

Dans ce tutoriel, on va voir comment utiliser les méthodes d’Ensemble pour améliorer tes modèles de Deep Learning.
Le concept d’Ensemble est simple : rassembler les prédictions de plusieurs Algorithmes de Machine Learning pour obtenir un résultat optimal.
Par exemple, en calculant la moyenne d’un Decision Tree et d’une Régression Linéaire pour obtenir un nouveau résultat.
L’idée, c’est de prendre plusieurs modèles qui ont chacun leurs qualités et leurs défauts. Puis de les utiliser ensemble pour équilibrer leurs biais et obtenir une meilleure prédiction.
Prenons une métaphore : imagine que tu doives monter un meuble Ikea.
Tu sais enfoncer des clous dans le bois mais les vis c’est pas ton truc.
Tu iras beaucoup plus vite si tu appelle ton ami expert en tournevis.
Les méthodes d’Ensemble repose sur le même principe.
Chaque modèle de Machine Learning possède des biais.
Si tu utilise un nouvel algorithme et le combine à l’ancien, tu peux corriger ces biais et obtenir un meilleur résultat.
Et ça marche !
Aujourd’hui la plupart des vainqueurs en compétition de Machine Learning utilisent des Ensembles pour créer les meilleurs algorithmes.
Dans cette article, je te propose de voir les principales méthodes en théorie ET en pratique en utilisant la bibliothèque Scikit-Learn.
Notre dataset
On va utiliser le même dataset que dans notre article pour apprendre le Machine Learning avec sklearn.
Pas d’inquiétude si tu n’as pas lu l’article.
Tu peux quand même suivre ce tutoriel sans problème 😉
Tout d’abord charge mon dossier Git qui répertorie les datasets intéressant de ML :
!git clone https://github.com/tkeldenich/datasets.gitOn choisis le winequality-white.csv dataset et on l’importe dans un DataFrame Pandas :
import pandas as pd
df = pd.read_csv("/content/datasets/winequality-white.csv", sep=";")
df.head(3)
Ici une ligne représente un vin.
Chaque colonne est une caractéristique de ce vin.
Le but est de prédire la qualité du vin grâce aux caractéristiques.
Si tu veux une Data Analyse détaillée, je te renvoie à cet article.
C’est un problème de classification avec 7 classes (la qualité du vin allant de 3 à 9).
On sépare notre dataset entre les features X et le label Y :
df_features = df.drop(columns='quality')
df_label = df['quality']Puis entre les données d’entraînement et les données de test :
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_features, df_label, test_size=0.20)Ça y est ! on est prêt à utiliser les méthodes d’Ensemble.
L’objectif est de faire mieux que les algo de Machine Learning précédents !
La plupart atteigne difficilement une précision de 45%.
Mais le Decision Tree les surpasse tous, avec une précision de 60%.
Essayons de faire mieux avec les Ensembles !
Algorithmes de Bagging
Les algorithmes de Bagging utilisent plusieurs algorithmes de Machine Learning appelées Weak Learners.
Ils sont entraînés de manière indépendante sur le dataset. On appelle ça un entrainement en parallèle.
Une fois entraînés, on rassemble leurs résultats en prédictions finales.
Pour ça on utilise, le plus souvent, le calcul de la moyenne des prédictions.
Voyons les différents algorithmes de Bagging que nous proposent sklearn.
Bagging Classifier – Méthode d’Ensemble
Théorie
Premièrement on a le Bagging Classifier. C’est un ensemble d’algorithmes similaires qui sont chacun entraînés sur un sous-dataset.
L’idée c’est de séparer aléatoirement le dataset en plusieurs sous-datasets, par exemple 3.
Chacun de ces 3 sous-datasets va permettre d’entraîner un algorithme.
À la fin, on aura donc 3 algorithmes, entraînés sur des datasets différents.
J’insiste sur le fait que ces algorithmes sont similaires.
C’est à dire que si tu choisis un Decision Tree, les 3 algorithmes seront des Decision Tree avec les mêmes hyperparamètres de bases.
La seule différence réside dans les données avec lesquelles ils sont entraînés.
Pour utiliser cette ensemble sur des nouvelles données X_test, on lance les 3 algorithmes.
On aura 3 résultats:
- y_pred_1
- y_pred_2
- y_pred_3
On obtient le résultat final en « agrégeant » ces résultats, soit en calculant la moyenne des 3, soit en prenant le choix majoritaire (on appelle cela « un vote »).
Voilà le schéma de l’algorithme de Bagging :
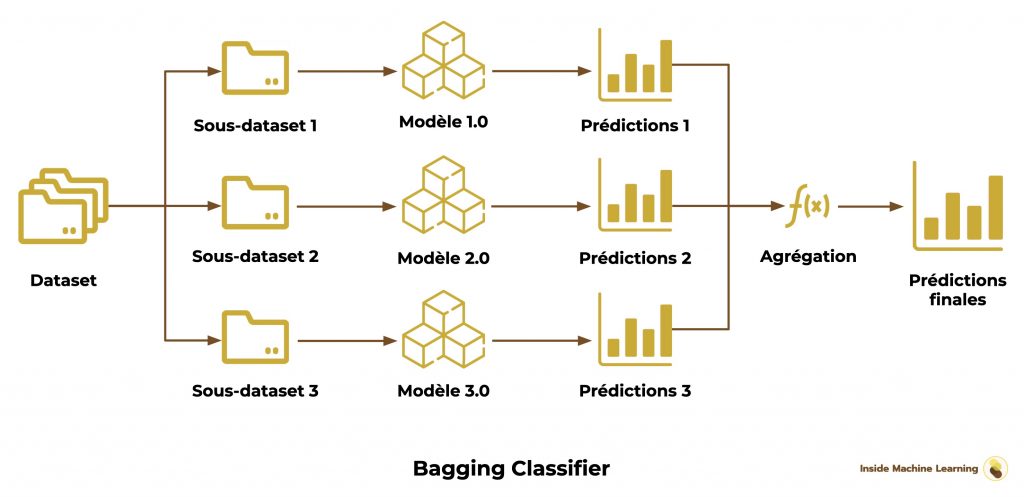
Comprendre la moyenne
Prenons le premier vin. Imaginons que nous ayons les résultats probabilistiques suivant pour les 3 algorithmes :
- probabilité d’être de qualité 3 = 30% – probabilité d’être de qualité 4 = 70%
- probabilité d’être de qualité 3 = 80% – probabilité d’être de qualité 4 = 20%
- probabilité d’être de qualité 3 = 70% – probabilité d’être de qualité 4 = 30%
La moyenne nous donne :
probabilité d’être de qualité 3 = (30 + 80 + 70) / 3 = 60%
probabilité d’être de qualité 4 = (70 + 20 + 30) / 3 = 40%
L’Ensemble prédit que le vin est de qualité 3 !
Comprendre le vote
Prenons à nouveau le premier vin. Mais cette fois-ci on ne va PAS prendre les résultats probabilistiques.
On prend les résultats directs des algorithmes. C’est-à-dire qu’on prend la probabilité la plus haute et lui attribue un 1, et on attribue un 0 aux autres probabilité. Voilà ce que ça nous donne pour les 3 algorithmes :
- résultat pour la qualité 3 = 0 – résultat pour la qualité 4 = 1
- résultat pour la qualité 3 = 1 – résultat pour la qualité 4 = 0
- résultat pour la qualité 3 = 1 – résultat pour la qualité 4 = 0
Ici on regarde quelle qualité de vin a le plus de 1.
C’est la qualité 3 qui l’emporte !
L’Ensemble prédit là aussi que le vin est de qualité 3.
Pratique
Le Bagging classifier peut sembler compliquer.
Sklearn le rend super simple!
Voilà le code pour initialiser un Bagging Classifier et l’entraîner sur nos données :
from sklearn.ensemble import BaggingClassifier
baggingClassifier = BaggingClassifier(n_estimators=100)
baggingClassifier.fit(X_train, y_train)Tu peux voir qu’on n’a pas besoin de séparer notre dataset.
Sklearn s’occupe de tout.
On peut indiquer le modèle sur lequel l’Ensemble doit se baser. Mais par défaut, si on n’indique rien, sklearn prendra un Decision Tree.
On affiche le résultat :
baggingClassifier.score(X_test, y_test)Sortie: 0.679
On obtient une précision de 67.9% ! C’est 7.9% de plus qu’un Decision Tree classique.
C’est une amélioration considérable !
Voyons la puissance des autres algorithmes de Bagging.
Voting Classifier – Méthode d’Ensemble
Théorie
Ici, on a le Voting Classifier.
Il ressemble beaucoup au Bagging Classifier.
Mais il est différent.
Ici, l’Ensemble n’est pas forcément composé d’algorithmes similaires.
On peut avoir un Decision Tree et deux Régression Linéaire.
Ensuite, le dataset n’est pas séparer de manière aléatoire.
On garde le dataset complet et on entraîne tous les modèles avec.
Finalement, on fait voter les algorithmes, comme on a vu précédemment.
Voilà le schéma du Voting Classifier :
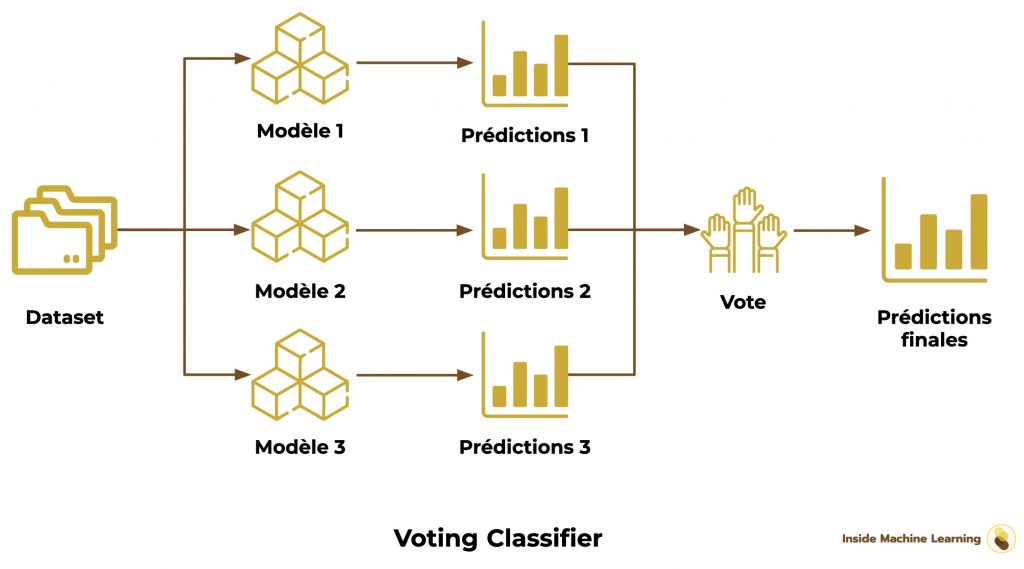
Le Voting Classifier est le plus long Ensemble Bagging à mettre en place.
Il faut choisir chacun des modèles de notre ensemble.
On peut aussi ajouter des poids qui permettent de contrôler l’importance de chacun des modèles.
Ici je choisis d’attribuer le poids le plus important au Decision Tree qui est le meilleur modèle pour résoudre notre problème :
from sklearn.ensemble import VotingClassifier
from sklearn import tree
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
decisionTree = tree.DecisionTreeClassifier()
logisticRegression = LogisticRegression()
SGD = SGDClassifier()
GNB = GaussianNB()
votingClassifier = VotingClassifier(estimators=[
('tree', decisionTree), ('lr',logisticRegression), ('sgd', SGD), ('gnb', GNB)],
weights=[2,1,1,0.5])
votingClassifier.fit(X_train, y_train)Ensuite on calcule le score de l’Ensemble :
votingClassifier.score(X_test, y_test)Sortie: 0.603
60% de précision. Le Voting Classifier n’a pas donnée le meilleur résultat.
Passons à la suite !
Random Forest – Méthode d’Ensemble
On arrive au fameux Random Forest.
Là, on est censé péter les score.
Le Random Forest est un Ensemble de Decision Tree (le meilleur modèle pour notre projet).
Comme pour le Bagging Classifier, on sépare aléatoirement notre dataset en sous-dataset.
Puis on entraîne différents Decision Tree sur chaque sous-dataset.
Finalement on utilise la moyenne pour obtenir les prédictions finales :
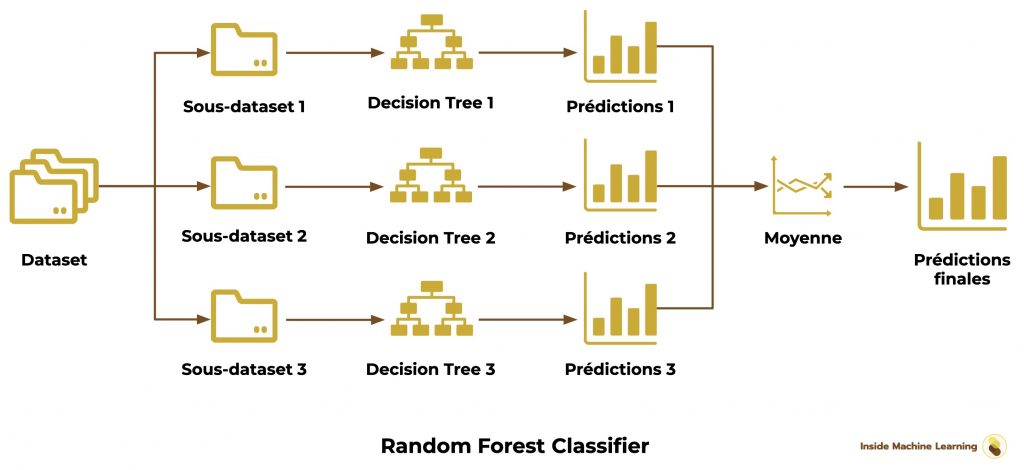
L’implémentation est très simple avec sklearn :
from sklearn.ensemble import RandomForestClassifier
randomForest = RandomForestClassifier(n_estimators=100)
randomForest.fit(X_train, y_train)Ensuite on calcule le score :
randomForest.score(X_test, y_test)Sortie: 0.7
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
70%, notre meilleur score ! 🔥
On a réussi à avoir un bon score alors qu’on partait avec très peu d’avantages de notre côté.
Le premier modèle entraîné avait une précision de 46%.
Avec de la motivation et les bonnes techniques, on a réussi à augmenter cette précision de plus de 24%. C’est énorme !
Si tu as suivis le projet du début jusqu’ici, tu peux te féliciter !
Continuons avec le reste des algorithmes d’Ensemble.
Algorithme de Boosting
Les algorithmes de Boosting rassemblent plusieurs versions d’un même algorithme de Machine Learning (Weak Learners).
On entraîne la première version du modèle sur le dataset.
Puis on crée une deuxième version du modèle et on l’entraîne, lui aussi, sur le dataset.
L’objectif ici est d’améliorer la nouvelle version du modèle en ciblant les faiblesses du premier.
Chaque algorithme entraîné est une nouvelle version du précédent. On appelle ça un entrainement séquentiel.
Finalement comme pour les algorithmes de Bagging, on rassemble les résultats en prédictions finales en calculant de la moyenne des prédictions.
Passons aux algorithmes proposés par sklearn !
AdaBoost – Méthode d’Ensemble
AdaBoost est le raccourci pour Adaptive Boosting.
L’idée est très similaire au concept de Bagging Classifier.
On va créer plusieurs version du modèle.
Cependant ici, on ne l’entraîne pas sur différents sous-dataset.
On entraîne le premier modèle sur l’entièreté du dataset.
Puis on observe ses prédictions.
On crée une nouvelle version du modèle en ajustant les poids au niveau des prédictions incorrectes du premier.
On répète le processus jusqu’à satisfaction.
De cette manière les nouvelles versions du modèle se concentrent davantage sur les cas difficiles repérer par les précédents.
Ainsi chaque modèle équilibre les défauts des autres.
La prédiction finale est un vote ou une moyenne de tous les modèles.
Voilà le schéma du Boosting Classifier :
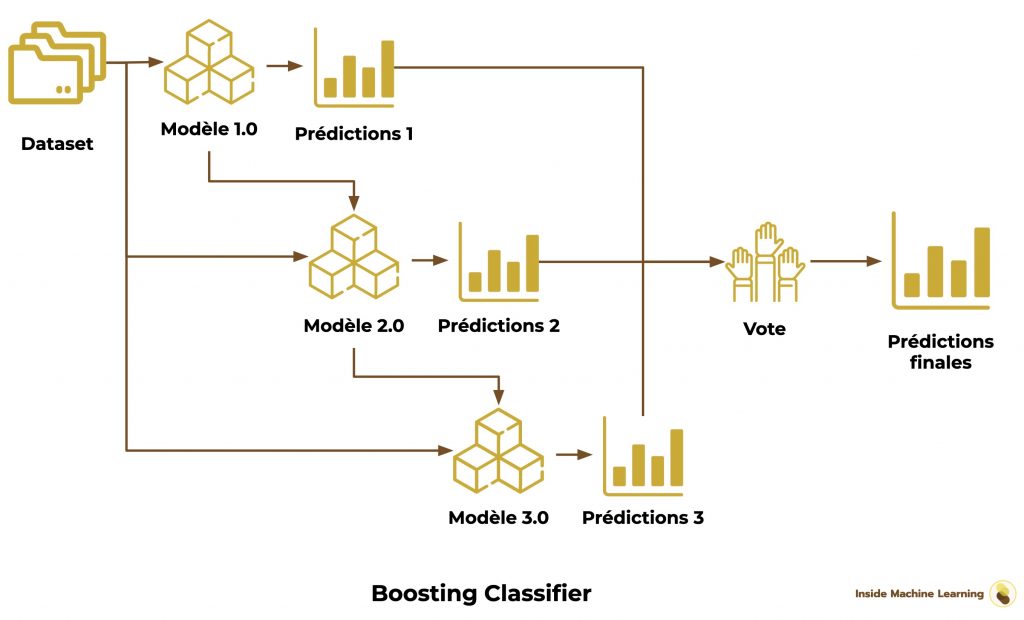
Pour utiliser AdaBoost avec sklearn :
from sklearn.ensemble import AdaBoostClassifier
adaBoost = AdaBoostClassifier(n_estimators=100)
adaBoost.fit(X_train, y_train)On calcule le score :
adaBoost.score(X_test, y_test)Sortie: 0.443
On obtient une précision de 44.3%.
Pour l’instant AdaBoost nous donne le score le moins bon parmi les méthodes d’Ensemble.
En fait, AdaBoost est LE premier algorithme de Boosting créé.
Aujourd’hui de nouveaux algorithmes de Boosting existent notamment disponible via les librairies LightGBM, XGBoost ou encore CatBoost.
Gradient Boosting – Méthode d’Ensemble
Historiquement AdaBoost est le premier algorithme de Boosting.
Le Gradient Boosting le suis de près.
En fait AdaBoost permet de résoudre des problèmes particuliers.
En voyant ses résultats prometteurs, des chercheurs ont décidé de généraliser l’approche mathématique d’AdaBoost avec l’algorithme du Gradient Boosting.
Ainsi le Gradient Boosting peut résoudre bien plus de problème qu’AdaBoost.
Et même si AdaBoost est le plus vieux, il est aujourd’hui vu comme un cas particulier du Gradient Boosting.
Je ne veux pas rentrer dans les détails mathématiques de l’algorithme.
Garde simplement à l’esprit que GradBoost est une généralisation d’AdaBoost.
C’est-à-dire qu’il est efficace sur la plupart des datasets, contrairement à AdaBoost qui est plus spécifique.
Et si tu es un mathématicien curieux, voilà les réf’ qui t’intéresseront :
- Invention d’Adaboost, le premier algorithme de boosting [Freund et al., 1996, Freund et Schapire, 1997].
- Conception d’un algorithme Adaboost similaire à la descente de gradient utilisant une loss function particulière [Breiman et al., 1998, Breiman, 1999].
- Généralisation d’Adaboost en Gradient Boosting afin de traiter une variété de loss function[Friedman et al., 2000, Friedman, 2001]
Le schéma du Gradient Boosting est le même qu’AdaBoost étant donnée que seulement les mathématiques profondes différent.
Voilà comment utiliser le Gradient Boosting avec sklearn :
from sklearn.ensemble import GradientBoostingClassifier
gradientBoosting = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,max_depth=1, random_state=0)
gradientBoosting.fit(X_train, y_train)On calcule le score :
gradientBoosting.score(X_test, y_test)Sortie: 0.524
52% de précision, l’amélioration par rapport à AdaBoost est notable.
Mais voyons une évolution encore plus récente du Gradient Boosting.
Histogram-Based Gradient Boosting – Méthode d’Ensemble
Pour faire simple le Histogram-Based Gradient Boosting est une version plus rapide de GradBoost.
Plus rapide donc plus facile à calculer.
Cela permet d’allouer plus de temps à l’optimisation. Et donc d’obtenir de meilleur résultat.
Le Histogram-Based Gradient Boosting utilise une structure de données appelé histogramme dans lequel les éléments sont implicitement ordonnés.
Cela permet un traitement rapide de l’information.
Encore une fois, tu peux te référer au schéma d’AdaBoost étant donnée que la seule différence est d’ordre mathématique.
Voilà comment utiliser le Histogram-Based Gradient Boosting :
from sklearn.ensemble import HistGradientBoostingClassifier
histGradientBoostingClassifier = HistGradientBoostingClassifier(max_iter=100)
histGradientBoostingClassifier.fit(X_train, y_train)Puis on calcule le score :
histGradientBoostingClassifier.score(X_test, y_test)Sortie: 0.671
67.1% de précision, c’est le meilleur score pour les algorithmes de Boosting !
On peut finalement passer aux derniers types d’algorithmes d’Ensemble…
Algorithmes de Stacking
Les algorithmes de Stacking utilisent les résultats de plusieurs algorithmes de Machine Learning. Ces résultats sont ensuite utilisées comme données d’entrée pour un algorithme final qui donne la prédiction.
Les algorithmes sont entraînés de manière indépendantes sur le dataset.
Comme pour le Bagging c’est un entraînement en parallèle.
On rassemble ensuite les prédictions (on les stack).
Un dernier algorithme est finalement utilisé sur l’ensemble des résultats pour obtenir les prédictions finales.
Sklearn nous propose un seul algorithme de Stacking :
Stacking Classifier – Méthode d’Ensemble
Le Stacking Classifier fonctionne selon la méthode classique du Stacking.
En plus de cela, le modèle final est entraîné en utilisant la cross-validation, une technique dont on a déjà parlé dans cet article.
Voilà le schéma du Stacking Classifier :
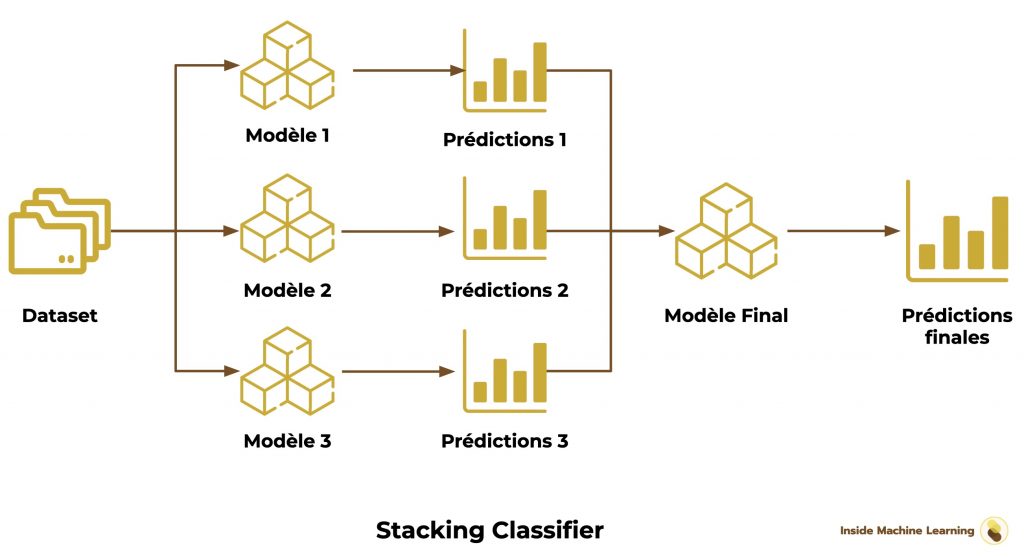
Pour l’utiliser, on indique les modèles qui nous intéressent :
- les modèles à entraîner en parallèle
- le modèle de prédiction final
from sklearn.ensemble import StackingClassifier
from sklearn import tree
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
decisionTree = tree.DecisionTreeClassifier()
logisticRegression = LogisticRegression()
SGD = SGDClassifier()
GNB = GaussianNB()
finalClassifier = LogisticRegression()
stackingClassifier = StackingClassifier(estimators=[
('tree', decisionTree), ('lr',logisticRegression), ('sgd', SGD), ('gnb', GNB)],
final_estimator=finalClassifier)
stackingClassifier.fit(X_train, y_train)Et on calcule le score :
stackingClassifier.score(X_test, y_test)Sortie: 0.477
Pour cette dernière méthode, on obtient une précision 47.7% !
Conclusion
Le Random Forest est incontestablement la meilleure méthode d’Ensemble à utiliser pour notre dataset avec 70% de précision !
Il est suivi de près par le Bagging Classifier et le Histogram-Based Gradient Boosting qui nous donne tous deux 67% de précision.
Voilà ce qu’il faut retenir sur les 3 types d’algorithme d’Ensemble :
| Apprentissage | Technique | Avantage | |
| Bagging | Parallèle | Assemblage de modèles différents | Approche diversifiée |
| Boosting | Séquentiel | Assemblage de plusieurs versions d’un même modèle | Amélioration Successive |
| Stacking | Parallèle + Stacké | Assemblage de modèles différents évalués par un modèle final | Assemblage évalué par un modèle Indépendant |
C’est la fin de cet article étendu sur les méthodes d’Ensemble.
Si tu es arrivé jusqu’ici, tu as emmagasiné beaucoup d’informations.
À l’avenir, tu peux te référer aux schémas qui constitue une base solide pour comprendre les méthode d’Ensembles.
Utilise-les !
Ce n’est pas pour rien qu’ils sont les favoris en compétitions de Machine Learning.
Avec, tes modèles vont passer au niveau supérieur...
Mais il reste encore d’autres algorithmes à découvrir !
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources :
- Documentation Scikit-learn – Ensemble methods
- Cheng Li, Northeastern University – A Gentle Introduction to Gradient Boosting
- StackExchange – Intuitive explanations of differences between Gradient Boosting Trees (GBM) & Adaboost
- StackExchange – Adaboost vs Gradient Boosting
- Medium – Ensemble methods: bagging, boosting and stacking
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



