Dans cet article, on vous propose un tutoriel pour visualiser l’Embedding de phrases (sentences embedding); aussi appelé TSNE appliqué au NLP.
Pour ça, on utilise le Dataset GoEmotions de Google qui contient plus de 58 000 phrases labellisées selon 27 emotions. Pour chaque phrase UNE seule émotion est associée, c’est donc un problème de classification Multiclasses…
… mais vous pouvez évidemment adapter ce tutoriel à n’importe quelle type de classification !
Encore un point avant de commencer,
L’Embedding est la représentation sous forme informatique d’une phrase. Il est utilisé pour faire comprendre le langage de l’Homme à la Machine.
Pour visualiser l’Embedding de phrases, il faut avant tout créer cette Embedding.
Ce tutoriel aura donc 3 parties :
Préparer les Données – GoEmotions
Préalable : On vous recommande d’utiliser un ordinateur possédant GPU ou bien de coder sur Google Colab est d’y activer gratuitement le GPU intégré.
Pour commencer ce tutoriel, on charge l’entièreté du dataset GoEmotions grâce à l’API Google. Cet dataset est décomposée en 3 fichiers csv :
!wget -P data/full_dataset/ https://storage.googleapis.com/gresearch/goemotions/data/full_dataset/goemotions_1.csv &> /dev/null
!wget -P data/full_dataset/ https://storage.googleapis.com/gresearch/goemotions/data/full_dataset/goemotions_2.csv &> /dev/null
!wget -P data/full_dataset/ https://storage.googleapis.com/gresearch/goemotions/data/full_dataset/goemotions_3.csv &> /dev/nullEnsuite, on crée un dataframe Pandas qui va contenir ces 3 fichiers csv. On retire les colonnes que nous n’allons pas utiliser puis on supprime les phrases qui apparaissent plus qu’une fois dans le dataset :
import numpy as np
import pandas as pd
df1 = pd.read_csv('/content/data/full_dataset/goemotions_1.csv')
df2 = pd.read_csv('/content/data/full_dataset/goemotions_2.csv')
df3 = pd.read_csv('/content/data/full_dataset/goemotions_3.csv')
df = pd.concat([df1, df2, df3], sort=False)
df.drop(['id', 'link_id','parent_id','created_utc','rater_id','example_very_unclear'], axis=1, inplace=True)
df.drop_duplicates(subset=['text', 'author', 'subreddit'], inplace=True)
df.reset_index(inplace=True, drop=True)Après ce rapide traitement, on peut examiner notre dataset :
len(df)Sortie : 58009
On a un dataset de 58 009 phrases, on peut afficher les premières lignes pour voir plus en détails ces données :
df.head(1)
On voit que le Dataframe est assez illisible. En plus de cela, il y encore quelques colonnes qui ne vont pas nous être utile comme celle contenant le nom de l’auteur.
Au fait, ce dataset est tiré du forum en ligne Reddit, vous pouvez y trouvez toutes sortes de phrases… assez farfelues… vous êtes prévenu !
On va créer un deuxième dataframe, qui sera celui qu’on utilisera vraiment durant ce tutoriel :
df_analysis = df[['text']]⬆ On ajoute les phrases à ce nouveau dataframe.
Puis, on veut aussi avoir les émotions associées à chacune de ces phrases.
Le problème c’est qu’elle sont encodés sous forme de chiffres : 1 si l’émotion est présente, 0 si elle ne l’est pas.
Je vous propose de simplifier tout ça grâce à cette ligne de code :
df_analysis['text_emotion'] = df.drop(columns=['text','author','subreddit'], axis=1, inplace=False).idxmax(axis=1)On affiche le dataframe résultant :
df_analysis.head(1)
C’est beaucoup plus clair ! On a ici un dataframe contenant 2 colonnes : une pour les phrases, une pour l’émotion associée.
Encore une dernière étape car…
… en créant un Embedding, on fait en réalité du Deep Learning. Ce modèle de DL va apprendre sur nos données et en fonction de la puissance de votre GPU, cela peut prendre du temps.
Pour accélérer l’apprentissage, je vous propose de réduire le nombre de données. On se concentrera uniquement sur 7 émotions associées à 1000 phrases chacune :
df_analysis = pd.concat([df_analysis[df_analysis['text_emotion'] == 'joy'].iloc[:1000],
df_analysis[df_analysis['text_emotion'] == 'sadness'].iloc[:1000],
df_analysis[df_analysis['text_emotion'] == 'curiosity'].iloc[:1000],
df_analysis[df_analysis['text_emotion'] == 'neutral'].iloc[:1000],
df_analysis[df_analysis['text_emotion'] == 'love'].iloc[:1000],
df_analysis[df_analysis['text_emotion'] == 'amusement'].iloc[:1000],
df_analysis[df_analysis['text_emotion'] == 'embarrassment'].iloc[:1000]
])Les 27 émotions répertoriées sont : admiration, amusement, colère, agacement, approbation, bienveillance, confusion, curiosité, désir, déception, désapprobation, dégoût, embarras, excitation, peur, gratitude, chagrin, joie, amour, nervosité, optimisme, fierté, réalisation, soulagement, remords, tristesse, surprise, neutre.
N’hésitez pas à choisir parmi celles qui vous intrigue… les résultats finaux sont particulièrement intéressant !
Transfer Learning – BERT
Importer Bert
Comme je vous l’ai dit plus haut, dans ce tutoriel on utilise du Deep Learning. Et comme le dataset est particulièrement complexe on va utiliser le fameux modèle BERT.
En fait, on va faire du Transfer Learning. C’est à dire qu’on va utiliser une version BERT qui a déjà était entraîné.
Ainsi on va s’approprier les performances qu’il a déjà obtenues, puis l’adapter (l’entraîner à nouveau) sur nos données !
C’est ce qu’on appelle le Transfer Learning.
On a déjà aborder le Transfer Learning avec BERT dans cet article, c’est pourquoi on va passer rapidement sur ce sujet pour se diriger vers le cœur de ce tutoriel !
On charge BERT :
import tensorflow_hub as hub
module_url = "https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1"
bert_layer = hub.KerasLayer(module_url, trainable=True)Puis on installe les dépendances :
!pip install sentencepiece &> /dev/null
!pip install bert-tensorflow &> /dev/nullEt le code pour traiter nos données :
import tokenization
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ModelCheckpoint
# The 4 next lines allows to prevent an error due to Bert version
import sys
from absl import flags
sys.argv=['preserve_unused_tokens=False']
flags.FLAGS(sys.argv)
def bert_encode(texts, tokenizer, max_len=512):
all_tokens = []
all_masks = []
all_segments = []
for text in texts:
text = tokenizer.tokenize(text)
text = text[:max_len-2]
input_sequence = ["[CLS]"] + text + ["[SEP]"]
pad_len = max_len - len(input_sequence)
tokens = tokenizer.convert_tokens_to_ids(input_sequence)
tokens += [0] * pad_len
pad_masks = [1] * len(input_sequence) + [0] * pad_len
segment_ids = [0] * max_len
all_tokens.append(tokens)
all_masks.append(pad_masks)
all_segments.append(segment_ids)
return np.array(all_tokens), np.array(all_masks), np.array(all_segments)
vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
tokenizer = tokenization.FullTokenizer(vocab_file, do_lower_case)
train_input = bert_encode(df_analysis.text.values, tokenizer, max_len=100)
train_labels = df_analysis.text_emotion.valuesClassification Multiclasses avec Bert
Encore une fois, tout le code que vous voyez ici est détaillé ici, n’hésitez pas à consulter l’article si vous voulez comprendre comment utiliser BERT.
J’attire néanmoins votre attention sur la partie ci-dessous qui est différente du tutoriel sur BERT, notamment les 3 lignes avec :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
- « flatten »
- « output_flatten »
- « out »
def build_model(bert_layer, max_len=512):
input_word_ids = layers.Input(shape=(max_len,), dtype=tf.int32, name="input_word_ids")
input_mask = layers.Input(shape=(max_len,), dtype=tf.int32, name="input_mask")
segment_ids = layers.Input(shape=(max_len,), dtype=tf.int32, name="segment_ids")
_, sequence_output = bert_layer([input_word_ids, input_mask, segment_ids])
clf_output = sequence_output[:, 0, :]
flatten = layers.Flatten(name='flatten')
output_flatten = flatten(clf_output)
out = layers.Dense(len(np.unique(train_labels)), activation='sigmoid')(output_flatten)
model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=out)
model.compile(Adam(lr=2e-6), loss='binary_crossentropy', metrics=['accuracy'])
return model
model = build_model(bert_layer, max_len=100)À la ligne « flatten », on définit en fait la couche d’Embedding. C’est elle qui va traduire la phrase en langage informatique.
Notre objectif est donc d’entraîner le modèle pour qu’il optimise la couche d’Embedding et ainsi qu’on puisse avoir une bonne représentation des données.
Si on n’entraînait pas le modèle, il ferait toujours cette Embedding mais sans relier les phrases aux émotions.
En s’entraînant le modèle modifie chacune de ses couches. Une fois les couches sont modifiées et optimisées, il peut comprendre à partir d’une phrase, l’émotion qui lui est relié.
Donc en apprenant, il optimise son Embedding. D’ailleurs vous pouvez essayer de votre côté et voir que si le modèle est mal entraîner, la Visualisation de l’Embedding ne donnera rien d’intéressant.
Parenthèse fermées ! Le résultat sera à la fin de cet article 🔥
À la ligne « output_flatten », on utilise la couche d’embedding précédemment créée.
Et enfin, la couche « out », où au lieu d’avoir Dense(2, …) on a Dense(len(np.unique(train_labels)) …).
En fait ce chiffre indique le nombre de sortie du modèle. On utilisait 2 pour une Classification Binaire.
Ici on a une Classification Multiclasses. Si vous choisissez d’analyser tout le dataset (les 27 émotions) vous pouvez directement indiquer 27.
Mais vu que ce nombre dépend de la puissance de notre GPU, on a décidé d’opter pour une solution adaptative avec len(np.unique(train_labels)).
Cette solution mesure le nombre d’émotions contenu dans votre dataset. On a 7 émotions alors ce code indique automatiquement « 7 ». Ainsi, pas besoin de changer ce bout de code s’il on ajoute ou enlève des émotions à notre dataframe !
En parlant de ces émotions… il nous faut aussi les traduire en langage informatiques.
Vu que ce sont des données catégoriques, c’est beaucoup plus simple, notamment grâce à la fonction get_dummies() :
label_dummy = pd.get_dummies(train_labels)N’hésitez pas à afficher le résultat pour comprendre les transformations qu’on applique à chaque instant :
label_dummy.head(2)
Finalement, on peut entraîner notre modèle et c’est là que notre GPU va montrer son utilité :
train_history = model.fit(
train_input, label_dummy,
validation_split=0.2,
epochs=10,
batch_size=32
)Presque 30 minutes d’apprentissage de mon côté ! Je vous conseille au passage de vérifier la précision finale de votre modèle.
Plus elle est haute, plus la Visualisation de l’Embedding sera efficace !
D’ailleurs, on va ENFIN pouvoir passer à…
TSNE – Visualisation d’Embedding de phrases
Extraire l’Embedding
Comme je vous l’ai dit précédemment, on veut extraire le résultat de la couche d’Embedding.
Pour cela on récrée un modèle à partir de l’ancien en comprenant toutes ses couches jusqu’à « flatten », la couche d’Embedding :
intermediate_layer_model = Model(inputs=model.input,
outputs=model.get_layer('flatten').output)Puis on envoie nos données dans ce nouveau modèle pour avoir ce résultat qui nous intéresse tant !
sentence_embedded = intermediate_layer_model.predict(train_input)Ça y est ! On a notre Embedding de phrases.
Maintenant, on récupère les émotions associées à chacune de ces phrases :
labels_emotion = df_analysis.text_emotionOn peut ici vérifier les dimensions de l’embedding…
sentence_embedded.shape.. et celle des émotions :
labels_emotion.shapeDe mon côté j’ai (6433, 768) et (6433,).
Donc 6433 phrases pour 6433 émotions, ça match !
(Ne devrait-on pas avoir 7000 phrases ? – En fait, dans notre dataset, chacune des émotions est associé à un nombre de phrases différents. On peut donc imaginer que certaines sont reliées à moins de 1000 phrases. Cela ne pose aucun problème pour notre algorithme, on continue !)
Pour visualiser l’Embedding, il faut projeter les phrases sur un axes à 2 (ou 3) dimensions.
Ici on en a une dimension de (, 768). C’est beaucoup trop ! Et c’est là que le TSNE intervient.
Le TSNE c’est un algorithme permettant de réduire la dimension d’un array (matrice) tout en préservant les informations importantes contenues à l’intérieur.
On peut l’utiliser via la librairie sklearn… et pour les curieux, oui c’est un algorithme de Machine Learning. Il utilise notamment les KNN.
Mais trêve de théorie ! C’est la pratique qui nous intéresse dans ce tutoriel :
import numpy as np
from sklearn.manifold import TSNE
X = list(sentence_embedded)
X_embedded = TSNE(n_components=2).fit_transform(X)On a donc réduit la dimension de notre Embedding.
Maintenant, pour organiser tout ça, on va créer un dataframe contenant l’Embedding 2D des phrases et leurs émotions :
df_embeddings = pd.DataFrame(X_embedded)
df_embeddings = df_embeddings.rename(columns={0:'x',1:'y'})
df_embeddings = df_embeddings.assign(label=df_analysis.text_emotion.values)On va aussi ajouter les phrases de bases non modifiés, pour rendre la visualisation plus facile :
df_embeddings = df_embeddings.assign(text=df_analysis.text.values)Si vous êtes arrivés à cet étape, bravo ! C’est un long tutoriel qui n’est pas évident, mais il permet d’avoir un résultat particulièrement intéressant.
Affichons le sans plus tarder !
Afficher l’Embedding
Pour ça, on utilise Plotly. On lui indique le dataframe à afficher, les colonnes à prendre comme axes, la colonnes à prendre comme label et finalement le hover_data permet d’associé chacun des points projetés à leur phrases respectives :
import plotly.express as px
fig = px.scatter(
df_embeddings, x='x', y='y',
color='label', labels={'color': 'label'}
hover_data=['text'], title = 'GoEmotions Embedding Visualization')
fig.show()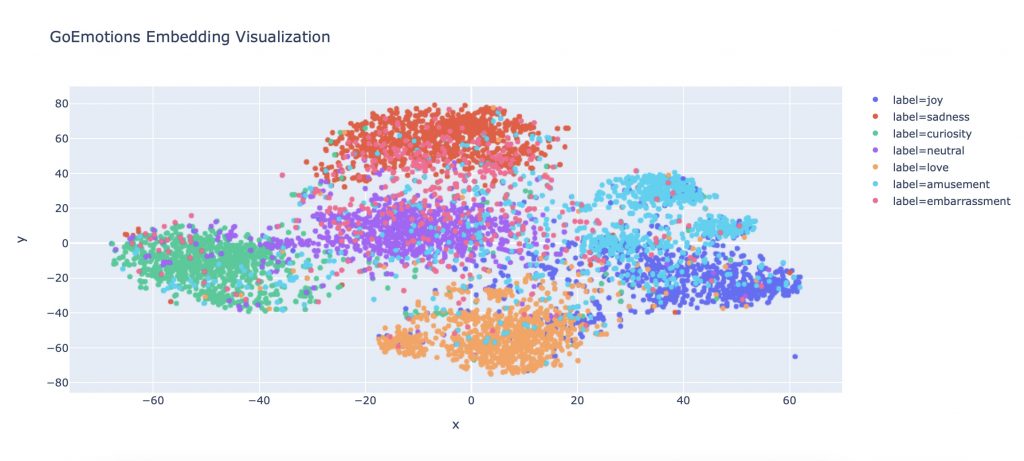
Et voilà ! Vous avez réussi à faire votre premier Embedding de phrases !
Vous pouvez maintenant visualiser comment l’algorithme de Deep Learning se représente les relations entre phrases et émotions.
D’ailleurs, on peut voir qu’il ne fait pas simplement des séparations entre chacune des émotions.
Au contraire, plus les phrases ont une émotion similaire plus elles sont proches et inversement.
Ainsi, on a les émotions ‘amour’ et ‘tristesse’ qui sont nettement éloignées mais on peut aussi voir ‘amour’, ‘joie’, et ‘amusement’ presque se confondre à certains endroits.
Le Deep Learning n‘interpréte pas seulement les émotions en fonction des phrases mais on peut voir qu’il comprend réellement la similarité des mots et leur valeurs émotionnelles.
Aller plus loin
Pour aller plus loin, on peut évidemment choisir plus d’émotions, plus de phrases (pour ça munissez-vous d’un bon GPU !) mais on peut aussi affiner l’affichage de l’Embedding en ajoutant des dimensions à cette visualisation.
Ajoutons par exemple la taille de chaque phrases dans notre dataframe :
df_embeddings['length_text'] = df_embeddings[['text']].applymap(lambda x : len(x))On peut intégrer cette dimensions à notre affichage. Ainsi plus la phrase sera longue, plus le point qui la représente sera gros :
import plotly.express as px
fig = px.scatter(
df_embeddings, x='x', y='y',
color='label', labels={'color': 'label'},
size = 'length_text', size_max = 10, template = 'simple_white',
hover_data=['text'], title = 'GoEmotions Embedding Visualization')
fig.show()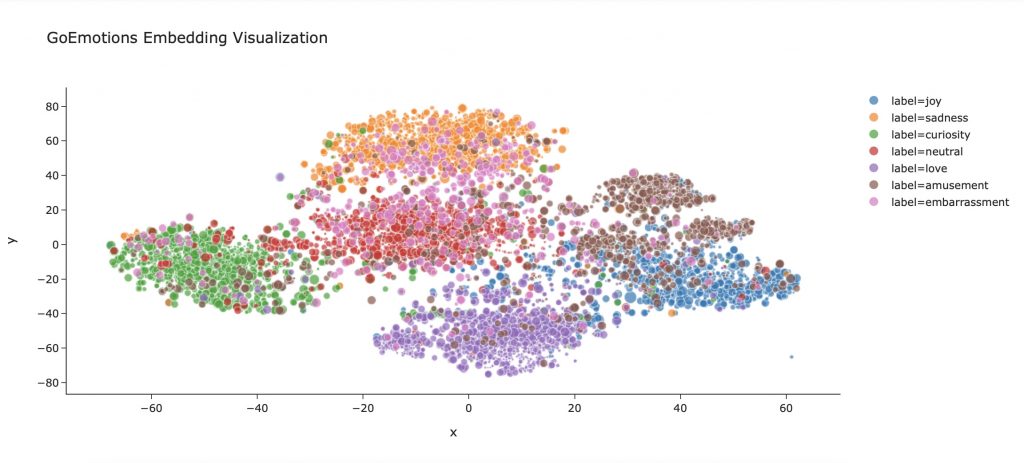
N’hésitez pas à rajouter ainsi plusieurs dimensions à cette visualisation.
Ou tout simplement changer le design. Ce n’est pas une approche technique mais cela peut changer la perception du graphique. Ici on utilise le template ‘simple_white’, plutôt pas mal non ?
C’est la fin de cet article. On espère qu’il vous aura plu !
À bientôt dans un prochain tutoriel 😉
sources :
- Le dataset GoEmotions de Google
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :