant une longueur inférieur à maxlen.
from keras.preprocessing import sequence
max_len = 40
pad_sequ = sequence.pad_sequences(embedded_sequ, maxlen=max_len)On peut afficher une phrase encodée pour voir le résultat :
print(pad_sequ[0])[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 95 1 135 434 874]
Couche Embedding
En fait, l’encodage hiérarchique est un préalable pour utiliser la couche Embedding de Keras.
Cette couche permet de donner des coordonnées à tous les mots de notre dictionnaire tout en réalisant un apprentissage.
L’idée est que plus les mots ont un sens proche, plus les mots ont des coordonnées proches.
La couche va donc s’améliorer, comme toutes les autres couches, au cours de l’apprentissage. Ainsi à la fin de l’apprentissage, la couche aura donné des coordonnées précises pour chacun des mots.
La couche Embedding a trois paramètres:
- input_dim, le nombre de mots dans notre dictionnaire + 1
- output_dim, la dimension du tenseur de sortie
- input_length, la longueur des vecteurs (longueur des phrases normalisé)
longueur_dict = max(list(map(lambda x: max(x), pad_sequ)))+1from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(longueur_dict, 8, input_length = max_len))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))On pourra ensuite lancer l’entraînement avec la fonction fit() puis utiliser notre modèle !

Pour aller plus loin…
Word2Vec Embedding
Entraînement
Il existe différentes librairies pour faire de l’embedding.
Keras est particulièrement utile pour cette tâche car elle permet d’entraîner l’embedding en même temps que le modèle de Deep Learning.
La librairie Gensim est au moins aussi intéressante que Keras car elle nous permet de visualiser cet embedding.
C’est-à-dire qu’on va pouvoir analyser l’embedding en regardant quel mot est similaire à quel autre par exemple.
Pour cet embedding, il faut que nos données soient sous forme de tokens (chaque mot séparé) et non sous forme de phrases.
tokenize_sentences = []
for i in range(len(preprocess_list)):
tokenize_sentences.append(nltk.tokenize.word_tokenize(preprocess_list[i]))Ensuite, on utilise la fonction Word2Vec de la librairie Gensim.
Cette fonction possède cinq paramètres principaux :
- size : La dimension du vecteur créé, idéalement inférieur au nombre de mots du vocabulaire
- fenêtre : La distance maximale entre un mot cible et les mots autour du mot cible. La fenêtre par défaut est de 5.
- min_count : Le nombre minimum de mots à prendre en compte lors de l’apprentissage du modèle ; les mots dont l’occurrence est inférieure à ce nombre seront ignorés. La valeur par défaut de min_count est 5.
- worker : Le nombre de lots créés pour l’entraînement, par défaut il y en a 3.
Premièrement on initialise le Word2Vec, puis on l’entraîne sur nos données !
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
model_W2V = Word2Vec(sentences=tokenize_sentences, size=100, window=5, min_count=1, workers=4)
model_W2V.train(tokenize_sentences, total_examples=len(tokenize_sentences), epochs=50)Visualisation
Le modèle a appris la similarité des mots en fonction du contexte de nos phrases.
Le titre de notre jeu de données est ‘Disaster Tweet’ – ‘Les tweets parlant de catastrophes(naturelles ou non)’
On peut par exemple regarder quel mot se rapproche de ‘fire’ grâce à la fonction similar_by_word().
tokenize_sentences[0][1]model_W2V.similar_by_word(tokenize_sentences[0][1])[:5]Les cinq premiers sont ‘decomposition’, ‘township’, ‘racer’, ‘beast’ et ‘apartment’.
Cela veut dire que la plupart du temps, ‘fire’ à été utilisé au côté de ces mots.
Pour mieux visualiser cette similarité on peut utiliser la fonction suivante :
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
def display_closestwords_tsnescatterplot_perso(model, word):
arr = np.empty((0,100), dtype='f')
word_labels = [word]
numb_sim_words = 5
# get close words
close_words = model.similar_by_word(word)[:numb_sim_words]
# add the vector for each of the closest words to the array
arr = np.append(arr, np.array([model[word]]), axis=0)
for wrd_score in close_words:
wrd_vector = model[wrd_score[0]]
word_labels.append(wrd_score[0])
arr = np.append(arr, np.array([wrd_vector]), axis=0)
# find tsne coords for 2 dimensions
tsne = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = tsne.fit_transform(arr)
x_coords = Y[:, 0]
y_coords = Y[:, 1]
# color for words
color = ['red']
for i in range(numb_sim_words):
color.append('blue')
# display scatter plot
plt.scatter(x_coords, y_coords, c = color)
for label, x, y in zip(word_labels, x_coords, y_coords):
plt.annotate(label, xy=(x, y), xytext=(1, 5), textcoords='offset points')
plt.xlim(min(x_coords)-100, max(x_coords)+100)
plt.ylim(min(y_coords)-100, max(y_coords)+100)
plt.show()
print("Word most similar to : "+word)
print([sim_word[0] for sim_word in close_words])Et ensuite l’utiliser en précisant le modèle d’Embedding et le mot à analyser :
display_closestwords_tsnescatterplot_perso(model_W2V, tokenize_sentences[0][0])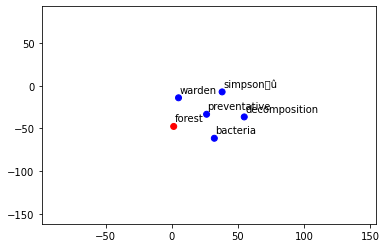
L’inconvénient de Word2vec c’est qu’il apprend le sens d’un mot uniquement en fonction des mots qui l’entourent, là où Keras apprend le sens des mots en fonction de l’objectif (y_train) fixé lors de l’apprentissage.
En fait, Word2Vec a une approche non-supervisée et Keras une approche supervisée.
Word2Vec Pré-entraîné par Google
Une autre approche consiste à prendre un Word2Vec déjà entraîné.
Google et Facebook propose le leur qui, vous l’imaginait bien, a été entraîné sur des millions (milliards ?) de données !
Idéal pour avoir une représentation générale du vocabulaire d’une langue.
À savoir cependant, les Word2Vec entraînés par Facebook, Google, ou autre ne peuvent pas être adaptés, entraînés sur nos phrases. On peut seulement les utiliser en gardant le contexte général sur lequel ils ont été entraîné.
On télécharge ici le Word2Vec entraîné par Google (1.5GB) (disponible sur ce lien si vous voulez le télécharger en local) :
!wget -q --show-progress --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=0B7XkCwpI5KDYNlNUTTlSS21pQmM' -O- | sed -rn 's/.confirm=([0-9A-Za-z_]+)./\1\n/p')&id=0B7XkCwpI5KDYNlNUTTlSS21pQmM" -O word2vec_pretrained.bin.gz && rm -rf /tmp/cookies.txtEnsuite on utilise la bibliothèque sh pour le dézipper.
!pip install sh &> /dev/nullOn le dézip :
from sh import gunzip
gunzip('/content/word2vec_pretrained.bin.gz')Puis on utilise la fonction load_word2vec_format() de la class KeyedVectors pour charger le Word2vec de Google.
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format('/content/word2vec_pretrained.bin', binary=True)On peut ensuite l’utiliser avec un modèle de Deep Learning..
Je vous propose ici d’explorer la représentation du modèle, les liens qu’il fait entre les mots …
On peut par exemple regarder les mots similaires à ‘koala’ on obtient ‘koalas’, ‘wombat’, ‘quoll’, ‘orang_utan’, ‘Koala’.
model.similar_by_word('koala')[:5]Ou comparer la similarité entre deux mots :
model.similarity('hotdog', 'hamburger')Ou encore utiliser notre fonction de tout à l’heure pour une visualisation plus concrète.
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
import numpy as np
def display_closestwords_tsnescatterplot(model, word):
arr = np.empty((0,300), dtype='f')
word_labels = [word]
numb_sim_words = 5
# get close words
close_words = model.similar_by_word(word)[:numb_sim_words]
# add the vector for each of the closest words to the array
arr = np.append(arr, np.array([model[word]]), axis=0)
for wrd_score in close_words:
wrd_vector = model[wrd_score[0]]
word_labels.append(wrd_score[0])
arr = np.append(arr, np.array([wrd_vector]), axis=0)
# find tsne coords for 2 dimensions
tsne = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = tsne.fit_transform(arr)
x_coords = Y[:, 0]
y_coords = Y[:, 1]
# color for words
color = ['red']
for i in range(numb_sim_words):
color.append('blue')
# display scatter plot
plt.scatter(x_coords, y_coords, c = color)
for label, x, y in zip(word_labels, x_coords, y_coords):
plt.annotate(label, xy=(x, y), xytext=(1, 5), textcoords='offset points')
plt.xlim(min(x_coords)-100, max(x_coords)+100)
plt.ylim(min(y_coords)-100, max(y_coords)+100)
plt.show()display_closestwords_tsnescatterplot(model, 'challenge')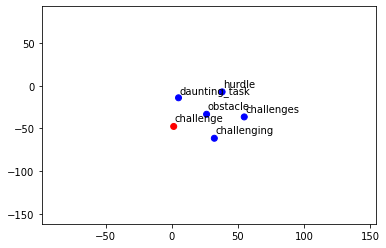
Avec ces connaissances, vous devriez avoir les outils en main pour entraîner vos propres modèles de NLP et améliorer vos modèles déjà entraînés.
Si vous voulez en savoir plus sur les modèles NLP de Machine Learning n’hésitez pas à voir nos autres articles sur le sujet !
Preprocessing NLP Preprocessing NLP Preprocessing NLP Preprocessing NLP Preprocessing NLP Preprocessing NLP
Photo by Colton Sturgeon on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



