

Ici, je te dévoile comment installer et utiliser cuML sur Google Colab pour entraîner rapidement tes modèles de Machine Learning.
Google Colab propose des notebooks sur le cloud permettant d’exécuter du code Python.
Majoritairement utilisé par les Data Scientists et les ML Engineers, Colab possède un défaut: cuML n’est pas installé dans l’environnement de base.
cuML, comme son nom l’indique, est une bibliothèque de Machine Learning exploitant l’architecture CUDA. Elle permet d’accélérer l’entraînement d’algorithmes jusqu’à 10 fois la vitesse traditionnelle (comparé à sklearn).
Les ML Engineers ont donc un réel besoin d’utiliser cette bibliothèque!
Mais qu’est-ce que CUDA ? Pourquoi sklearn est si lent ? Comment cuML contourne cet obstacle ? Et surtout comment utiliser cette librairie dans Google Colab ?
C’est ce que je te propose de voir dans cet article 🚀
Qu’est-ce que CUDA?
CUDA est une interface inventée par NVIDIA et permettant d’étendre le champs d’application des GPU à des usages multiples.
En effet, le GPU (unité de traitement graphique) est, en premier lieu, utilisé pour optimiser l’affichage et le rendu des images 2D et 3D. Ravissant les gamers, le GPU fait, à présent, également la joie des développeurs.
En effet, la technologie de NVIDIA permet d’utiliser les GPU pour effectuer des opérations mathématiques.
Par exemple, dans le domaine du Machine Learning, CUDA peut être utilisée pour accélérer l’entraînement de modèles d’Intelligence Artificielle. Cette optimisation est obtenue en distribuant les calculs sur les différents cœurs du GPU.
Lorsqu’on utilise un GPU, on dit que les calculs sont distribués ou parallélisés (car effectués en simultané).
Comparée à la programmation CPU traditionnelle, CUDA permet une exécution parallèle sur des cœurs, ce qui accélère grandement le traitement de certaines tâches:
- simulations physiques
- traitement d’image
- backward propagation dans les réseaux de neurones
- et bien d’autres
CUDA est donc une technologie clé développée par NVIDIA et qui permet d’exploiter la puissance des processeurs graphiques (GPU). Grâce à des opérations réalisées simultanément elle permet de réaliser des calculs complexes, généralement dans le domaine scientifique ou l’ingénierie.
Un Problème Majeur avec scikit-learn
scikit-learn est une bibliothèque populaire en Python pour le Machine Learning. Elle offre une variété d’outils pour la classification, la régression, le clustering, et la réduction de dimensionnalité.
Cependant, cette bibliothèque est affectée par une limitation majeure: elle est incapable de tirer parti d’un GPU.
En effet, scikit-learn peut être utilisée uniquement avec un CPU ce qui limite sa vitesse et son efficacité pour traiter des ensembles de données massifs ou pour entraîner des modèles complexes.
Contrairement à scikit-learn, les bibliothèques TensorFlow et PyTorch sont conçus pour s’intégrer facilement avec les GPU, ce qui les rend beaucoup plus rapides pour certaines tâches, en particulier pour l’entraînement des réseaux de neurones.

Ainsi, bien que scikit-learn soit un outil précieux et largement utilisé pour le Machine Learning, son incapacité à utiliser des GPU représente un inconvénient significatif. Un inconvénient qu’une autre bibliothèque a su éviter – en exploitant la puissance de CUDA.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Qu’est-ce que cuML?
cuML est un ensemble de bibliothèques pour le Machine Learning développé par RAPIDS et qui permet d’exploiter la puissance de CUDA pour optimiser l’entraînement de modèles d’IA.
Elle permet de réaliser des opérations de Machine Learning de manière plus rapide et efficace comparée aux méthodes traditionnelles basées sur les CPU.
Prenons l’exemple d’un algorithme de classification, comme le Decision Tree. En utilisant cuML, cet algorithme peut être exécuté sur un GPU ce qui réduit considérablement le temps nécessaire pour l’entraînement.
Grâce à cuML, il devient alors possible d’entraîner en un temps record des modèles de Machine Learning sur de grandes quantités de données.
Par rapport à d’autres bibliothèques de Machine Learning comme scikit-learn, conçues pour une exécution sur CPU, cuML est spécialement optimisée pour les GPU.

cuML représente une avancée significative dans le domaine du Machine Learning, offrant une vitesse de traitement et une efficacité accrues grâce à l’utilisation de CUDA.
Cela élargie les perspectives d’utilisation de modèles de Machine Learning, en particulier pour les applications traitant de grandes quantités de données.
Tutoriel: installer / utiliser cuML avec CUDA sur Google Colab
Installer cuML sur Google Colab
Pour installer la librairie cuML sur Google Colab, il est tout d’abord nécessaire d’activer le GPU.
Voici comment faire :
- Va dans
Exécution. - Clique sur
Modifier le type d'exécution. - Coche
T4 GPU. - Clique sur
Enregistrer.
Une fois que le GPU est activé, tu peux pouvez installer cuML en exécutant les commandes suivantes dans une cellule de code :
!pip uninstall -y cupy-cuda11x
!pip install --extra-index-url=https://pypi.nvidia.com cudf-cu11 cuml-cu11
!pip install pandas==1.5.3Après ces étapes, cuML devrait être installé et prêt à l’emploi sur ton environnement.
Remarque: ce code fonctionne à ce jour le 27 novembre 2023.
Utiliser cuML sur Google Colab
Pour commencer à utiliser cuML, il suffit d’importer le module :
import cumlEnsuite, tu peux utiliser la librairie de la même manière que tu utilises scikit-learn, mais avec l’avantage de l’accélération GPU.
from cuml.ensemble import RandomForestClassifier
X = X.astype('float32')
y = y.astype('float32')
cuml_rand_forest = RandomForestClassifier()
cuml_rand_forest.fit(X, y)Remarque: pour exécuter ce code il te faudra préalablement sélectionner un dataset et créer les variables X et y adéquates.
Comparaison de Performance : cuML vs Sklearn
Un des avantages significatifs de cuML est son temps d’exécution par rapport aux modèles équivalents dans scikit-learn.
J’ai personnellement comparé les résultats des temps d’exécutions des modèles des deux bibliothèques. La différence est notable. Je te laisse observer ça par toi-même sur ce graphique:
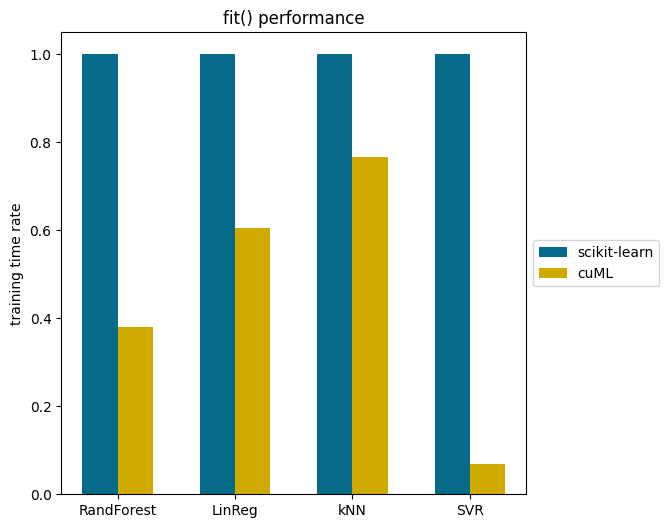
Les modèles Random Forest, Régression Linéaire, kNN, et SVR montrent une réduction de temps considérable avec cuML.
Dans le cas du SVR, cuML peut être jusqu’à plus de 10 fois plus rapide!
Le Machine Learning avec cuML est une carte🃏significative à avoir dans sa poche, mais aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



