
Cette technique, beaucoup de débutants l’oublient lorsqu’ils créent leur algorithme de Machine Learning. Pourtant… elle est essentielle !
Cette technique, c’est la normalisation.
Normaliser c’est mettre les valeurs de son dataframe à la même échelle. Par exemple entre 0 et 1.
C’est une technique simple mais qui va booster les performances de votre algorithme !
Pour commencer
Pour ce tutoriel, on va prendre le dataset happiness.csv que vous pouvez télécharge ici sur GitHub.
Tout d’abord on importe la librairie pandas et notre dataset :
import pandas as pd
df = pd.read_csv('happiness.csv', usecols=['Gender','Mean','N='])Comme vous pouvez le voir, pour ce tutoriel, on utilise seulement les colonnes ‘Gender’, ‘Mean’, ‘N=’.
Ces colonnes représentent respective le sexe des personnes interviewer, la moyenne de leur taux de bonheur qu’ils ressentent et finalement le nombre de personne interviewer.
Le dataset regroupe ces groupe de personnes par pays mais… pour ce tutoriel, nous n’avons pas besoin de cette catégorie 😉
On peut afficher les premières lignes de notre dataset :
df.head()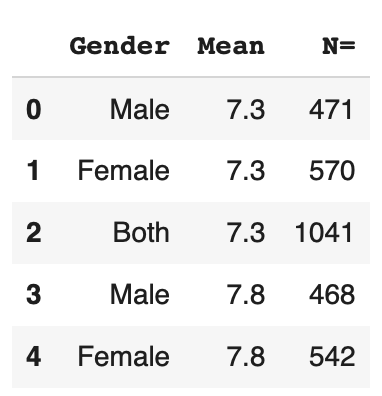
Et on peut passer à la pratique !
Normaliser les nombres
La première normalisation s’applique sur les données quantitatives, en d’autres termes : les nombres.
Pour cela, on applique une méthode ultra simple : diviser par la valeur la plus grande tout les nombres d’une colonne.
Cela aura nous permet d’avoir des valeurs entre 0 et 1.
Ehh oui la plus grande valeur sera divisée par elle même donc elle sera égale a 1. Les autres n’auront pas d’autres choix que de se situer entre 0 et 1.
Garder en tête que cette technique marche uniquement pour des valeurs positives. Mais d’autres méthodes existent.
Pour appliquer la normalisation à toute une colonne on utilise la fonction applymap().
On indique ensuite à applymap de diviser chaque x, chaque valeur, par la valeur maximum de la colonne :
mean_max = df[['Mean']].max()
df['Mean'] = df[['Mean']].applymap(lambda x: x/mean_max)Puis, on applique exactement la même méthode pour la colonne ‘N=’ :
n_max = df[['N=']].max()
df['N='] = df[['N=']].applymap(lambda x: float(x/n_max))Et le tour est joué ! On a normalisé les valeurs quantitatives de notre dataset. Pour vérifier notre résultat, on peut afficher les premières lignes du dataset :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
df.head()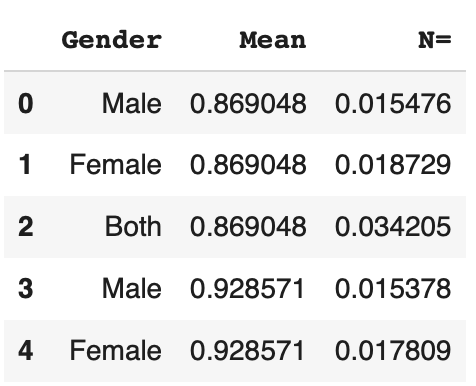
On est sur la bonne voie ! Mais il reste une colonne qui nous pose problème : ‘Gender’.
Normaliser les catégories
Pour normaliser la colonne ‘Gender’, il faut d’abord la comprendre.
On peut l’analyser avec la fonction unique() qui affiche les valeurs différentes qui existent dans une colonne :
df.Gender.unique()Sortie : [‘Male’, ‘Female’, ‘Both’]
On voit qu’il y a seulement 3 options possibles Masculin, Femme, ou la somme des deux catégories.
Vu qu’il n’y a que peu d’options, on peut facilement en déduire que c’une variable catégorique.
Et c’est parfait pour nous !
En fait avec pandas, c’est beaucoup plus facile de normaliser des catégories.
Pour cela on utilise la fonction get_dummies() :
df = pd.get_dummies(df)On peut afficher le résultat pour voir ce qu’il en est :
df.head()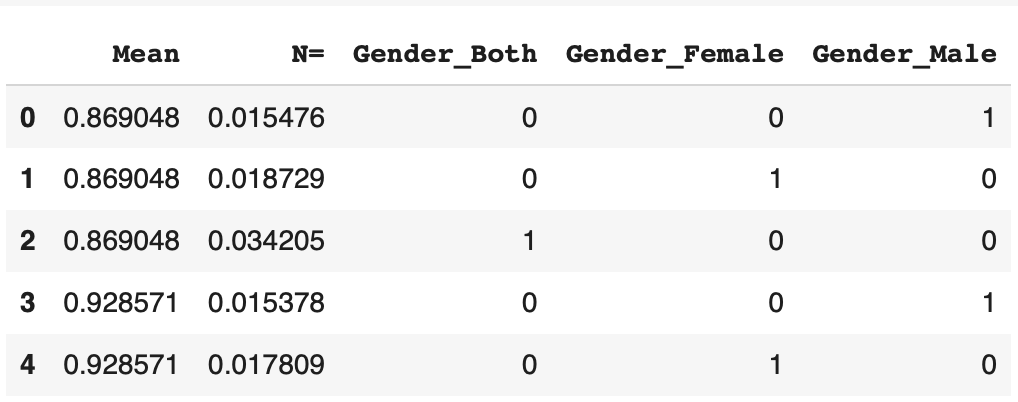
La catégorie est bien normaliser ! La fonction get_dummies() à créer 3 colonnes correspondant à chaque sexe.
Si la ligne correspond à un homme, le 1 est mis dans la colonne correspondante. Sinon 0. De même pour les femmes, et les hommes & femmes en même temps.
Conclusion
Voilà ! On a normaliser notre dataset en très peu de temps.
Finalement, on finit avec plus de colonnes, donc plus de données qu’au commencement. On pourrait donc penser que cela va complexifié l’apprentisssage de notre algorithme de Machine Learning.
Bien au contraire ! Vu que toutes les données sont entre 0 et 1, l’algorithme a moins d’effort à faire et va être plus apte à performer sur sa tâche principale !
On vient de voir comment normaliser nos données mais en vérité… il existe des librairies qui font se travail pour vous sans que vous ayez besoin de l’indiquer. Pour en savoir plus c’est dans cet article !
sources :
- Photo by Zoltan Tasi on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



