In this article we will see in detail what LightGBM library is, how it creates powerful models and how to use it!
LightGBM is a Machine Learning library in Python.
It uses Decision Trees, a type of algorithm very specific in Machine Learning that we already have presented in this article.
The difference with sklearn ?
LightGBM is known to be both more efficient and scalable.
That is to say that it performs very well on small datasets as well as on large ones.
In this article, we will dive into LightGBM in detail, how it works, how to use it. We will also see how experts use it and the advanced features it offers.
To understand the whole article, I recommend having already some level of Machine Learning.
That being said, let’s get started! 🔥
What is LightGBM and how does it work?
Gradient Boosting
LightGBM is a Machine Learning library that uses Gradient Boosting on Decision Trees.
Let me explain.
Gradient Boosting is an ensemble method.
It assembles several Machine Learning algorithms to obtain a prediction on a dataset.
Since we use multiple algorithms, the result is more reliable than if we used only one.
In the case of LightGBM, the Machine Learning algorithms used are Decision Trees.
If you want to know more about ensemble methods and Gradient Boosting, we discuss it in detail right here.
The major improvement of LightGBM is its use of histograms during training.
The bins
In histogram-based algorithms, the features (the columns of our dataset) are divided into a series of bins.
A bin is a discrete interval or range of values in one of our features.
When training a Decision Tree, the algorithm looks for the best way to divide the data according to the features.
Binning consists in creating bins for each feature, then selecting the bin that allows the best loss reduction.
Let’s say we have a feature that represents the age of a person and we want to use this feature to predict if the person will have a certain disease later on.
In this case you can create bins for each value range of the age feature.
For example from 0 to 15, from 15 to 30, from 30 to 45, from 45 to 60 and from 60 to 75 :
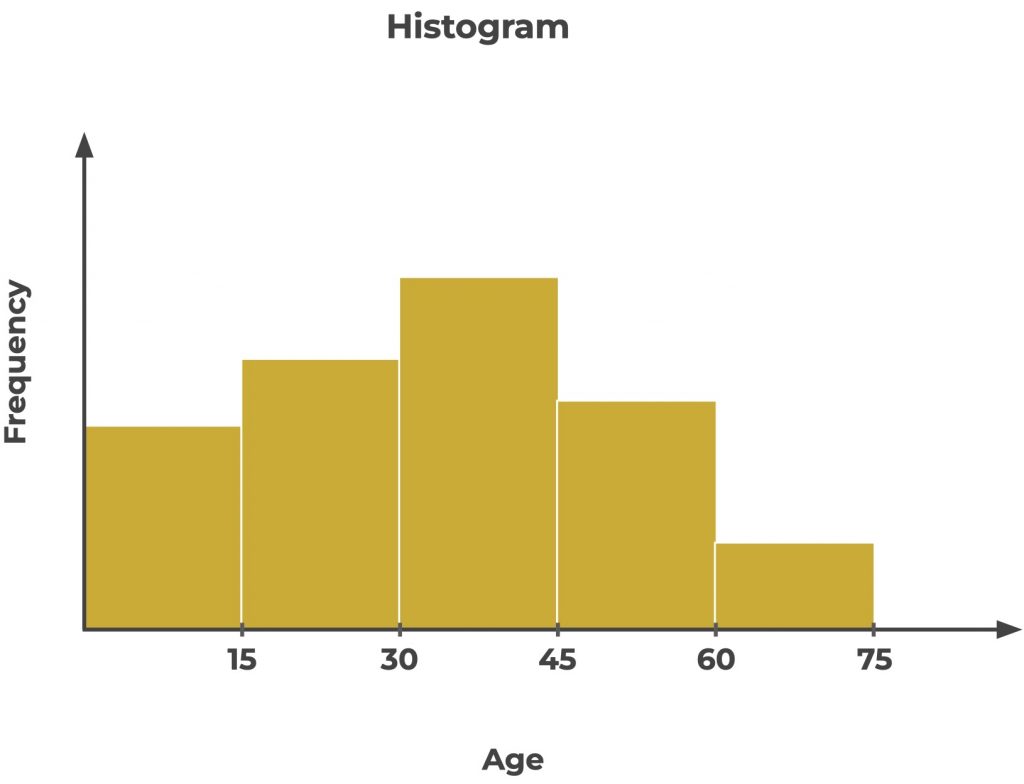
The decision tree will then look for the best distribution according to these bins.
It may estimate that people with an age below 45 are less likely to have the disease, while people with an age above 45 are more likely to have it.
The algorithm then divides the data according to this estimate and continues to build the tree in this fashion.
And this is the major breakthrough over sklearn!
Instead of creating a separate bin for each unique value of a feature, LightGBM creates a histogram of the feature values and then selects the best split based on the histogram.
To understand this, let’s go back to our previous example.
We have a feature that represents the age of a person.
Again we use this feature to estimate if a person will have a disease or not.
But with sklearn, if the ages go from 0 to 80 and there are no missing values, we will have to create 81 bins (one for each age).
This could be very computationally expensive.
The histogram method solves this problem.
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
Histograms and beyond
In addition to histograms, LightGBM also uses a leaf-wise algorithm, which grows the tree from bottom to top and automatically chooses the best distribution based on loss reduction.
This can help speed up training and improve model accuracy.
LightGBM models can be trained on multiple cores and even on a GPU, which can greatly speed up training.
It also handles categorical features and missing values well, which will make your life easier when working with real-world data.
Finally it offers a number of hyperparameter tuning options, which you can modify to optimize the performance of your model.
How to use LightGBM
To use LightGBM in Python, you must first install it.
To do that, use the pip command :
!pip install lightgbmThen, you can import it in Python :
import lightgbm as lgbIn this example we’ll use random data with numpy:
import numpy as np
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 1])To train a model with LightGBM, we need to create a LightGBM dataset from our data:
lgb_train = lgb.Dataset(X, y)Then, we specify the hyperparameters for training the model:
params = {
'objective': 'binary',
'learning_rate': 0.1,
'num_leaves': 4,
'verbose': 1
}You can find the list of hyperparameters for LigthGBM models on the official documentation.
Now we can start training the model :
model = lgb.train(params, lgb_train)And finally we can launch a prediction !
model.predict(np.array([[3, 6], [10, 7]]))In this example, we take random data so we can’t really evaluate the accuracy of the model but I invite you to do it on your side and say what you think about LightGBM in comments!
Conclusion
How do experts use LightGBM?
LightGBM has gained in popularity lately.
The library is now widely used by Data Scientists and Machine Learning professionals.
It has been used to achieve top performances in a number of Machine Learning competitions, whether it is on Kaggle or during the Amazon Web Services Machine Learning Competition.
In addition to its use in competitions, LightGBM is also used in many real-world applications.
It is used in finance, healthcare and e-commerce to solve tasks such as fraud detection, patient diagnosis and churn prediction.
LightGBM advanced features
In addition to its basic functions, LightGBM offers a number of advanced features that can be useful to improve the performance and flexibility of your models:
- Cross-validation : allows you to split the dataset into a number of batches. Then train the model on some of the batches and evaluate it on the remaining batch. This process is repeated until each batch is used as training data. More info in our article on the subject.
- Feature importance : allows to estimate the importance of each feature in the prediction of a model (no, a Machine Learning model is not an unfathomable black box)
- Early stopping : allows to stop the training process when the model performance stops improving. This can be useful to avoid overfitting and to save time during training.
If you are looking for a Gradient Boosting library, LightGBM is worth it.
Use it in your projects!
And see you soon in the next article on Inside Machine Learning 😉
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :