

Je vous propose de décourvrir la libraire transformers qui résout les problèmes de NLP les plus compliqués (Question Answering, Résumé et Génération de texte, et plus) en quelques secondes !
Pendant longtemps, j’ai cherché une IA capable de produire un résumé fidèle d’un texte ou d’un article.
J’ai entraîner plusieurs modèle mais aucun ne donnait de résultat convaincant. Néanmoins, un après-midi, en m’égarant sur Twitter.. j’ai découvert LA librairie ultime pour faire du NLP : transformers.
Alors certes transformers ne permet pas de faire l’entraînement soit même, elle est donc différente de TensorFlow, PyTorch… cependnat elle met à disposition des modèles de pointes comme GPT-2, BERT, MT5 et bien d’autres !
Je vous propose aujourd’hui de explorer cette librairie pour tester ses capacités. En outre, on prendra pour thème Napoleon pour fêter le bicentenaire !

Introduction
Tout d’abord une bibliographie des sources que nous allons utiliser :
Transformers a été créé en 2020 par HuggingFace une entreprise spécialisée dans les modèle de NLP. Le nom complet de la librairie qu’il propose est « Transformers: State-of-the-Art Natural Language Processing« . Elle permet d’avoir les algorithmes à la pointe de la Recherche (état de l’art) en NLP.
À noter que nous utiliserons cette librairie avec des textes en anglais, les algorithmes n’etant pas tous à jour pour traiter la langue française.
Pour l’installer rien de plus simple :
!pip install transformers &> /dev/nullOn peut ensuite commencer à l’utiliser. Pour cela, j’ai décidé de vous présenter ses performances à la fois sur une tâche basique, l’analyse de sentiment, puis sur des tâches plus complexes.. et c’est là que ça va devenir intéressant !
Analyse de sentiments
L’analyse de sentiments, c’est vraiment la base du NLP. On a d’ailleurs écris ce tutoriel qui vous permet de créer un modèle de Deep Learning spécialisé pour ce problème.
Avec transformers, on a seulement besoin du module pipeline et indiquer que l’on veut faire de l’analyse de sentiment :
from transformers import pipeline
classifier = pipeline('sentiment-analysis')Lorsque on utilise pipeline, un téléchargement commence. En fait, la librairie charge les packages nécessaires à la résolution du problème.
Une fois que c’est fait, on entre la phrase que l’on veut analyser :
classifier('We are very pleased to introduce this tutorial for using transformers on Napoleon\'s Wikipedia.')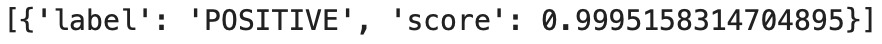
L’algorithme considére notre phrase comme positive avec un taux de fiabilité de 0.99, c’est énorme ! Et ce n’est que le début !
Question Answering
Le Question Answering, ou Question Réponse pour les plus francophile, consiste à créer un modèle de Deep Learning qui peut répondre à nos questions.
En fait on donne à notre algorithme le texte que l’on veut analyser et la question à laquelle on veut une réponse.
On commence par indiquer sur pipeline la tâche à réaliser :
nlp = pipeline("question-answering")Puis on prend un extrait du wikipedia de Napoleon :
context = r"""
Napoleon was exiled to the island of Elba, between Corsica and Italy.
In France, the Bourbons were restored to power.
However, Napoleon escaped from Elba in February 1815 and took control of France.
The Allies responded by forming a Seventh Coalition, which ultimately defeated Napoleon at the Battle of Waterloo in June 1815.
The British exiled him to the remote island of Saint Helena in the South Atlantic, where he died in 1821 at the age of 51.
"""Et enfin on lui pose notre question, tout en indiquant notre extrait, ici avec la variable context.
result = nlp(question="What was Napoleon's last battle ?", context=context)
print(f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}")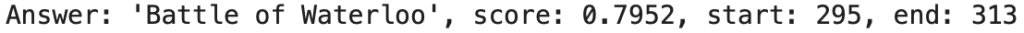
À « Quel était la dernière bataille de Napoleon ? » notre algorithme répond « La bataille de Waterloo« , plutôt pas mal non ?
L’algorithme nous indique aussi la partie de l’extrait qui lui a permis de donner cette réponse, ici à partir du 295ème caractère et au 313ème.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.

Remplir un texte à trou
Peut-être la tâche de NLP la moins fréquente : remplir un texte à trou.
Comme pour les exemples précédents, on indique à pipeline la tâche à résoudre
from transformers import pipeline
nlp = pipeline("fill-mask")Pour utiliser fill-mask il faut indiquer {nlp.tokenizer.mask_token} à l’endroit où un mot manque. L’algorithme nous donnera le top 5 des options les plus probables.
On va tester notre algorithme sur une phrase piège « L’homme le plus puissant qui ait gouverné la France était … ! ». Va-t-il nous suivre sur notre thème et répondre « Napoléon » ?
from pprint import pprint
pprint(nlp(f"The most powerful man who governed France was {nlp.tokenizer.mask_token} !"))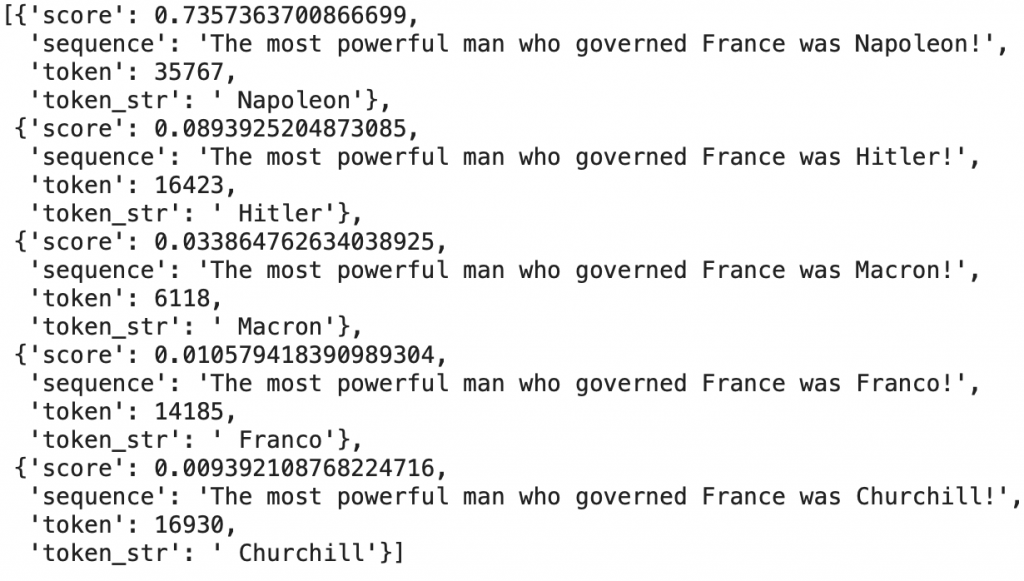
Impressionnant ! Il a répondu « Napoleon » avec un taux de confiance 73% !
On peut remarquer que les autres options, qui sont beaucoup moins probable, ont un taux de confiance de moins de 10%.
Cela signifie que notre algorithme est assez sûr de sa réponse !
Génération de texte
On continue sur notre lancée avec la génération de texte. Une des tâches les plus complexes du NLP car en plus de créer une suite de mots, l’algorithme doit créer du sens, un suite de mot qui signifique quelque chose.
Vous connaissez la procédure, on indique la tâche au module pipeline :
from transformers import pipeline
text_generator = pipeline("text-generation")Maintenant, il y a plusieurs options :
- soit on génére du texte sans aucun contexte; dans ce cas l’algorithme choisira pour nous
- soit on indique à l’algorithme le début d’une phrase; qu’il devra ensuite compléter
Ici, on indique « Pendant une longue durée, Napoléon a été » et on lui demande d’ajouter 40 caractères de plus, max_length=40.
print(text_generator("During a long period of time, Napoleon was", max_length=40, do_sample=False))On obtient : « Pendant une longue durée, Napoléon a été en mesure d’apporter quelques changements à ses tactiques militaires. Il a commencé à utiliser le ‘pistolet’ comme arme, et l’a utilisé pour attaquer.«
Cool !
Je ne sais pas si c’est vrai mais ça a du sens et ça semble tout à fait possible !
Résumer un texte, un article
On passe à notre dernière tâche et non des moindres : résumer un texte.
On utilise pipeline et on lui indique la tâche a effectuer :
from transformers import pipeline
summarizer = pipeline("summarization")Ensuite, on utilise l’introduction du wikipedia de Napoleon.
ARTICLE = """Napoléon Bonaparte (15 August 1769 – 5 May 1821) was a French military and political leader.
He rose to prominence during the French Revolution and led several successful campaigns during the Revolutionary Wars.
As Napoleon I, he was Emperor of the French from 1804 until 1814 and again in 1815.
Napoleon dominated European and global affairs for more than a decade while leading France against a series of coalitions in the Napoleonic Wars.
He won most of these wars and the vast majority of his battles, building a large empire that ruled over continental Europe before its final collapse in 1815.
One of the greatest commanders in history, his wars and campaigns are studied at military schools worldwide.
He remains one of the most celebrated and controversial political figures in human history.
Napoleon had an extensive and powerful impact on the modern world, bringing liberal reforms to the numerous territories that he conquered and controlled, especially the Low Countries, Switzerland, and large parts of modern Italy and Germany.
He implemented fundamental liberal policies in France and throughout Western Europe. His lasting legal achievement, the Napoleonic Code, has been highly influential.
Roberts says, "The ideas that underpin our modern world—meritocracy, equality before the law, property rights, religious toleration, modern secular education, sound finances, and so on—were championed, consolidated, codified and geographically extended by Napoleon.
To them he added a rational and efficient local administration, an end to rural banditry, the encouragement of science and the arts, the abolition of feudalism and the greatest codification of laws since the fall of the Roman Empire.
"""À noter qu’ici on a copier/coller l’article mais.. pour un texte plus long, comme un livre ou un papier de recherche, il pourrait être intéressant d’utiliser du web scraping pour directement récuperer le texte depuis site.
Pour utiliser notre algorithme on indique notre texte mais aussi la longueur minimale et maximale souhaitée pour le résumé.
print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False))Résultat : « Napoléon était l’un des chefs militaires les plus talentueux de l’histoire. Il a régné sur l’Europe pendant plus d’une décennie. Il a mis en œuvre des politiques libérales en France et dans le reste de l’Europe.«
La librairie transformers nous donne ce joli mot de fin pour célébrer le bicentenaire de Napoléon et l’efficacité sans cesse grandissante de l’IA.
Pour plus d’informations sur transformers n’hésitez pas à checker le résumé des tâches réalisable proposé sur HuggingFace
À bientôt pour un prochain article ! 😉

Question Answering
sources :
- Photo by Michal Matlon on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



