

Dans cet article on voit en détail ce qu’est LightGBM, pourquoi elle permet de créer des modèles puissants et comment l’utiliser !
LightGBM est une bibliothèque de Machine Learning en Python.
Elle utilise des Arbres de Décision, un type d’algorithme bien spécifique du Machine Learning qu’on a présenté dans cet article.
La différence avec sklearn ?
LightGBM est connu pour être à la fois plus efficace et scalable.
C’est à dire qu’elle performe très bien sur des petits datasets comme sur des grands.
Dans cet article, on va plonger en détails dans la librairie LightGBM, comment elle fonctionne, comment l’utiliser. On verra aussi la manière dont les experts l’utilisent et les fonctionnalités avancées qu’elle offre.
Pour comprendre l’entièreté de cet article, je recommande d’avoir déjà un certain niveau en Machine Learning.
Allez, sans plus tarder, on commence ! 🔥
Qu’est-ce que LightGBM et comment ça marche ?
Le Gradient Boosting
LightGBM est une bibliothèque de Machine Learning qui utilise le Gradient Boosting sur des Arbres de Décision.
Je t’explique.
Le Gradient Boosting est une méthode d’ensemble.
Elle permet d’assembler plusieurs algorithmes de Machine Learning pour obtenir une prédiction sur un dataset.
Vu qu’on utilise plusieurs algorithmes, le résultat est plus fiable que si on n’en utilisait qu’un seul.
Dans le cas de LightGBM, les algorithmes de Machine Learning utilisés sont des Arbres de Décision.
Si tu veux en savoir plus sur les méthodes d’ensemble et le Gradient Boosting, on parle en détail juste ici.
L’avancée majeur de LightGBM est son utilisation d’histogramme lors de l’entraînement.
Mais qu’est-ce que c’est qu’ce bins ?
Dans les algorithmes basés sur les histogrammes, les features (les colonnes de notre dataset) sont divisés en une séries de bins.
Un bin est un intervalle discret ou une plage de valeurs dans un de nos features.
Lors de l’entraînement d’un Arbre de Décision, l’algorithme recherche la meilleure façon de diviser les données en fonction des features.
Le binning consiste à créer des bins pour chaque features, puis à sélectionner le bin qui permet la meilleur réduction de la loss.
Supposons qu’on ait un feature qui représente l’âge d’une personne et qu’on veuille utiliser cette caractéristique pour prédire si la personne aura, plus tard, une certaine maladie.
Dans ce cas, tu peux créer des bins pour chaque tranche de valeurs du feature âge.
Par exemple de 0 à 15, de 15 à 30, de 30 à 45, de 45 à 60 et de 60 à 75 :
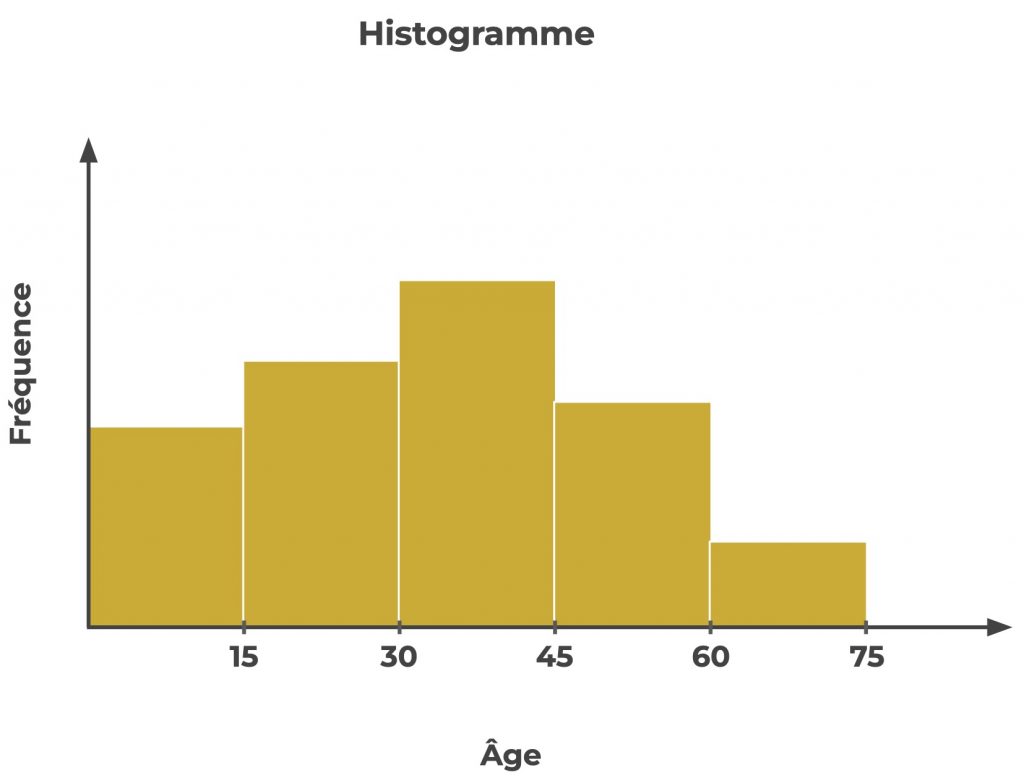
L’arbre de décision recherchera alors la meilleure répartition en fonction de ces bins.
Il pourra estimer que les personnes avec un âge inférieur à 45 ans sont moins susceptibles d’être atteintes de la maladie, tandis que les personnes avec un âge supérieur à 45 sont plus susceptibles de l’être.
L’algorithme divise alors les données en fonction de cette estimation et continue à construire l’arbre de cette manière.
Et c’est l’avancée majeur par rapport à sklearn !
Au lieu de créer un bin distinct pour chaque valeur unique d’un feature, LightGBM crée un histogramme des valeurs du feature et sélectionne ensuite la meilleure division en fonction de l’histogramme.
Pour comprendre cela, reprenons notre exemple précédent.
On a un feature qui représente l’âge d’une personne.
Là aussi on utilise ce feature pour estimer si une la personne aura une maladie ou non.
Mais avec sklearn, si les âges vont de 0 à 80 et qu’il n’y a aucune valeurs manquantes, on devra créer 81 bins (une pour chaque âge).
Cela pourrait être très coûteux en termes de calcul.
La méthode des histogrammes résout ce problème.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Les histogrammes et après ?
En plus des histogrammes, LightGBM utilise également un algorithme leaf-wise, qui fait croître l’arbre de bas en haut et choisit automatiquement la meilleure répartition en fonction de la réduction de la loss.
Cela peut contribuer à accélérer l’entraînement et à améliorer la précision du modèle.
Les modèles de LightGBM peuvent être entraînés sur plusieurs cœurs et même sur un GPU, ce qui peut accélérer grandement l’entraînement.
Il gère également bien les caractéristiques catégorielles et les valeurs manquantes, ce qui va te faciliter la vie lorsque tu travailles avec des données du monde réel.
Et finalement il offre un certain nombre d’options de réglage des hyperparamètres, que tu peux modifier pour optimiser les performances de ton modèle.
Comment utiliser LightGBM
Pour utiliser LightGBM en Python, tu dois tout d’abord l’installer.
Pour ça, on utiliser la commande pip :
!pip install lightgbmEnsuite, on peut l’importer en Python :
import lightgbm as lgbDans cet exemple on va utiliser des données aléatoires avec numpy :
import numpy as np
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 1])Pour entraîner un modèle avec LightGBM, on a besoin de créer un dataset LightGBM à partir de nos données :
lgb_train = lgb.Dataset(X, y)Ensuite, on indique les hyperparamètres pour l’entraînement du modèle :
params = {
'objective': 'binary',
'learning_rate': 0.1,
'num_leaves': 4,
'verbose': 1
}Tu peux trouver la liste des hyperparamètres pour les modèles LigthGBM sur la documentation officielle.
Maintenant, on peut lancer l’entraînement du modèle :
model = lgb.train(params, lgb_train)Et finalement on peut lancer une prédiction !
model.predict(np.array([[3, 6], [10, 7]]))Dans cet exemple, on prend des données aléatoires donc on ne peut pas réellement évaluer la précision du modèle mais je t’invite à le faire de ton côté et dire ce que tu penses de LightGBM en commentaire !
Conclusion
Comment les experts utilisent LightGBM ?
LightGBM a gagné en popularité ces dernières temps.
La libraire est désormais largement utilisé par les Data Scientists et les professionnels du Machine Learning.
Elle a permis notamment d’obtenir les meilleures performances dans un certain nombre de compétitions de Machine Learning, que ce soit sur Kaggle ou pendant la Amazon Web Services Machine Learning Competition.
En plus de son utilisation dans les compétitions, LightGBM est également utilisé dans beaucoup d’applications du monde réel.
Elle est utilisé dans la finance, la santé et le e-commerce pour résoudre des tâches comme la détection de fraudes, le diagnostic de patients et la prédiction du taux de désabonnement.
Fonctions avancées de LightGBM
En plus de ses fonctions de base, LightGBM offre un certain nombre de fonctions avancées qui peuvent s’avérer utile pour améliorer les performances et la flexibilité de tes modèles :
- Cross-validation : permet de diviser le dataset en un certain nombre de batch. Puis entraîne le modèle sur certains des batchs et l’évalue sur le batch restant. Ce processus est répété jusqu’à ce que chaque batch soit utilisé comme données d’entraînement. Plus d’infos dans notre article sur le sujet.
- Feature importance : permet d’estimer l’importance de chaque features dans la prédiction d’un modèle (non un modèle de Machine Learning n’est pas une boîte noire insondable)
- Early stopping : permet d’arrêter le processus d’entraînement lorsque la performance du modèle cesse de s’améliorer. Cela peut être utile pour éviter l’overfitting et pour gagner du temps pendant l’entraînement.
Tu l’as compris, si tu recherche une bibliothèque de Gradient Boosting, LightGBM vaut le coup.
Utilise-la dans tes projets !
On se voit dans le prochain article sur Inside Machine Learning 😉
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



