

What is Machine Learning ? How does it work ? In which fields is it applied ? Discover everything in this article !
Machine Learning is a major field of computer science and mathematics. More precisely it is a sub-field of Artificial Intelligence. It consists in creating algorithms that can learn autonomously to perform any kind of task. In fact, Machine Learning allows an algorithm to understand data, to extract rules and patterns to achieve a goal.
Machine Learning can interpret any type of data, the only prerequisite is to convert it into numerical form. Thus a Machine Learning algorithm can interact with numbers, text, images, videos, audios, etc.
Machine Learning is therefore the automatic learning by an algorithm to perform a task from data.
Let’s dive into the details !
4 steps to do Machine Learning
Pour développer un algorithme de Machine Learning il faudra suivre 4 étapes essentielles.
- Préparer ton dataset
- Choisir un algorithme de Machine Learning
- Entraîner ton algorithme
- Tester & améliorer
To develop a Machine Learning algorithm you will have to follow 4 essential steps :
- Prepare your dataset
- Choose a Machine Learning algorithm
- Train your algorithm
- Test & improve
Dataset
The first step is to prepare your dataset. Indeed, in most cases a dataset is not ready to be used directly. An excel file for example can contain empty fields, errors or even obsolete information. It will therefore have to be corrected and cleaned up.
You will then use this data to train your Machine Learning algorithm. The more accurate the data, the better the algorithm will perform. Conversely, if the data contains erroneous information, the model will be biased, which will have a direct impact on the results of your Machine Learning algorithm.
Algorithm
The second step is to choose your Machine Learning algorithm. You will have to select them according to several criteria :
- The type of data
- The amount of data
- The problem to solve
The third step is to train your algorithm to solve a task. In order to do so, it will iterates several times the task resolution on the same dataset.
It will produce results and compare them with the expected results and this is how it will understand autonomously how to improve. Thus the algorithm extracts rules and patterns allowing it to better interact with the data and finally produce optimal result !
Once the algorithm has satisfactory result (between 80 and 100% success rate), it is trained and we can move on to the last step.
The fourth and last step is to use the Machine Learning algorithm. It will be necessary to use it on real world data and analyze its results. Thus the intervention of an expert is essential. He will be able to determine if the training has been well done and if the results are adequate.
The algorithm may needs to be improved. In this case, you have three options:
- change the parameters of the model
- add new data
- modify the training parameters
What are the different Machine Learning techniques ?
In the previous section, we saw that we had to choose our Machine Learning algorithm according to the type of data we have. Indeed, our data will greatly influence the algorithm that we will use to solve our task, but above all it will determine the Machine Learning technique used.
There are three techniques of Machine Learning:
- supervised
- unsupervised
- reinforcement
The most widely used is supervised learning because it is both the simplest and the most robust.
Supervised Learning
In supervised learning, the Machine Learning algorithm learns on labeled data, that is, data annotated with the expected result. With this configuration, the algorithm can make assumptions and then test and compare them with the expected result.
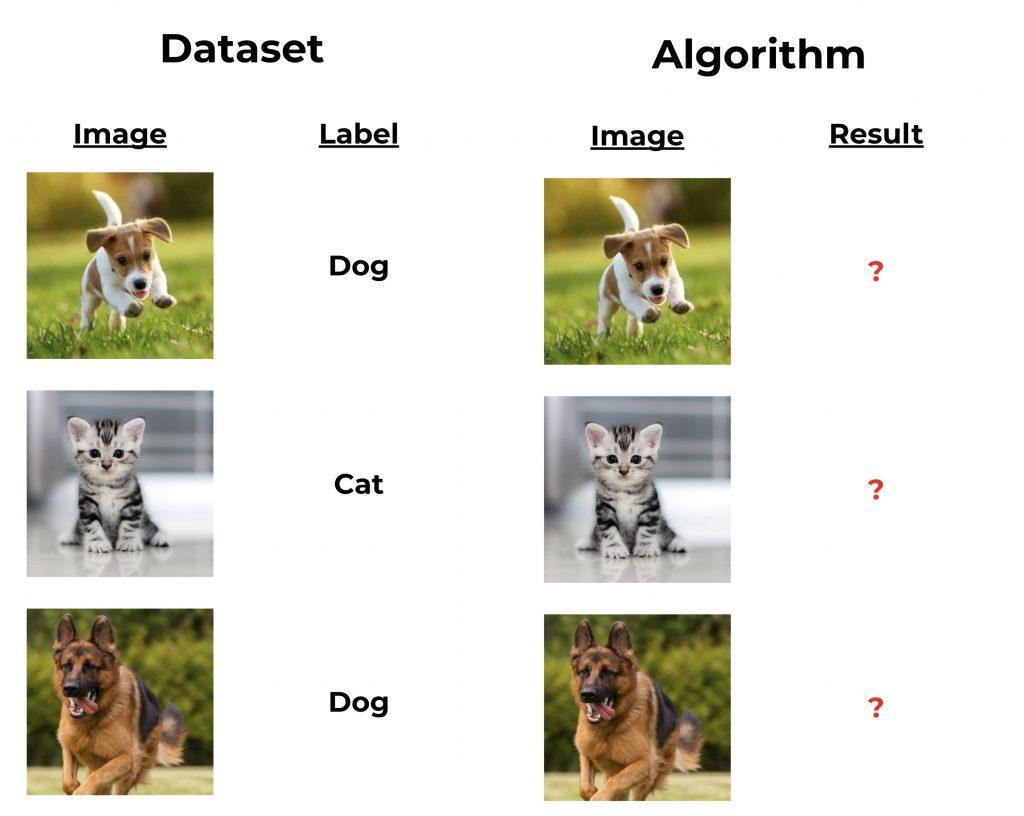
As you can imagine, this technique requires to label your dataset first. This is a costly and time-consuming process because only a human can perform this task… for now.
Many labelling (also called annotation) applications are being developed increasingly and allow annotators to label any type of data (numbers, texts, images) more quickly and more precisely than ever.
A Machine Learning algorithm can also be biased because of the training data. Indeed, if the data in the dataset is not varied enough, it can create learning biases that will impact the algorithm’s performance when processing new data.
Apprentissage Non-supervisé
It is the opposite for unsupervised learning. The data have no labels. Here the algorithm is in an experimental approach. It explores the data and tries to find the rules and patterns of the dataset on its own.
There are two use cases for unsupervised learning:
- Annotation is impossible
- Annotation is too expensive (time and money)
Often we use this technique to differentiate one type of data from another. This is what the team of Yann Le Cun, AI pioneer and researcher at Meta AI Research (formerly Facebook AI Research), did by creating the DINO algorithm. The DINO algorithm learned by unsupervised learning to separate the main object from the background in an image.
I let you judge the result yourself :
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.

Let us add that there is also semi-supervised learning which is a compromise between the two learning approaches. In this approach, only a small part of the training data is labeled. This subset of data will guide the learning of the algorithm on the rest of the data. Thus it will be able to extract the rules and patterns it needs to reach its goal. This approach is a good compromise for an expensive project that requires prior annotation of the data. Indeed, this option allows to reduce the costs by annotating only a small but diversified part of the dataset.
Reinforcement Learning
The third technique is reinforcement learning. It consists in letting the algorithm learn from its mistakes. It will test and experiment with several approaches before finding the one that best suits its task.
Indeed, during reinforcement, the algorithm is immersed in an environment where it will receive rewards and penalties depending on its actions. Its objective being to maximize its rewards, it will do everything to go in this direction and find the right way to do it.
This is how in 2017 an AI was able to beat the GO game champion (a board game), a first ever at the time !
But nowadays, AIs have gone way beyond mastering 2D games and are now able to understand and interact autonomously with a 3D universe. We can see it below in a game where the blue characters must avoid being seen by the red characters :

What is Deep Learning ?
Deep Learning is a sub-category of Machine Learning, but it is the one that attracts the most interest today. Most of the advances in Artificial Intelligence are made thanks to Deep Learning.
Deep Learning is a more complex and technical version of Machine Learning. It is done by creating algorithms from scratch while Machine Learning uses pre-existing algorithms.
The complex structure of Deep Learning gives it a greater ability to extract the rules and patterns underlying the data.
In fact, a Deep Learning algorithm is composed of neurons. The smallest may contain a few dozen, while the largest may contain millions!
When training such an algorithm, each neuron is updated and will have a defined task in solving the problem.
In fact, Deep Learning algorithms are directly inspired by the functioning of the human brain. Neurons are interconnected and transmit information to the next neurons to interpret them.
This ability to solve tasks does not come alone because it will be necessary to support this type of calculation costly in power and energy. I therefore recommend you to be equipped with a good graphics processor (GPU) to train a large neural network.
But then when should Deep Learning be used ?
Deep Learning is used for complex projects that require a deep understanding of the data.
To classify data from an excel table a classical Machine Learning algorithm will suffice. But if you want to detect objects in a video, you will need a good Deep Learning algorithm.
Machine Learning you’re using without knowing it
Machine Learning in everyday life
Nowadays, the progress of artificial intelligence is undeniable and the philosophical debate on “Is it possible to create a conscious AI ?” has just been surpassed today (June 15, 2022) by the question “Has Google already created a conscious AI ?” (The Washington Post).
But without talking about internal research in companies, what are these AIs that we use on a daily basis without knowing it?
Surely the most democratized are the recommendation AIs that are the queens of news feeds on Facebook, Instagram, … but also of music recommendations on Spotify or video on TikTok, YouTube, Netflix.
How many of us have already been absorbed for 10, 30 minutes or even 1 hour by the news feed of our social networks?
On average, a TikTok user spends 52 minutes every day on the application !
So how do these companies manage to create such powerful AI?
Simply because they are data pits.
Indeed, these apps record the slightest of your reactions (like, comment, …) to better understand what you enjoy and especially what makes you stay on the platform.
This huge database creates an ideal dataset to train an AI !
To go further
We can also note the emergence of voice assistants like Google, Siri or Alexa. These technologies are based on Voice Recognition which is an important category of Machine Learning. We can also mention the autonomous cars that are being developed more and more over the years. Here we talk about Computer Vision, another category of Machine Learning.
Finally, Data Science and Data Analysis in general is an inherent part of Machine Learning. With a dataset listing the information of a company you can predict the results it will make from one year to the next.
This work still requires a human to run the models and interpret the results, but Artificial General Intelligence could arrive sooner than expected…
If you want to start learning Machine Learning don’t hesitate to check out our section on Machine Learning basics !
See you soon on Inside Machine Learning 😉
sources :
- OpenAI – Emergent Tool Use from Multi-Agent Interaction
- Meta AI – DINO and PAWS
- The Washington Post – The Google engineer who thinks the company’s AI has come to life
- Wallaroom – TikTok Statistics
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



