

Qu’est-ce que le Machine Learning ? Comment il fonctionne ? Dans quels domaines est-il appliqué ? Découvrez tout dans cet article !
Le Machine Learning est un domaine majeur des l’informatique et des mathématique. Plus précisément c’est une sous-catégorie de l’Intelligence Artificielle. Il consiste à créer des algorithmes pouvant apprendre de manière autonome à réaliser n’importe quel type de tâches. En fait le Machine Learning permet à un algorithme de comprendre des données, d’en extraire des règles et des patterns pour atteindre un objectif.
Le Machine Learning peut interpréter n’importe quel type de données, le seul pré-requis est de les convertir numériquement. Ainsi un algorithme de Machine Learning peut intéragir avec des chiffres, du texte, des images, des vidéos, des audios, etc.
Le Machine Learning c’est donc l’apprentissage automatique par un algorithme à réaliser une tâche à partir de données.
Rentrons plus dans le détail !
4 étapes pour faire du Machine Learning
Pour développer un algorithme de Machine Learning il faudra suivre 4 étapes essentielles.
- Préparer ton dataset
- Choisir un algorithme de Machine Learning
- Entraîner ton algorithme
- Tester & améliorer
Dataset
La première étape est de préparer ton dataset. Effectivement, dans la plupart des cas un dataset n’est pas prêt à être utiliser directement. Un fichier excel par exemple peut contenir des cases vides, des erreurs ou même des informations obsolètes. Il faudra donc le corriger et le nettoyer.
Tu utilisera ensuite ces données pour entraîner ton algorithme de Machine Learning. Ainsi plus elles seront précises plus l’algorithme sera performant. À l’inverse, si les données contiennent des informations erronées, le modèle sera biaisé ce qui aura impact direct sur le résultat de ton algorithme de Machine Learning.
Algorithme
La deuxième étape est de choisir ton algorithme de Machine Learning. Les plus connus et utilisés sont au nombre de dix et il faudra les sélectionner en fonction de plusieurs critères:
- Le type de données
- La quantité de données
- Le problème à résoudre
La troisième étape est d’entraîner ton algorithme à résoudre une tâche. Pour cela, il va apprendre plusieurs fois à effectuer cette action sur le même dataset.
Il va émettre des résultats et les comparer avec le résultats attendu et c’est ainsi qu’il va comprendre de manière autonome comment s’améliorer. Ainsi l’algorithme extrait des règles et des patterns lui permettant de mieux interagir avec ces données et finalement produire un résultat optimal !
Une fois que l’algorithme à un résultat satisfaisant (entre 80 et 100% de réussite), il est entraîné et on peut passer à la dernière étape.
La quatrième et dernière étape est d’utiliser l’algorithme de Machine Learning. Il faudra l’utiliser sur des données du monde réel et analyser ses résultats. Ainsi l’intervention d’un expert est essentielle. Il pourra déterminer si l’entraînement a été bien effectué et si les résultats sont adéquat.
Il est possible que l’algorithme nécessite d’être améliorer. Dans ce cas trois options s’offre à toi :
- changer les paramètres du modèle
- ajouter de nouvelles données
- modifier les paramètres d’entraînement
Quels sont les différentes techniques de Machine Learning ?
Dans la section précédente, on a vu qu’il fallait choisir son algorithme de Machine Learning en fonction du type de données dont on dispose. Effectivement, nos données vont grandement influencé l’algorithme que l’on va utiliser pour résoudre notre tâche mais surtout cela déterminera la technique de Machine Learning utilisée.
Il existe trois techniques de Machine Learning :
- supervisé
- non-supervisé
- par renforcement
Le plus largement utilisé étant l’apprentissage supervisé car il est à la fois le plus simple et le plus robuste.
Apprentissage Supervisé
Dans l’apprentissage supervisé, l’algorithme de Machine Learning apprend sur des données labellisées, c’est-à-dire, des données annotées avec le résultat censé atteindre. Avec cette configuration, l’algorithme peut faire des hypothèses puis les tester et les comparer avec le résultat attendu.
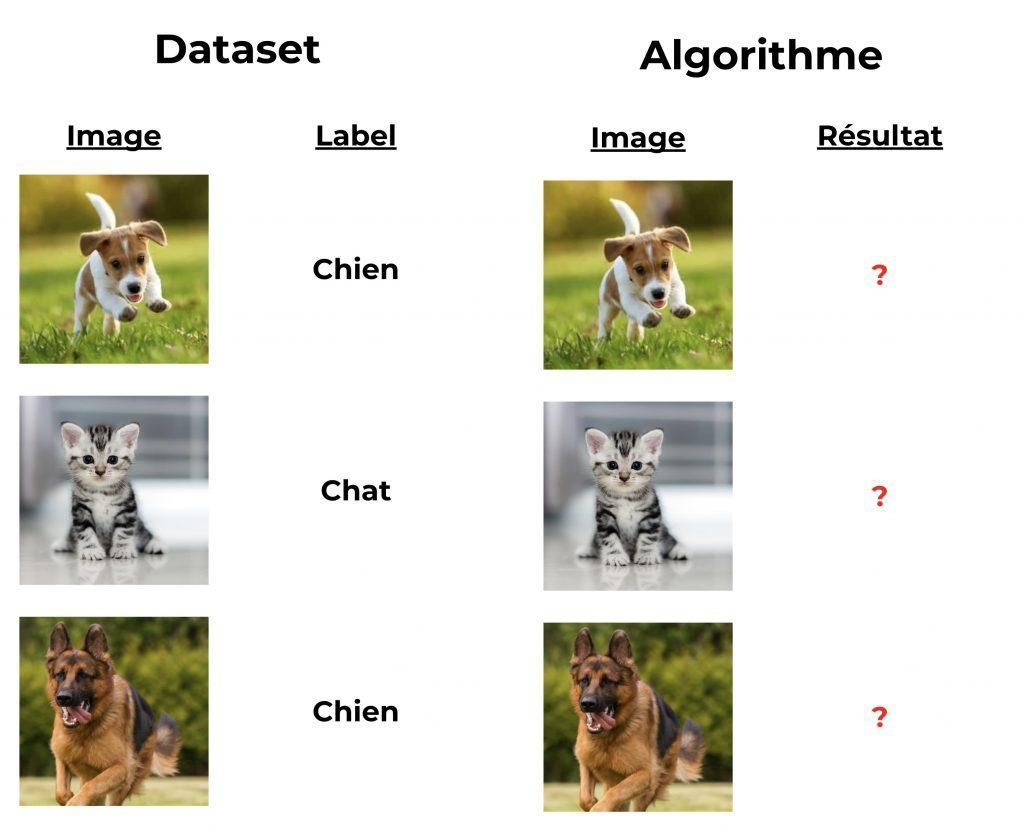
Tu l’auras compris, cette technique nécessite au préalable de labelliser ton dataset. C’est un processus coûteux en temps et en argent car seul un humain peut réaliser cette tâche… pour le moment.
De nombreux application d’aides à la labellisation (aussi appelé annotation) se développent de plus en plus et permettent aux annotateurs de labelliser plus rapidement et plus précisément tout types de données (chiffres, textes, images).
Un algorithme de Machine Learning peut aussi être biaisé à cause des données d’apprentissage. Effectivement, si les données du dataset ne sont pas assez variées, cela peut créer des biais d’apprentissage qui impacteront les performances de l’algorithme lors du traitement de nouvelles données.
Apprentissage Non-supervisé
C’est l’inverse pour l’apprentissage non-supervisé. Les données n’ont pas de labels. Ici l’algorithme est dans une approche expérimentale. Il explore les données et tente de repérer de son propre chef les règles et patterns du dataset.
Il existe deux cas d’utilisation de l’apprentissage non-supervisé :
- L’annotation est impossible
- L’annotation est trop coûteuse (temps et argent)
Souvent on utilise cette technique pour différencier un type de données d’un autre. C’est ce qu’à fait l’équipe de Yann Le Cun, pionnier de l’IA et chercheur chez Meta AI Research (anciennement Facebook AI Research), en créant l’algorithme DINO. L’algorithme DINO a appris par apprentissage non-supervisé à séparer dans une image l’objet principal de l’arrière-plan.
Je vous laisse juger par vous-même du résultat :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.

Ajoutons qu’il existe aussi l’apprentissage semi-supervisé qui est un compromis entre les deux apprentissages. Dans cette approche, on labellise seulement une petite partie des données d’entraînement. Ce sous ensemble de données va guider l’apprentissage de l’algorithme su le reste des données. Ainsi il va pouvoir extraire les règles et patterns dont il a besoin pour atteindre son objectif. Cette approche est un bon compromis pour un projet coûteux et qui nécessite l’annotation préalable des données. Effectivement, cette option permet de réduire les coûts en annotant qu’une partie, petite mais diversifiée, du dataset.
Apprentissage par Renforcement
La troisième technique est l’apprentissage par renforcement. Il consiste à laisser l’algorithme apprendre de ses erreurs. Il va donc teste et expérimenter plusieurs approches avant de trouver celle qui convient le mieux pour réaliser sa tâche.
Effectivement, pour le renforcement, on plonge l’algorithme dans un environnement où il recevra des récompenses et des pénalités en fonction de ses actions. Son objectif étant de maximiser ses récompenses, il va tout faire pour aller dans ce sens et trouver la bonne manière de le faire.
C’est ainsi qu’en 2017 une IA a été capable de battre le champion de jeu de GO (un jeu de plateau), une première à l’époque !
Mais de nos jours, les IA ont dépassées la maîtrise des jeux en 2D et sont aujourd’hui capable de comprendre et d’interagir de manière autonome avec un univers en 3D. On peut le voir ci-dessous dans un jeu où les personnages bleus doivent éviter d’être vue par les personnages rouges :

Qu’est-ce que le Deep Learning ?
Le Deep Learning est une sous-catégorie du Machine Learning mais c’est surtout celle qui suscite le plus d’intérêt aujourd’hui. Les avancées en Intelligence Artificielle se font en grande majorité grâce au Deep Learning, en français : apprentissage profond.
Le Deep Learning, c’est une version plus complexe et plus technique du Machine Learning. Il se fait par la création d’algorithme de zéro tandis que le Machine Learning utilise des algorithmes pré-existants.
La structure complexe du Deep Learning lui confère une plus grande habilité à extraire les règles et patterns qui sous-tendent les données.
En fait, un algorithme de Deep Learning est composés de neurones. Le plus petit peut en contenir quelques dizaines, quand le plus grand peut en contenir des millions !
Lors de l’entraînement d’un tel algorithme, chaque neurones est mis-à-jour et aura un objectif défini dans la résolution de la tâche.
En fait les algorithmes de Deep Learning s’inspirent directement du fonctionnement du cerveau humain. Les neurones y sont interconnectés et transmettent des informations aux neurones suivant pour les interpréter.
Cette habilité à résoudre des tâches ne vient pas seul car il faudra supporté ce type de calcul couteux en puissance et énergie. Je te recommande donc d’être équipé d’un bon processeur graphique (GPU) pour entraîner un grand réseau de neurones.
Mais alors dans quel cas le Deep Learning s’utilise ?
Le Deep Learning s’utilise pour des projets complexes qui nécessitent une compréhension profonde des données.
Pour classifier des données d’un tableau excel un algorithme classique de Machine Learning suffira. Mais si tu veux détecter des objets dans une vidéo, il te faudra ici un bon algorithme de Deep Learning.
Vous utilisez déjà du Machine Learning sans le savoir
Le Machine Learning au quotidien
De nos jours l’avancé de l’intelligence artificielle est indéniable et le débat philosophique sur « Est-ce possible de créer une IA consciente ? » vient d’être dépasser aujourd’hui même (15 juin 2022) par la question « Est-ce que Google a déjà créé une IA consciente ? » (VanityFair).
Mais sans parler de recherches interne aux entreprises, quelles sont ces IA qu’on utilise au quotidien sans le savoir ?
Sûrement les plus démocratisées sont les IA de recommandations qui sont les reines des fils d’actualités sur Facebook, Instagram, … mais aussi des recommandations de musique sur Spotify ou de vidéo sur TikTok, YouTube, Netflix.
Combien d’entre nous, nous sommes déjà fait aspiré pendant 10, 30 minutes voir même 1 heure par le fil d’actualité de nos réseaux sociaux ?
En moyenne un utilisateur TikTok passe 52 minutes chaque jour sur l’application !
Mais alors comment ces entreprises arrivent à créer des IA si puissantes ?
Tout simplement car ce sont des puits à données.
Effectivement ces apps enregistrent la moindre de tes réactions (like, commentaire, …) pour mieux comprendre ce que tu aimes et surtout ce qui te fait rester sur la plateforme.
Cette base de données énorme crée un dataset idéal pour entraîner une IA !
Pour aller plus loin
On peut aussi noter l’emergence des assistants vocals comme Google, Siri ou Alexa. Ces technologies reposent sur la Reconnaissance Vocal qui est une catégorie importante du Machine Learning. On peut aussi citer les voitures autonomes qui se développent de plus en plus au fil des années. Ici on parle de Computer Vision une autre catégorie du Machine Learning.
Pour finir, la Data Science et en général l’analyse de données est une partie intégrante du Machine Learning. Avec un dataset répertoriant les informations d’une entreprise on peut prédire les résultats qu’elle fera d’une année à l’autre.
Ce travail nécessite toujours l’intervention d’un humain pour exécuter les modèles et interpréter les résultats mais l’Intelligence Artificielle Forte pourrait arriver plus vite que prévu…
Si tu veux commencer à apprendre le Machine Learning n’hésite pas à consulter notre section sur les bases du Machine Learning !
À bientôt sur Inside Machine Learning 😉
sources :
- OpenAI – Emergent Tool Use from Multi-Agent Interaction
- Meta AI – DINO and PAWS
- VaniyFair – Un employé de Google suspendu pour avoir affirmé qu’une intelligence artificielle est « consciente »
- Wallaroom – TikTok Statistics
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



