
Many beginners forget this technique when they create their Machine Learning algorithm. Yet… it is crucial !
This technique is called normalization.
Normalizing is putting the values of your dataframe at the same scale. For example between 0 and 1.
It’s a simple technique but it will boost the performance of your algorithm !
Get started
For this tutorial, we’ll take the happiness.csv dataset that you can download here on GitHub.
First, we import the pandas library and our dataset :
import pandas as pd
df = pd.read_csv('happiness.csv', usecols=['Gender','Mean','N='])As you can see, for this tutorial, we only use the ‘Gender’, ‘Mean’, ‘N=’ columns.
These columns represent respectively the gender of the interviewees, their average happiness rate and finally the number of interviewees.
The dataset groups these people by country but… for this tutorial, we don’t need this category 😉
We can display the first lines of our dataset :
df.head()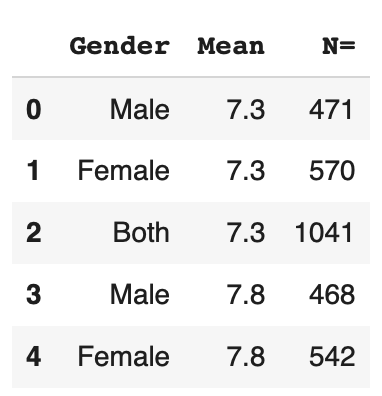
And we can get down to business !
Normalizing numbers
The first normalization is applied to quantitative data, in other words: numbers.
To do so, we apply a very simple method : divide all the numbers in a column by the max value.
This will give us values between 0 and 1.
Indeed, the max value will be divided by itself so it will be equal to 1. The others will have no choice but to be between 0 and 1.
Keep in mind that this technique only works for positive values. But other methods exist.
To apply the normalization to a whole column we use the applymap() function.
Then we specify to applymap to divide each x, each value, by the maximum value of the column :
mean_max = df[['Mean']].max()
df['Mean'] = df[['Mean']].applymap(lambda x: x/mean_max)Afterwards, we apply exactly the same method for the ‘N=’ column :
n_max = df[['N=']].max()
df['N='] = df[['N=']].applymap(lambda x: float(x/n_max))And that’s it ! We have normalizedthe quantitative values of our dataset.
To check our result, we can display first lines of the dataset :
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
df.head()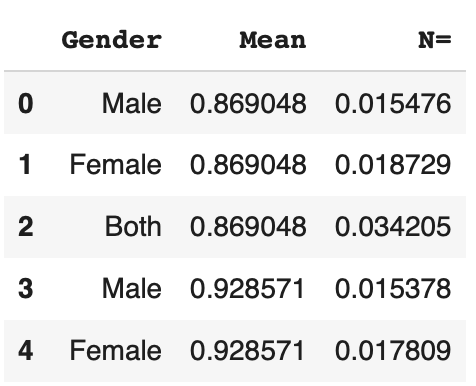
We are heading in the right direction ! But there is still one column that is problematic for us : ‘Gender’.
Normalizing the categories
To normalize the column ‘Gender’, we must first understand it.
We may analyze it with the unique() function which displays the different values that exist in a column:
df.Gender.unique()Output: [‘Male’, ‘Female’, ‘Both’]
We see that there are only 3 possible options Male, Female, or the sum of both categories.
Since there are only a few options, we can easily deduce that this is a categorical variable.
And that’s just perfect for us !
In fact with pandas it is much easier to normalize categories.
For this we use the get_dummies() function :
df = pd.get_dummies(df)We can display the result to see exactly how it is:
df.head()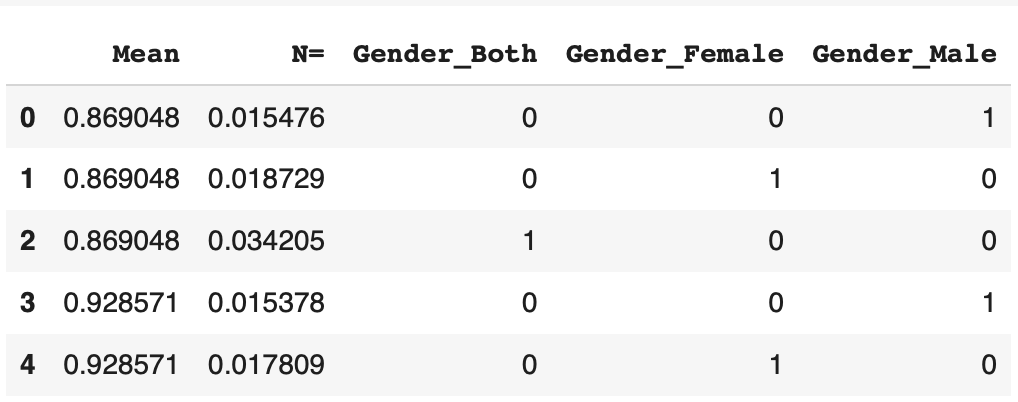
The category is nicely normalized ! The get_dummies() function creates 3 columns corresponding to each gender.
If the row corresponds to a man, the 1 is put in the corresponding column. Else 0. Same for women, and men & women.
Conclusion
That’s it ! We have normalized our dataset in a very short time.
Finally, we end up with more columns, so more data than at the beginning. One could think that this will make the learning of our Machine Learning algorithm more complex.
Quite the opposite ! Since all the data are between 0 and 1, the algorithm has less effort to make and will be more likely to perform its main task !
We have just seen how to normalize our data but in truth… there are libraries that may do this work for you without you needing to declare it. Find out more in this article !
sources :
- Photo by Zoltan Tasi on Unsplash
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



