

Dans cet article, nous allons voir ce qu’est la quantization et comment l’utiliser avec TensorFlow pour améliorer et accélérer tes modèles.
Depuis la sortie de ChatGPT, des chercheurs s’attellent à diminuer l’espace de stockage utilisé par des réseaux de neurones – de plus en plus grand.
De nombreux techniques d’optimisation ont été évoquées et expérimentées pour réduire la taille des LLM tout en préservant leurs performances.
Une technique majeure a émergée et attirée l’oeil du monde l’Intelligence Artificielle: la quantization.
Ici, je te proposes de découvrir ce qu’est la quantization et d’apprendre à l’utiliser en TensorFlow.
Qu’est-ce que la Quantization
Le Principe
La quantization en Deep Learning est un processus permettant de réduire la taille d’un modèle dans le but d’optimiser sa vitesse de prédiction.
En d’autres termes, elle permet d’obtenir un modèle plus rapide en réduisant l’espace nécessaire à son stockage.
Les poids d’un modèle de Deep Learning sont généralement codés sur 32 bits. Pour les réduire, et optimiser leur stockage, il est possible de les convertir en 16 bits, 8 bits ou même moins.
Par exemple, la valeur 0.123456789 peut-être représentée sur 32 bits, néanmoins il n’est pas possible de la représenter sur 16 bits. Effectivement, l’espace nécessaire à sa représentation sur 16 bits n’est pas suffisant.
Pour représenter cette valeur sur 16 bits, il faut réduire sa taille. La version 16 bits de 0.123456789 est 0.1235.
Cette valeur représente 0.123456789 de manière moins précise, mais son stockage prend moins d’espace. La valeur est alors dite « quantifiée ».
Appliquée aux poids d’un réseau de neurones, la quantization permet de réduire sa taille.
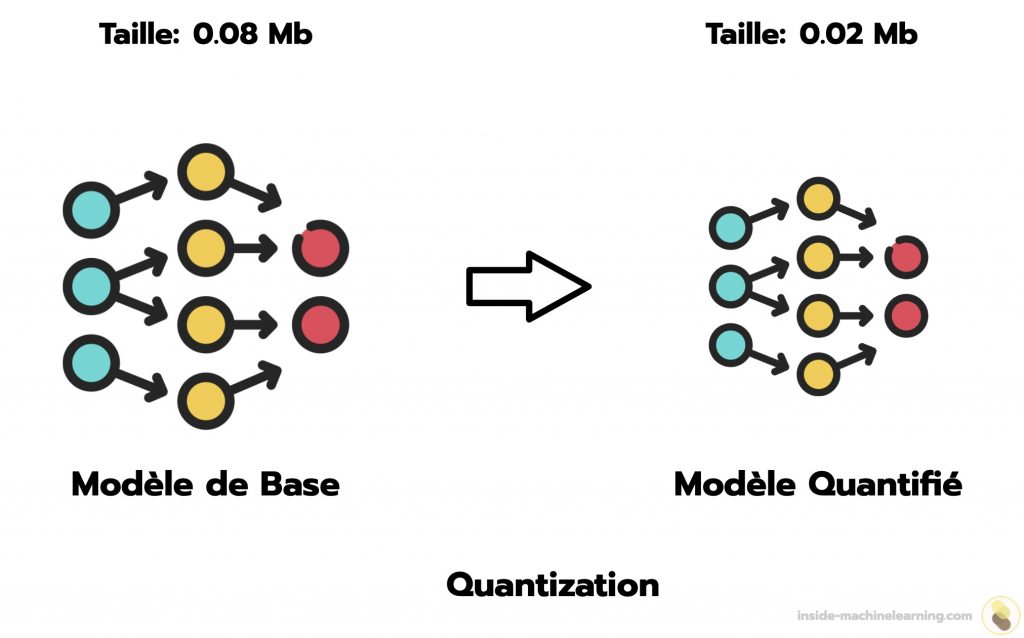
Grâce à cette taille réduite, le modèle est plus rapide. En effet, les opérations pour effectuer des prédictions nécessitent moins de temps en 16 bits qu’en 32 bits.
Avec les valeurs par défaut de l’API TensorFlow, la taille du modèle est divisée par quatre. De surcroît, on constate, en général, une amélioration de la latence du processeur, de 1.5 jusqu’à 4 fois plus rapide.
Toutefois, cette réduction a également un coût: la précision des prédictions est impactée.
Ainsi, un modèle quantifié sera certes, plus rapide, mais, souvent, moins précis.
Remarque: même si le modèle sera moins précis après cette transformation, l’impact est habituellement négligeable.
| Modèle | Accuracy – Non Quantifié | Accuracy – Quantifié sur 8-bit |
|---|---|---|
| Nasnet-Mobile | 74% | 73% |
| Resnet-v2 50 | 75.6% | 75% |
Lors du déploiement du modèle, il sera alors nécessaire de déterminer le facteur principal du modèle à accentuer: la précision ou la vitesse.
Si le chef de projet favorise la vitesse, il pourra alors accélérer l’utilisation de son modèle de Deep Learning grâce à la quantization.
Les Deux Approches
Post-Training Quantization
Le Post-Training Quantization (PTQ) consiste à quantifier les poids d’un modèle déjà entraîné.
En effet, il est possible de réduire la taille d’un modèle après qu’il ait adapté ses poids à un objectif.
Par exemple, imaginons que tu possèdes une application utilisant un modèle de Deep Learning. Si tu souhaites augmenter sa vitesse, il est tout à fait possible d’extraire les poids du modèle pour les quantifier.
Un modèle déjà entraîné, peut être quantifier facilement. Néanmoins, cette approche n’est pas optimale.
En effet, une autre voie consiste à transformer un modèle avant son entraînement, pour le rendre plus sensible à la quantization.
Quantization Aware Training
Le Quantization Aware Training (QAT) permet d’intégrer la quantification dans le processus d’apprentissage d’un modèle.
Pendant l’entraînement, le QAT imite le processus de quantification qui se produira pendant l’inférence.
Cela signifie que le modèle est entraîné tout en simulant les conditions qu’il rencontrera une fois quantifié.
L’objectif du QAT est de préparer un modèle de manière à ce que les outils utilisés plus tard pour la quantification puissent facilement et efficacement convertir ce modèle en une version quantifiée.
Ainsi, les modèles utilisant le QAT ont généralement une meilleure précision que ceux utilisant le PTQ. Le QAT est donc une approche à privilégier.
En effet, lors du PTQ, le modèle n’est pas spécifiquement optimisé pour fonctionner avec une précision réduite. La conversion après l’entraînement, peut alors provoquer une perte de performances plus importante qu’avec le QAT.
Le QAT prépare les modèles de Deep Learning à la quantization. Si tu souhaites quantifier un modèle et que les deux options s’offrent à toi, je te recommande alors d’utiliser le QAT.
Quand un Modèle de Deep Learning est-il Quantifié?
Lors du QAT, le modèle n’est pas quantifié. Plus précisément, il prend uniquement en compte la transformation future.
Avec TensorFlow, la quantization est réalisée lorsque le modèle est converti au format TensorFlow Lite.
Remarque: TensorFlow Lite est le framework de TensorFlow pour déployer des modèles de Machine Learning sur des appareils mobiles et dispositifs de pointe.
Lors de l’entraînement, le modèle n’est donc pas quantifié.
Pour effectuer cette transformation, il faudra convertir le modèle du format TensorFlow au format TensorFlow Lite.
Je te montre ça en pratique dans la partie suivante!
Comment Utiliser la Quantization
Convertir un Modèle de Base en Modèle Quantifié – PTQ
Dans cet article, nous nous concentrerons sur le QAT, ce dernier offrant une meilleure base de comparaison pour évaluer les performances de la quantization (voir section suivante).
Cependant, si tu souhaites utiliser le PTQ, voilà le code nécessaire à cela:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()Remarque: saved_model_dir est le chemin du dossier où est stocké ton modèle.
Ici, nous utilisons le module TFLiteConverter pour convertir le modèle au format TFLite. Puis converter.optimizations = [tf.lite.Optimize.DEFAULT] permet de quantifier notre modèle.
Voilà comment transformer un modèle de base en modèle en quantifié en 4 lignes de code.
Passons maintenant au tutoriel principal de cet article: le QAT.
Entraîner un Modèle de Zéro avec la Quantization – QAT
Ici, je vais te montrer comment quantifier un modèle de zéro.
Pour cela, nous allons entraîner un modèle de Deep Learning sur des données grâce au QAT. Puis nous allons le quantifier et comparer ses performances au modèle de base.
Tout d’abord, on charge des données (pour cet exemple j’utilise le dataset MNIST) et on définit la structure de notre modèle:
import tensorflow as tf
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Normalize the input image so that each pixel value is between 0 to 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
# Define the model architecture.
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(28, 28)),
tf.keras.layers.Reshape(target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])Ensuite, on peut installer la bibliothèque tensorflow-model-optimization qui va nous permettre de quantifier notre modèle:
pip install -q tensorflow-model-optimizationRemarque: si tu veux utiliser cette commande directement dans un notebook en Python, tu peux simplement ajouter un ! en début de ligne.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Ensuite, on peut rendre notre modèle quantization aware grâce à tfmot.quantization.keras.quantize_model:
import tensorflow_model_optimization as tfmot
quantize_model = tfmot.quantization.keras.quantize_model
q_aware_model = quantize_model(model)À présent, nous avons deux modèles : model et q_aware_model.
Je te propose de les entraîner pour comparer ensuite leurs performances.
On commence avec le model (non quantifié):
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
model.fit(
train_images,
train_labels,
epochs=10,
validation_split=0.1,
)Sortie:...
Epoch 10/10
1688/1688 [===] - 17s 10ms/step - loss: 0.0335 - accuracy: 0.9900 - val_loss: 0.0560 - val_accuracy: 0.9862
Puis on peut passer au q_aware_model:
q_aware_model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
q_aware_model.fit(
train_images,
train_labels,
epochs=10,
validation_split=0.1,
)Sortie:...
Epoch 10/10
1688/1688 [===] - 20s 12ms/step - loss: 0.0350 - accuracy: 0.9894 - val_loss: 0.0575 - val_accuracy: 0.9855
Remarque: un modèle quantization aware peut être utilisé de la même manière qu’un modèle non quantifié.
Maintenant que nos deux modèles sont entraînés, on peut comparer leur performance:
_, baseline_model_accuracy = model.evaluate(
test_images, test_labels, verbose=0)
_, q_aware_model_accuracy = q_aware_model.evaluate(
test_images, test_labels, verbose=0)
print('Baseline test accuracy:', baseline_model_accuracy)
print('Quant test accuracy:', q_aware_model_accuracy)Sortie:Baseline test accuracy: 0.9821000099182129
Quant test accuracy: 0.9833999872207642
Ici, le modèle quantization aware obtient une meilleure accuracy que le modèle de base.
Ce ne sera pas toujours le cas.
Comme vu précédemment, le q_aware_model devrait avoir une accuracy moins élevé que le modèle de base. Toutefois, étant donné que les deux modèles subissent un processus d’entraînement différent, une accuracy plus élevée chez le q_aware_model peut être obtenue.
Néanmoins, la plupart du temps, le modèle quantization aware obtiendra une accuracy moins élevée.
Transformation Finale
Finalement, on peut quantifier le modèle.
Pour cela, on le convertit simplement au format TFlite grâce au module TFLiteConverter. Puis on indique converter.optimizations = [tf.lite.Optimize.DEFAULT].
Dans le code qui suit, on convertit les deux modèles au format TFLite. L’un sera non quantifié, l’autre sera quantifié:
# Create float TFLite model.
float_converter = tf.lite.TFLiteConverter.from_keras_model(model)
float_tflite_model = float_converter.convert()
# Create quant TFLite model.
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
quantized_tflite_model = converter.convert()Remarque: ici, j’utilise la quantization par défaut mais tu peux expérimenter d’autres approches en te renseignant sur la documentation de TensorFlow.
Performance de taille
Pour comparer les deux modèles, on peut les enregistrer au format TFLite et afficher leur taille:
import os
# Measure sizes of models.
with open('model.tflite', 'wb') as f:
f.write(float_tflite_model)
with open('quant_model.tflite', 'wb') as f:
f.write(quantized_tflite_model)
model_size = os.path.getsize('model.tflite') / float(2**20)
quant_model_size = os.path.getsize('quant_model.tflite') / float(2**20)
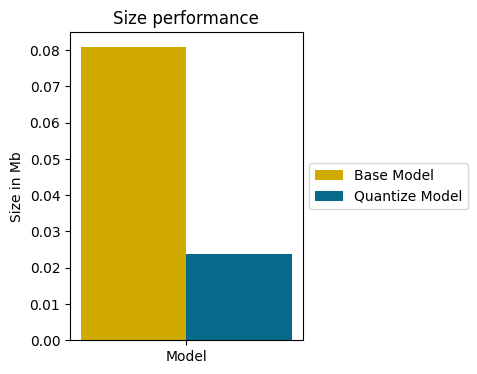
print("Float model in Mb:", model_size)
print("Quantized model in Mb:", quant_model_size)Sortie:Float model in Mb: 0.08089065551757812
Quantized model in Mb: 0.0238037109375
La quantization a permis de réduire la taille du modèle par 4 !
Cette prouesse est encore plus marquante affichée sur un graphique:
Le modèle est à présent quantifié.
Toutefois des questions subsistent: après la quantization, quelles sont les performances du modèle ? Ont-elles été drastiquement réduites ?
Je te propose de vérifier cela.
Performance d’accuracy
Dans ce code, je crée une fonction pour évaluer un modèle TFLite (le processus est différent de celui d’un modèle TF classique):
import numpy as np
import time
def evaluate_tflite_model(model, test_data):
interpreter = tf.lite.Interpreter(model_content=model)
interpreter.allocate_tensors()
prediction_digits = []
start = time.time()
for i, sample_test_data in enumerate(test_data):
output = interpreter.get_output_details()[0] # Model has single output.
input = interpreter.get_input_details()[0] # Model has single input.
input_data = tf.constant(1., shape=[1, 1])
interpreter.set_tensor(input['index'], np.expand_dims(sample_test_data, axis=0).astype(np.float32))
interpreter.invoke()
output = interpreter.get_tensor(output['index'])
digit = np.argmax(output[0])
prediction_digits.append(digit)
prediction_digits = np.array(prediction_digits)
accuracy = (prediction_digits == test_labels).mean()
inference_time = time.time() - start
return inference_time, accuracyEnsuite, on peut utiliser la fonction avec le modèle quantifié et comparer le résultat à celui du modèle quantization aware:
res_quant_model = evaluate_tflite_model(quantized_tflite_model, test_images)
print('Quant Aware TF test accuracy:', q_aware_model_accuracy)
print('Quant TFLite test accuracy:', res_quant_model[1])Sortie:Quant Aware TF test accuracy: 0.9833999872207642
Quant TFLite test accuracy: 0.9832
On remarque que le modèle quantifié a subit une légère dégradation de performance après la quantization. Néanmoins, cette perte est vraisemblablement négligeable.
Performance de rapidité
À présent, on peut comparer les performances de vitesse du modèle de base à celles du modèle quantifié.
Ici, je sépare le dataset de test en 5 parties égales et j’évalue les deux modèles:
test_batches = np.array_split(test_images, 5)
model_infs_time = []
quant_model_infs_time = []
infs_nbr = []
i = 0
for test_batch in test_batches:
i += 1
model_inf_time, _ = evaluate_tflite_model(float_tflite_model, test_images)
quant_model_inf_time, _ = evaluate_tflite_model(quantized_tflite_model, test_images)
model_infs_time.append(model_inf_time)
quant_model_infs_time.append(quant_model_inf_time)
infs_nbr.append('Inference_'+str(i))Ensuite, on peut afficher le temps d’inférence des deux modèles pour déterminer lequel est le plus rapide:
import matplotlib.pyplot as plt
import numpy as np
left = np.arange(len(model_infs_time))
width = 0.3
fig = plt.figure(figsize=(6, 4))
fig.patch.set_alpha(1)
plt.bar(left, model_infs_time, color='#d1aa00', width=width, label="Base Model", align="center")
plt.bar(left + [width], quant_model_infs_time, color='#066b8b', width=width, label="Quantize Model", align="center")
plt.xticks(left + width / 2, infs_nbr)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.ylabel("Inference time in s")
plt.title("Inference performance")
plt.show()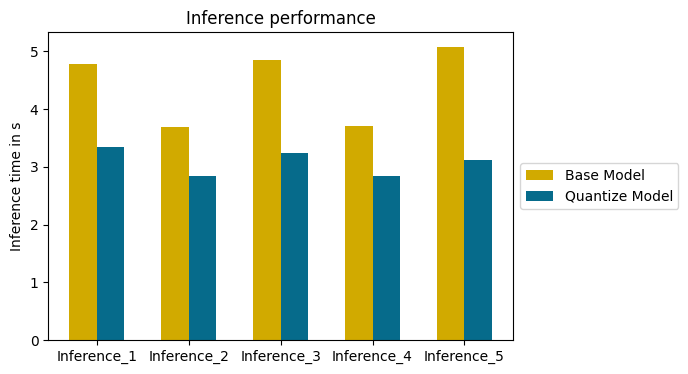
Remarque: la quantization permet d’améliorer la vitesse d’inférence des modèles de Deep Learning mais il existe également des techniques permettant d’améliorer la vitesse d’entraînement des modèles de Machine Learning traditionnel. Si tu veux lire mon article sur le sujet, clique ici.
Le modèle quantifié est plus rapide que le modèle de base sur la totalité des inférences.
Le temps moyen gagné sur cet exemple est de 1.34 seconde. Un temps précieux pour de nombreux projets de Deep Learning.
Grâce à la quantization, il est possible de réduire la taille d’un modèle de Deep Learning.
Bien qu’imposant une réduction (négligeable) de performance, cette technique permet d’améliorer grandement le temps d’exécution.
L’optimisation d’un modèle de Deep Learning est une étape importante d’un projet. En plus de la quantization, il est important que ton modèle soit structuré correctement pour obtenir de bonnes performances.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :


