
Dans cet article, nous allons voir en détail ce qu’est une fonction d’activation et son utilité dans un modèle de Deep Learning !
Précédement, nous avons exploré les concepts fondamentaux du Deep Learning : couche, neurone et poids.
Ainsi, nous avons pu découvrir qu’un modèle de Deep Learning ne fonctionne pas tout à fait comme le cerveau humain.
Effectivement, ce mythe, malheureusement trop répandu, est inexact.
Le traitement de l’information – Cerveau humain vs Deep Learning
Pour prédire un événement, nous, humain, analysons des données, puis seulement après, réalisons une prédiction. Cette approche s’effectue en deux temps : analyse-prédiction.
Par exemple, si l’on souhaite essayer de prédire le résultat d’un match de Roland Garros, on regarderait les résultats des matchs précédents, puis on se projetterait dans l’avenir pour essayer de prédire un gagnant.
Tu conviendras que cette approche n’est pas des plus scientifiques. Elle ne nous assure pas une prédiction de qualité. C’est une faille du cerveau humain. Il n’est pas fiable à 100%. Mais c’est cette même faille qui nous permet d’être pris au dépourvu quand le machiavélique Joffrey Barathéon se fait empoisonner lors de son mariage. Une situation difficilement prévisible pour notre cerveau… mais c’est cela qui la rendue jouissive. Si ce petit défaut nous permet d’apprécier Game of Thrones, on ne va pas s’en plaindre !
Un modèle de Deep Learning emploie une approche différente. Il ingère des données et les transforme pour produire un résultat.
Pour reprendre l’exemple de Roland Garros, un modèle de Deep Learning n’analyserait pas les statistiques des matchs précédents pour, ensuite, réaliser une prédiction. Au lieu de cela, il prendrait les statistiques et leur appliquerait des transformations successives pour obtenir un résultat. Un modèle de Deep Learning utilise donc une approche en un seul temps : la « forward propagation » (en français la « propagation en avant »).
La forward propagation est le processus de propagation et de transformation des données à travers un réseau de neurones.
Dans l’article d’aujourd’hui, nous allons nous pencher sur l’une des composantes essentielles de cette forward propagation : la fonction d’activation. Nous allons explorer la théorie des fonctions d’activation, leur application en programmation et les opérations mathématiques sous-jacentes.
Qu’est-ce qu’une fonction d’activation ?
Le processus de forward propagation permet à un réseau de neurones de produire un résultat à partir de données.
Avant la production du résultat, les données passent à travers le modèle. Chaque neurone reçoit alors les données et leur applique une transformation. Cette succession de transformations permet de produire un résultat.
La transformation évoquée est une opération mathématique réalisée par un neurone grâce à sa fonction d’activation et son poids.
La fonction d’activation est l’attribut du neurone lui permettant de transformer une donnée.
Elle joue un rôle central dans un réseau de neurones car elle permet d’appliquer une transformation non linéaire.
La non-linéarité est un concept mathématique. Si ton but est simplement de pratiquer le Deep Learning, tu n’auras pas besoin de l’approfondir. Cependant, comprendre son impact est important, car il est la source des performances des algorithmes de Deep Learning.
Non-linéarité et représentation spatiale
Une transformation non-linéaire modifie la représentation spatiale des données.
Cette transformation nous donne la capacité d’explorer les données sous différentes perspectives et ainsi, de mieux les comprendre.
À l’inverse, une transformation linéaire permet, certes, de modifier les données, mais n’a pas d’influence sur leur représentation spatiale.
Pour illustrer cela, imaginons que nous ayons deux valeurs : 13 et 54. Ces valeurs ont une représentation spatiale : 13 est inférieur à 54. Si nous appliquons une opération linéaire, par exemple une multiplication par 2, la valeur de ces données sera alors modifiée. Néanmoins, leur position spatiale restera inchangée : 13x2 = 26 sera toujours inférieur à 54x2 = 108.
Les transformations linéaires n’ont donc pas d’impact sur la représentation spatiale des données. Mais les transformations non linéaires en ont un.
Si nous appliquons une opération non linéaire à 13 et 54, par exemple la fonction cosinus, cela modifiera la valeur des données, mais également leur position spatiale : cos(13) ≈ 0.90 est supérieur à cos(54) ≈ -0.82.
Pour affiner notre compréhension des données, il faudra alors utiliser une transformation non linéaire.
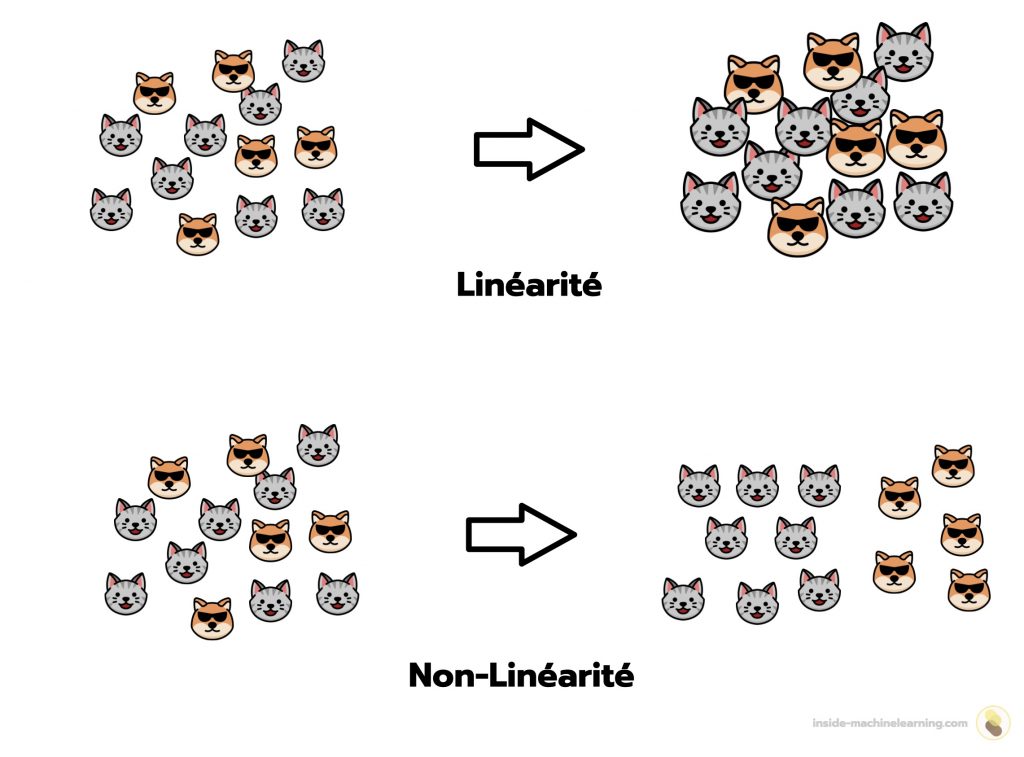
Cette propriété des fonctions non linéaires est un atout majeur, c’est pourquoi les réseaux de neurones l’exploitent par l’intermédiaire des fonctions d’activation. Les réseaux de neurones peuvent ainsi extraire des informations pertinentes d’un ensemble de données lors de forward propagation afin de produire des prédictions de qualité !
La non-linéarité est une des caractéristiques qui différencie les algorithmes de Deep Learning des algorithmes de Machine Learning traditionnels – tu trouveras plus d’informations sur le sujet dans cet article.
La place de la fonction d’activation dans un modèle de Deep Learning
Comme mentionné précédemment, chaque neurone possède une fonction d’activation et un poids. Cependant, alors que les poids sont attribués de manière aléatoire à tous les neurones, la fonction d’activation, quant à elle, est choisie manuellement par le ML Engineer.
Un modèle peut être composé de milliers de neurones, voire plus. Par conséquent, le ML Engineer n’attribuera pas une fonction d’activation individuellement à chacun des neurones. Cela prendrait un temps considérable !
Au lieu de cela, la fonction d’activation est sélectionnée par le ML Engineer lors de l’ajout d’une couche au modèle. Ensuite, la fonction d’activation est distribuée automatiquement aux neurones de cette couche.
Ainsi, les neurones d’une même couche partage la même fonction d’activation.
En pratique
Avec Keras, lorsqu’on ajoute une couche Dense, on peut également indiquer une fonction d’activation :
model.add(layers.Dense(32, activation='sigmoid'))Ici, la fonction d’activation choisie est la fonction sigmoïde. Elle sera associée aux 32 neurones de la couche.
Keras est conçu pour faciliter l’utilisation du Deep Learning, donc on peut appeler la fonction sigmoïde avec une simple chaîne de caractères 'sigmoid'. Cependant, il est important de noter qu’elle peut également être appelée sous forme de fonction :
tf.keras.activations.sigmoid(x)Cette pratique est généralement utilisée dans les bibliothèques de bas niveau, telles que TensorFlow et PyTorch, conçues pour les personnes ayant une pratique approfondie du Deep Learning. Mais on peut également le faire avec Keras.
De plus, il est important de souligner que les fonctions d’activation ne sont pas uniquement des attributs de couches de Deep Learning. Ce sont également des fonctions, à part entière, qui permettent de modifier une donnée en dehors de l’utilisation d’algorithmes de Deep Learning.
Pour faire du Deep Learning, il existe plusieurs fonctions d’activation. Il est primordial de les connaître et de savoir les sélectionner. En effet, si tu choisis une fonction d’activation inappropriée, tu peux saboter la totalité d’un modèle. Et crois-moi, tu ne veux pas que ton réseau de neurones finisse comme Joffrey Barathéon.
Avant de passer à la section centrée sur les mathématiques, si tu apprécies ma pédagogie, tu peux approfondir le Deep Learning avec moi dans mes e-mails privés.
En plus de ma newsletter mensuelle, tu as la possibilité de suivre mon nouveau Plan d’action pour Maîtriser les Réseaux de neurones. Si tu veux en savoir plus – clique ici :
Les différentes fonctions d’activation
Pour clarifier davantage cette section, lors de l’explication de l’utilisation des fonctions d’activation avec Keras, j’utiliserai l’appel sous forme de fonction.
En mathématiques, une quantité indénombrable de fonctions non linéaires existe. Néanmoins, seulement une petite fraction d’entre elles est utilisée comme fonction d’activation en Deep Learning.
La différence entre ces fonctions d’activation peut parfois sembler négligeable, cependant, certaines de ces fonctions doivent être choisies avec précision si l’on souhaite créer un réseau de neurones fonctionnel.
ReLU
La fonction Rectified Linear Unit (ReLU) est la fonction d’activation la plus couramment utilisée en Deep Learning.
Elle donne x si x est supérieur à 0, 0 sinon. Autrement dit, c’est le maximum entre x et 0 :
fonction_ReLU(x) = max(x, 0)
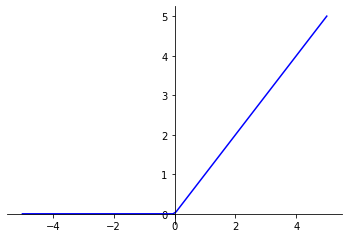
Cette fonction permet d’appliquer un filtre en sortie de couche. Elle laisse passer les valeurs positives dans les couches suivantes et bloque les valeurs négatives. Ce filtre permet alors au modèle de se concentrer uniquement sur certaines caractéristiques des données, les autres étant éliminées.
Comment utiliser la fonction ReLU avec Keras :
tf.keras.activations.relu(x, alpha=0.0, max_value=None, threshold=0)x: donnée d’entrée, tenseurmax_value: permet de fixer une valeur maximale pour les sorties de la fonction ReLU. Simax_valueest défini sur une valeur réelle, toutes les valeurs de sortie supérieures àmax_valueseront remplacées parmax_value. Cela permet de limiter la plage des valeurs de sortie de la fonctionthreshold: permet de définir un seuil (threshold) pour les entrées. Par défaut, ce seuil est fixé à 0, ce qui signifie que toutes les entrées négatives sont mises à zéro. Cependant, ce seuil peut être modifié selon les besoins du ML Engineer
Sigmoid
La fonction Sigmoïde est la fonction d’activation utilisée en dernière couche d’un réseau de neurones construit pour effectuer une tâche de classification binaire.
Elle donne une valeur entre 0 et 1.
fonction_Sigmoid(x) = 1 / (1 + exp(-x))
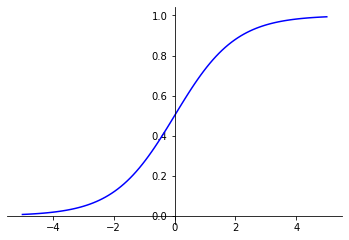
Cette valeur peut être interprétée comme une probabilité. Dans une classification binaire, la fonction d’activation sigmoïde permet alors d’obtenir, pour une donnée, la probabilité d’appartenir à une classe.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Je l’ai notamment utilisée dans mon projet de classification de critiques de cinéma. Dans cet exemple, plus le résultat de la sigmoïde est proche de 1, plus le modèle considère que la critique est positive. Inversement, plus le résultat de la sigmoïde est proche de 0, plus le modèle considère que la critique est négative.
La fonction d’activation sigmoïde permet donc d’obtenir un résultat ambivalent, donnant une indication sur deux classes à la fois.
Comment utiliser la fonction Sigmoïde avec Keras :
tf.keras.activations.sigmoid(x)Softmax
La fonction Softmax est la fonction d’activation utilisée en dernière couche d’un réseau de neurones construit pour effectuer une tâche de classification multi-classes.
Pour chaque sortie, Softmax donne un résultat entre 0 et 1. De plus, si l’on additionne ces sorties entre elles, le résultat donne 1.
fonction_Softmax(x) = exp(x) / tf.reduce_sum(exp(x))
fonction_Softmax(x) = exp(x) / sum(exp(xi))
Comme pour la fonction Sigmoïde, les valeurs résultantes de l’utilisation de la fonction Softmax peuvent être interprétées comme des probabilités. Dans ce cas, chacune de ces valeurs est associée à une classe du dataset.
Il est important de noter que nous n’aurions pas pu utiliser la fonction Sigmoïde en dernière couche d’un réseau de neurones pour une tâche de classification multi-classes. Elle donnerait bien, pour chaque élément, une valeur entre 0 et 1, mais ces éléments additionnés pourraient ne pas être égaux à 1. Ainsi, le résultat ne respecterait pas les lois de probabilité et serait donc fallacieux.
En revanche, la fonction Softmax, grâce à sa caractéristique de produire des résultats qui, additionnés, donnent 1, respecte les lois de probabilité. Elle est donc le noyau dur d’un réseau de neurones construit pour effectuer une tâche de classification multi-classes.
Comment utiliser la fonction Softmax avec Keras :
tf.keras.activations.softmax(x)Softplus
La fonction Softplus est une approximation « lisse » (en anglais « soft ») de la fonction ReLU.
Lorsque les valeurs d’entrée sont positives, la fonction Softplus se comporte, à quelques exceptions près, de la même manière que ReLU. Toutefois, pour des valeurs d’entrée négatives, la fonction Softplus n’applique pas de filtre comme ReLU, mais les fait tendre vers zéro.
fonction_Softplus(x) = log(exp(x) + 1)
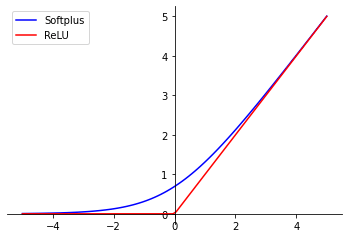
Cette courbe asymptotique permet d’obtenir des gradients plus stables lors de la backpropagation ce qui peut améliorer l’entraînement du modèle.
Comment utiliser la fonction Softplus avec Keras :
tf.keras.activations.softplus(x)Softsign
La fonction Softsign permet d’appliquer une normalisation aux valeurs d’entrée.
Elle permet d’obtenir des valeurs de sortie entre -1 et 1.
fonction_Softsign(x) = x / (abs(x) + 1)
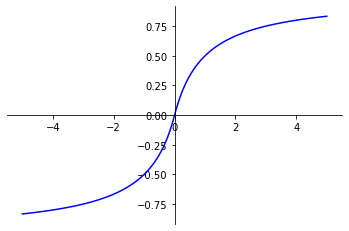
La fonction Softsign permet également de préserver le signe (positif ou négatif) des valeurs d’entrée. Une propriété qui peut s’avérer utile dans certaines tâches, mais dont l’utilisation reste peu commune.
Comment utiliser la fonction Softsign avec Keras :
tf.keras.activations.softsign(x)tanh
La fonction tanh permet d’appliquer une normalisation aux valeurs d’entrée. Elle peut également être utilisée au lieu de la fonction Sigmoïde dans la dernière couche d’un modèle de classification binaire.
Elle donne un résultat entre -1 et 1.
fonction_tanh(x) = sinh(x)/cosh(x)
fonction_tanh(x) = ((exp(x) – exp(-x))/(exp(x) + exp(-x)))
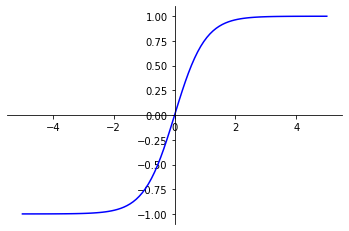
Lors d’une classification binaire, on ne peut pas directement interpréter le résultat obtenu après utilisation de la fonction tanh comme une probabilité car le résultat se situera entre -1 et 1. On pourra alors le modifier pour l’observer de la même manière qu’une probabilité.
Comment utiliser la fonction tanh avec Keras :
tf.keras.activations.tanh(x)ELU
La fonction Exponential Linear Unit (ELU) est une déclinaison de la fonction ReLU.
ELU se comporte de la même manière que ReLU pour des valeurs d’entrée positives. Cependant, pour des valeurs d’entrée négatives, ELU donne des valeurs lisses inférieures à 0.
fonction_ELU(x) =
if x > 0: xif x < 0: alpha * (exp(x) - 1)
avec :
alpha > 0
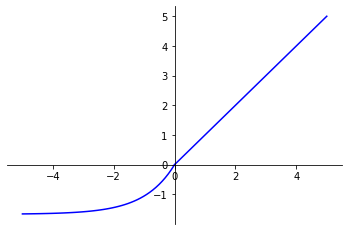
La fonction d’activation ELU a montré des résultats prometteurs dans diverses applications du Deep Learning. Cette alternative lissée à la fonction ReLU pallie certaines de ses limitations tout en conservant ses propriétés bénéfiques pour l’entraînement des réseaux de neurones.
Comment utiliser la fonction ELU avec Keras :
tf.keras.activations.elu(x, alpha=1.0)alpha: une variable, qui permet de contrôler la pente de ELU lorsque x < 0. Plus alpha est grand, plus la courbe est pentue. Cette valeur doit est supérieur à 0
SELU
La fonction Scaled Exponential Linear Unit (SELU) est une amélioration de ELU.
SELU multiplie une variable scale au résultat de la fonction ELU. Cette opération a été conçue pour favoriser la normalisation des valeurs de sortie.
fonction_SELU(x) =
if x > 0: return scale * xif x < 0: return scale * alpha * (exp(x) - 1)
avec comme constante :
alpha = 1.67326324scale = 1.05070098
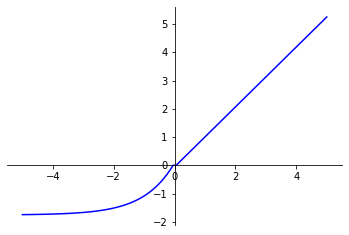
Comme ELU, SELU pallie certaines des limitations de ReLU tout en conservant ses propriétés bénéfiques pour l’entraînement des réseaux de neurones.
Comment utiliser la fonction ELU avec Keras :
tf.keras.activations.selu(x)Remarque : Lors de l’utilisation de SELU, il faut initialiser les poids des couches avec 'lecun_normal'.
model.add(tf.keras.layers.Dense(64, kernel_initializer='lecun_normal', activation='selu'))Fonctions d’activation personnalisées
Dans un travail de recherche ou d’expérimentation, il se peut que les fonctions d’activation prédéfinies dans les bibliothèques Python ne répondent pas à tes besoins. Par exemple, si les fonctions d’activation que tu sélectionnes ne produisent pas le résultat attendu, ou encore, si tu souhaites appliquer des transformations non linéaires spécifiques.
Dans ce cas, il est possible de créer tes propres fonctions d’activation. Il faudra alors garder à l’esprit deux règles :
- Une fonction d’activation doit être non linéaire
- Une fonction d’activation prend en entrée un tenseur
Note : Les bibliothèques Python classiques mettent à disposition des fonctions applicables sur des nombres réels. Par exemple, dans math.exp(x), x est un nombre réel. Mais pour créer une fonction d’activation, il faudra utiliser des fonctions applicables sur des tenseurs. Par exemple, dans tensorflow.math.exp(x), x est un tenseur.
Comment créer une fonction d’activation avec Keras :
from keras import backend as K
def maFonction(x, beta=1.0):
return x * K.sigmoid(beta * x)Comment utiliser une fonction d’activation personnalisée avec Keras :
from keras.layers.core import Activation
model.add(layers.Dense(16))
model.add(Activation(maFonction))Remarque : une fonction d’activation peut être ajoutée à un modèle, indépendamment de l’utilisation d’une couche, comme dans le code ci-dessus. Elle s’appliquera alors à la sortie de chaque neurone de la couche précédente.
Attention : Si tu sauvegardes un modèle utilisant une fonction d’activation personnalisée, pour le réutiliser dans un autre programme, il faudra que tu redéfinisses cette même fonction d’activation !
Conclusion
Les fonctions d’activation jouent un rôle crucial dans un réseau de neurones. En appliquant une transformation non linéaire aux données qui traversent le modèle, elles permettent de modifier leur représentation spatiale.
C’est cette particularité des fonctions d’activation qui confère aux algorithmes de Deep Learning leur puissance. Ainsi, dans de nombreux cas, les réseaux de neurones ont une performance supérieure aux algorithmes de Machine Learning traditionnels.
Plusieurs fonctions d’activation existent. Il est important de savoir les différencier car elles n’appliquent pas les mêmes transformations aux données. Par conséquent, si tu utilises une fonction d’activation inadaptée à la tâche à laquelle tu fais face, cela peut réduire en cendres les performances de ton modèle.
Pour que tu ne tombes pas dans le panneau, j’ai préparé un tableau clarifiant les fonctions d’activation à choisir en fonction du type de tâche auquel tu fais face ainsi qu’un récapitulatif de cet article. Pour y accéder clique ici :
Crédit photos : Ashim D’Silva on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :




Bonjour,
je suis un débutant en data science
Merci pour ce cours. C’est très édifiant. Pourquoi est-ce si compliqué d’avoir une fonction d’activation pour la régression vers des valeurs arbitraires?
Ne peut-on pas utiliser la fonction sigmoïde
pour cette régression ?
A quoi ça sert une régression vers des valeurs aléatoires ?
Bonjour Samuel,
Dans la dernière couche d’un réseau de neurones, la fonction d’activation est liée à l’objectif du problème.
Admettons que tu veuille classifier l’image d’un animal. Le problème : Est-ce un cheval ?
Ici on est dans un cas de classification Binaire (soit c’est un cheval, soit c’est autre chose).
La fonction d’activation sigmoïde est parfaite pour nous car elle limite le résultat à une valeur entre 0 et 1 (c’est à dire une probabilité, 0 correspondant à 0% et 1 correspondant à 100%). Le résultat sera donc une probabilité que l’animal sur l’image soit un cheval.
Par contre, admettons qu’on veuille prédire le prix d’un appartement dans un quartier de Paris. Dans ce cas, on ne veut pas une probabilité. En fait, on ne veut pas non plus que notre résultat soit limité entre 0 et 1 ou même 0 et 10.
Ce qu’on veut c’est un résultat qui est potentiellement très élevé, illimité. On est donc dans un problème de Régression.
Pour la régression, on ne veut donc pas limiter le résultat, l’output. Alors on ajoute notre couche de neurones sans indiquer de fonction d’activation, pour ne pas fixer de seuil à notre résultat.
Par exemple, avec Keras on peut prendre comme dernière couche :
model.add(tf.keras.layers.Dense(1))
Bonne journée,
Tom
Merci Tom. Je comprends mieux maintenant.
Bonjour ,
Merci pour votre cours
j’ai une question un peu technique, je suis entrain de tester différents processus de data augmentation, particulièrement un GAN. lors de la phase d’apprentissage de l’agent Generateur, je désire lui fournir un tensor avec des valeurs entières appartenant à un certain interval. Le Generateur est formé de 2 couches cachées avec la fonction d’activation ReLU.
lorsque j’utilise torch.randn, cela fonctionne très bien mais le résultat (fake data) est composé par des float. Avec torch.randint, python m’indique une erreur au niveau du tensor fournit à la phase d’apprentissage. Avez vous une idée sur la cause de ce problème? Merci pour votre réponse.
voici le lien drive où vous pouvez trouver le code et erreur générée par python
https://drive.google.com/drive/folders/1rXwpags8v0uE7BQmsdKOkz_N3-h7SXRX?usp=sharing:
Bonjour Hajer,
Si je comprends bien ton erreur est « Expected object of scalar type Float but got scalar type Long »
Il attend de toi des float et tu lui donnes des Long (des entier).
torch.randn fonctionne
torch.randint ne fonctionne pas
As-tu essayé de transformer tes int en float ?
Tu peux le faire avec la fonction `.float()`
Par exemple : torch.randint(20,100,(batch_size, 7)).float()
De cette manière tu garderas la valeur de tes int tout en les transformant en float
Essaye et tiens moi au courant,
Tom
Bonjour Tom,
Je vous remercie pour cet article d’une grande qualité. J’ai à présent une vision plus claire de toutes les fonctions d’activation.
Pouvez vous m’expliquer la différence entre : La Classification multiclasse à label unique et la Classification multiclasse, multilabel svp ?
Bonne journée
Dalila
Hello Dalila,
Prenons des exemples concrets :
– Si tu veux prédire la météo à Paris et que tu as 3 choix : beau temps, pluie, neige; c’est ici une classification multiclasse à label unique. Effectivement tu as plusieurs classes (beau temps, pluie, neige) et un label ‘météo à Paris’
– Maintenant si tu veux prédire la météo dans plusieurs villes : Paris, Bordeaux, Lille. On est sur une classification multiclasse et multilabel. Tes labels étant ‘météo à Paris’, ‘météo à Bordeaux’, ‘météo à Lille’
Du coup, on comprend facilement qu’une classification binaire est une classification à deux classes et un label.
Tu peux en apprendre plus sur le sujet dans cet article !
Et si tu veux en savoir davantage n’hésite pas à t’abonner à notre newsletter 😉
Bonne journée,
Tom