Dans cet article, nous allons explorer les différents algorithmes de Deep Learning et découvrir leurs nuances.
En Deep Learning, il existe divers algorithmes permettant de résoudre des objectifs variés.
Néanmoins, il n’est pas facile de distinguer ces algorithmes de Deep Learning.
Alors qu’en Machine Learning traditionnels, les différents algorithmes sont facilement identifiables, ce n’est pas le cas en Deep Learning. Pour nous aider dans cette tâche, une propriété importante est à considérer.
Une fois avoir exploré cette propriété, nous comprendrons comment différencier les algorithmes de Deep Learning. Puis nous découvrirons les 5 algorithmes principaux du domaine.
Différencier les algorithmes de Deep Learning
Une propriété importante
Dans le Machine Learning traditionnel, lorsque le ML Engineer fait face à un problème, il doit sélectionner un algorithme approprié (arbre de décision, SVM, KNN, …). Ces algorithmes ont été développé préalablement par des experts et sont mis à disposition dans une bibliothèque de programmation.
Après avoir choisi un algorithme, le ML Engineer expérimente afin de déterminer les paramètres optimaux pour résoudre son problème.
Le ML Engineer sélectionne donc un algorithme qu’il doit, par la suite, optimiser.
Cependant, le Deep Learning fonctionne différemment. En effet, les bibliothèques ne proposent pas d’algorithmes prédéfinis.
L’approche consiste à construire manuellement des algorithmes. Pour cela, le ML Engineer dispose de couches qu’il peut combiner entre elles.
Un algorithme de Deep Learning, aussi appelé réseau de neurones, est un assemblage de couches.
Il existe de nombreuses couches produisant des effets divers. Un réseau de neurones peut en posséder des dizaines, voire des centaines. Ainsi, les possibilités de construction sont infinies.
Néanmoins, ces possibilités infinies impliquent que les algorithmes de Deep Learning n’ont pas de structures déterminées. Par conséquent, ils ne sont pas aussi clairement identifiables que les algorithmes de Machine Learning traditionnels.
En Deep Learning, le ML Engineer ne doit pas sélectionner un algorithme parmi une dizaine prédéfinie, mais construire manuellement un algorithme en sélectionnant des couches et en les combinant entre elles. Cela implique que les algorithmes de Deep Learning sont difficilement catégorisables.
Différencier les algorithmes de Deep Learning grâce aux couches
Malgré qu’il n’y ait pas d’algorithmes de Deep Learning prédéfinis, on peut tout de même les différencier grâce aux éléments qui les composent : les couches.
La couche en Deep Learning est l’élément principal permettant de construire un réseau de neurones.
Un réseau de neurones est un empilement de couches. Les couches contiennent des neurones qui transforment les données d’entrée en données de sortie. Les neurones n’étant pas au cœur de cet article, tu pourras trouver plus d’informations sur le sujet ici.
Les bibliothèques de Deep Learning mettent à disposition des couches prédéfinies que le ML Engineer peut sélectionner. Chaque couche produit un effet différent sur les données.
Par exemple, les couches de convolution sont spécialisées pour traiter des images. Ainsi, pour résoudre un projet de Computer Vision (Vision par Ordinateur), on utilisera un réseau de neurones composé principalement de couches de convolution.
Pour catégoriser les réseaux de neurones, on peut alors observer les couches principales qui les composent. Ainsi, les couches sont des éléments prédéfinis qui nous permettent de différencier les algorithmes de Deep Learning.
Réseaux de neurones artificiels – ANN
Un réseau de neurones artificiels est composé de couches linéaires.
Dans une couche linéaire, chaque neurone se connecte à tous les neurones de la couche précédente. Cela permet à l’information de se propager dans la totalité du réseau.
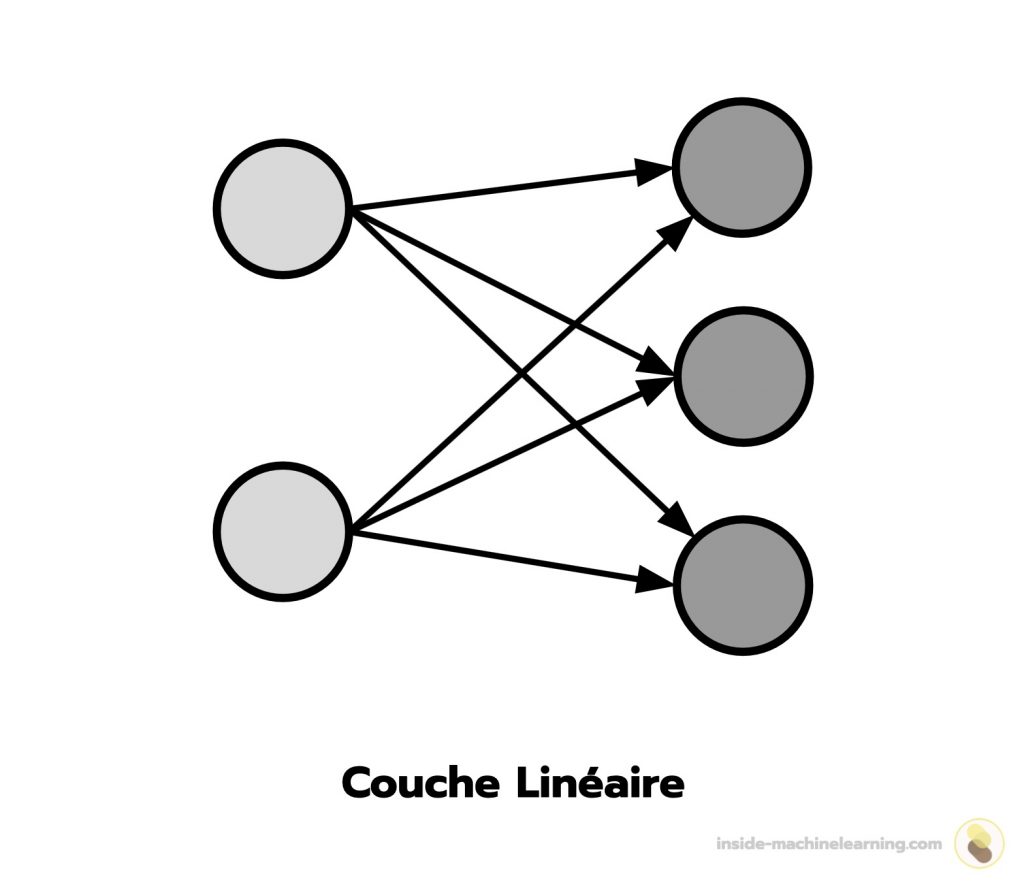
Le fonctionnement d’un réseau de neurones artificiels est inspiré du cerveau humain.
Dans le cerveau humain, lorsqu’une information est perçue, elle est envoyée aux neurones. Les neurones s’échangent alors successivement cette information pour la traiter. Grâce à ce traitement, le cerveau peut interpréter l’information et amorcer une réaction.
Par exemple, lorsque l’on écoute un chant d’oiseau, les oreilles transmettent cette information aux neurones du cerveau. Ensuite, les neurones se communiquent l’information pour la traiter. À la fin de ce processus, le cerveau comprend l’information et enclenche une réaction : pour la plupart des personnes, une sensation de tranquillité.
Dans un réseau de neurones artificiels, ce traitement de l’information permet aux algorithmes de Deep Learning d’atteindre des performances supérieures à la plupart des algorithmes traditionnels. On utilise les réseaux de neurones artificiels principalement pour les tâches de classification et de régression.
Les réseaux de neurones artificiels sont basés sur le fonctionnement du cerveau. Ils possèdent des couches linéaires permettant à l’information de se propager dans la totalité du réseau.
Remarque : on ajoute une fonction d’activation aux couches linéaires pour leur permettre d’effectuer des transformations non linéaires. Cette propriété est à la base des performances des algorithmes de Deep Learning. Tu trouveras plus d’informations sur le sujet dans cet article.
Réseaux de neurones à convolution – CNN
Un réseau de neurones à convolution est composé de couches de convolution.
Dans une couche de convolution, les neurones traitent l’information en la décomposant en sous-groupes. Cela permet aux couches d’extraire des caractéristiques pertinentes d’une donnée.
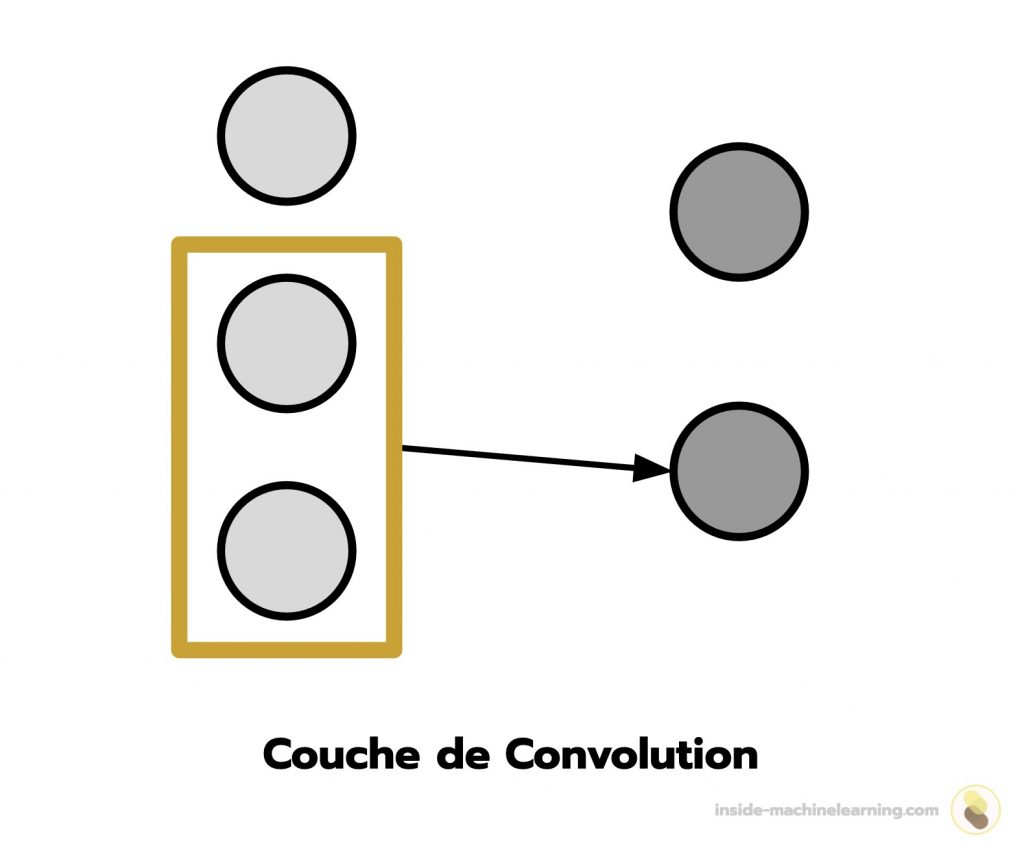
Le fonctionnement des couches de convolution est inspiré du système visuel des chats.
Pour analyser une information reçue par les yeux, le système visuel des chats n’analyse pas la totalité de l’information d’un coup. Au contraire, chaque neurone se concentre sur une petite zone pour permettre, par la suite, au système visuel de comprendre l’information globale.
Par exemple, lorsqu’un chat observe un oiseau, chaque neurone se concentre sur des détails spécifiques tels que les ailes, la tête, les pattes, etc. Combinées, ces informations permettent au système visuel du chat de former une perception complète de l’oiseau.
Dans un réseau de neurones à convolution, ce traitement de l’information permet d’améliorer grandement la compréhension des images et des vidéos. Ainsi, on utilise les réseaux de neurones à convolution principalement pour des tâches de Computer Vision (Vision par Ordinateur).
Les réseaux de neurones à convolution sont basés sur le système visuel des chats. Ces réseaux possèdent des couches de convolution permettant de traiter l’information en la décomposant en sous-groupes. Cette particularité se montre particulièrement efficace pour le traitement d’images et de vidéos.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Réseaux de neurones récurrent – RNN
Un réseau de neurones récurrents est composé de couches récurrentes.
Dans une couche récurrente, les neurones traitent les éléments d’une information de manière successive et accumulent les résultats. Cela permet aux neurones d’analyser des éléments nouveaux en se basant sur l’analyse des éléments précédents.
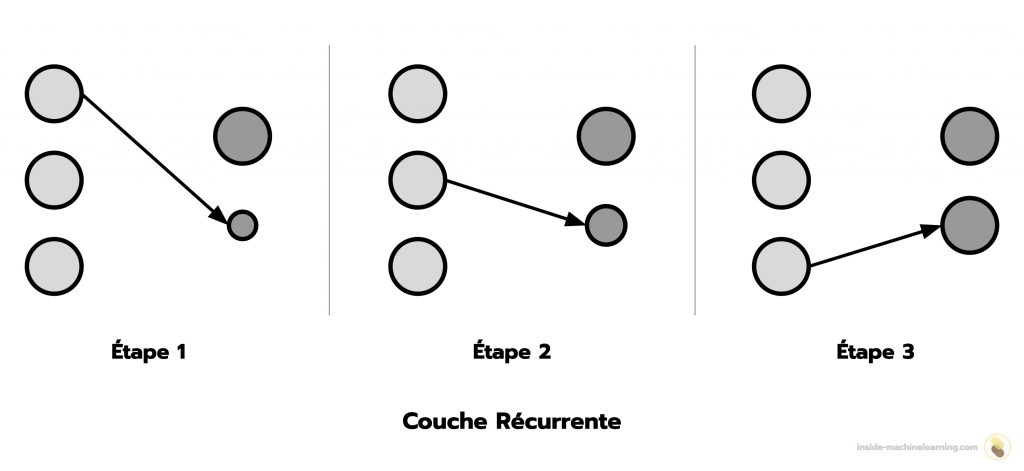
Le fonctionnement des couches récurrentes est inspiré de la mémoire.
La mémoire a la capacité d’enregistrer, de stocker et d’utiliser ultérieurement des informations. Grâce à ces capacités, nous pouvons non seulement apprendre des connaissances, mais également interpréter de nouvelles informations en nous basant sur celles stockées précédemment. Ainsi, le cerveau peut accumuler des connaissances et les réutiliser dans d’autres contextes.
Par exemple, lors de la lecture d’un roman policier, la mémoire enregistre et stocke les informations concernant les personnages, les événements et les intrigues. Au fur et à mesure que l’histoire avance, le cerveau analyse les nouvelles informations à la lumière des précédentes. Dans certains cas, cette accumulation d’informations peut nous permetrre de deviner, avant le dénouement final, l’identité du coupable.
Dans un réseau de neurones récurrents, ce traitement de l’information permet d’améliorer grandement le traitement de texte et, en général, des données séquentielles. Ainsi, on utilise les réseaux de neurones récurrents principalement pour des tâches de Natural Language Processing (Traitement du langage naturel).
Les réseaux de neurones récurrents sont basés sur le fonctionnement de la mémoire. Ces réseaux possèdent des couches récurrentes permettant de traiter les éléments d’une information de manière successive et d’accumuler les résultats. Cette particularité se montre particulièrement efficace pour le traitement de texte.
Réseaux antagonistes génératifs – GAN
Un réseau antagoniste génératif est l’assemblage de deux réseaux : le générateur composé de couches de déconvolution et le discriminateur composé de couches de convolution.
Dans une couche de déconvolution, les neurones traitent les éléments d’une information en augmentant leur taille. Cela permet aux neurones de générer de l’information.
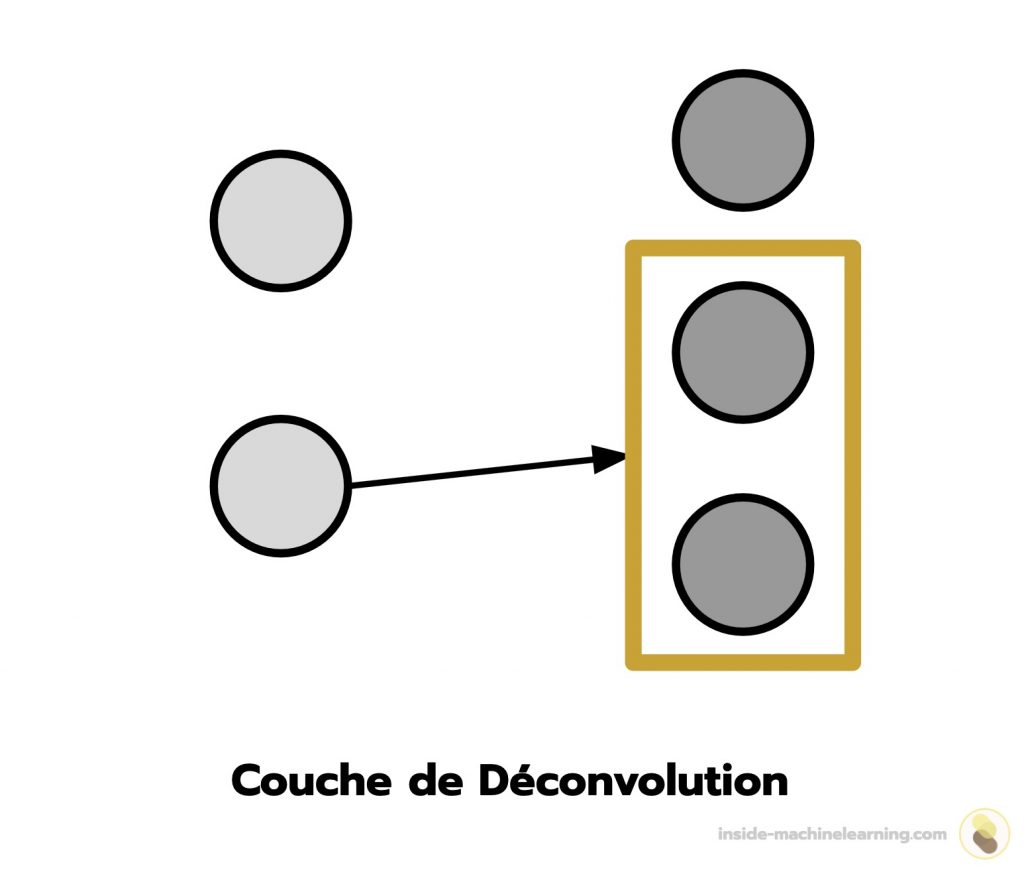
Remarque : se référer aux réseaux de neurones à convolution pour l’explication des couches de déconvolution.
Le générateur peut être considéré comme un faussaire essayant de produire de la fausse monnaie et de l’utiliser sans être détecté.
Le discriminateur peut, quant à lui, être considéré comme un policier essayant de détecter la fausse monnaie.
L’objectif du générateur est de duper le discriminateur et l’objectif du discriminateur est de détecter les contrefaçons parmi des articles authentiques et des articles artificiellement générés.
Le générateur et le discriminateur sont donc en concurrence, ce qui les pousse à s’améliorer mutuellement. Lorsque les contrefaçons deviennent indiscernables des articles authentiques, on considère le résultat satisfaisant.
Dans un réseau antagoniste génératif, cette approche permet d’améliorer grandement la génération d’informations, en général d’images mais également de textes. Ainsi, on utilise les réseaux antagonistes génératifs dans des tâches de Computer Vision et de NLP.
Les réseaux antagonistes génératifs utilisent une approche faussaire-policier. Le générateur imite des articles que le discriminateur doit détecter parmi un groupe d’articles. Cette approche se montre particulièrement efficace pour la génération d’images et de textes.
Transformeurs
Un transformeur est composé de couches de l’attention.
Dans une couche de l’attention, les neurones attribuent des niveaux d’importance aux différents éléments d’entrée, en fonction de leur pertinence. Cela permet de focaliser l’attention de la couche sur les parties les plus significatives de l’information.
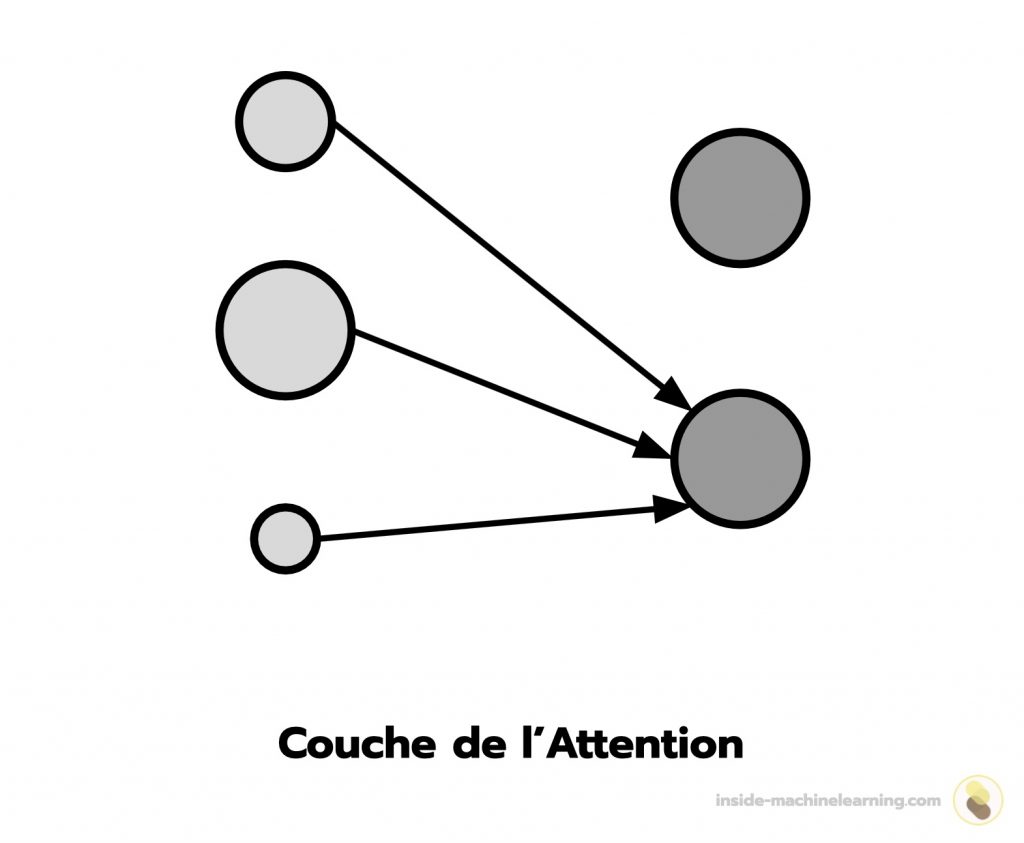
Le fonctionnement des couches de l’attention est inspiré par le mécanisme de l’attention sélective.
L’attention sélective est la capacité du cerveau humain à accorder un niveau de pertinence aux stimuli qu’il reçoit. Ce mécanisme lui permet de se concentrer sur les informations importantes tout en filtrant les stimuli non pertinents ou distrayants.
Par exemple, lors d’une discussion dans un café animé, alors que les bruits de conversations, de vaisselle et de musique s’entremêlent, une personne peut diriger son attention sélective vers la voix de son ami qui se trouve à proximité. Son cerveau filtre les autres voix et sons environnants, les reléguant à un niveau de pertinence plus bas, afin de se concentrer sur la conversation qui l’intéresse. Cette capacité d’attention sélective permet à l’individu de se concentrer sur la voix de son ami tout en éliminant les distractions superflues, facilitant ainsi la communication et la compréhension dans un environnement stimulant.
Dans un transformeur, ce mécanisme permet d’améliorer grandement le traitement de l’information, que ce soit pour les images ou les textes. Ainsi, les transformeurs sont utilisés en Computer Vision et en NLP, aussi bien pour des tâches de classification et de régression que pour des tâches de génération.
Les transformeurs utilisent une approche basée sur le fonctionnement de l’attention sélective. Grâce à cela, les neurones peuvent accorder un niveau d’importance aux éléments d’une information. Cela améliore grandement le traitement de tout type de données : images, textes, et bien d’autres.
Conclusion – Algorithmes de Deep Learning
Créer des catégories pour les algorithmes de Deep Learning se révèle plus ardu que pour les algorithmes de Machine Learning traditionnels. En effet, les réseaux de neurones sont construits manuellement par le ML Engineer. Ainsi le nombre de variations de structures d’algorithmes est potentiellement infini.
Néanmoins, on peut tout de même différencier les algorithmes de Deep Learning par les couches principales qui les composent. Voici les différents algorithmes de Deep Learning majeurs :
- Réseaux de neurones artificiels
- Réseaux de neurones à convolution
- Réseaux de neurones récurrents
- Réseaux antagonistes génératifs
- Transformeur
Maintenant, si tu veux continuer à approfondir tes connaissances dans le domaine du Deep Learning, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources :
- Pubmed – The effect of different types of music on patients’ preoperative anxiety: A randomized controlled trial
- Wikipedia – Convolutional Neural Network
- Wikipedia – Hopfield Network
- Arxiv – Generative Adversarial Networks – Ian J. Goodfellow & al.
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :