

Dans cet article, je te montre comment utiliser une Random Seed avec TensorFlow pour obtenir des résultats reproductibles avec ton modèle.
À l’inverse du Machine Learning traditionnel, l’entraînement d’un modèle de Deep Learning est un processus hautement complexe.
Dans ce processus est utilisé l’aléatoire, entre autres, pour initialiser les poids des neurones.
Cette aspect aléatoire du Deep Learning est un obstacle au contrôle et à la reproductibilité des résultats.
Néanmoins, grâce à la random seed (utilisée de manière adéquate) il est possible de surpasser cette obstacle pour obtenir des résultats stables !
Qu’est-ce qu’une Random Seed ?
Une random seed (« graine aléatoire » en français) est une valeur simulant l’aléatoire utilisée dans certains algorithmes. En informatique, cette valeur est cruciale pour initialiser un processus qui produira des séquences de nombres.
Autrement dit, la random seed permet d’obtenir une séquence de nombre dite « aléatoire ».
Cette seed est en général déterminée en fonction du temps actuel. Néanmoins, le développeur peut décider de donner une valeur à cette random seed pour contrôler le processus.
Si on utilise la même seed dans un algorithme, la séquence de nombres générée sera toujours identique.
Par exemple, si un jeu vidéo utilise une seed aléatoire pour déterminer le contenu d’un coffre, deux joueurs utilisant la même seed obtiendront un trésor identique, malgré la nature « aléatoire » du processus.
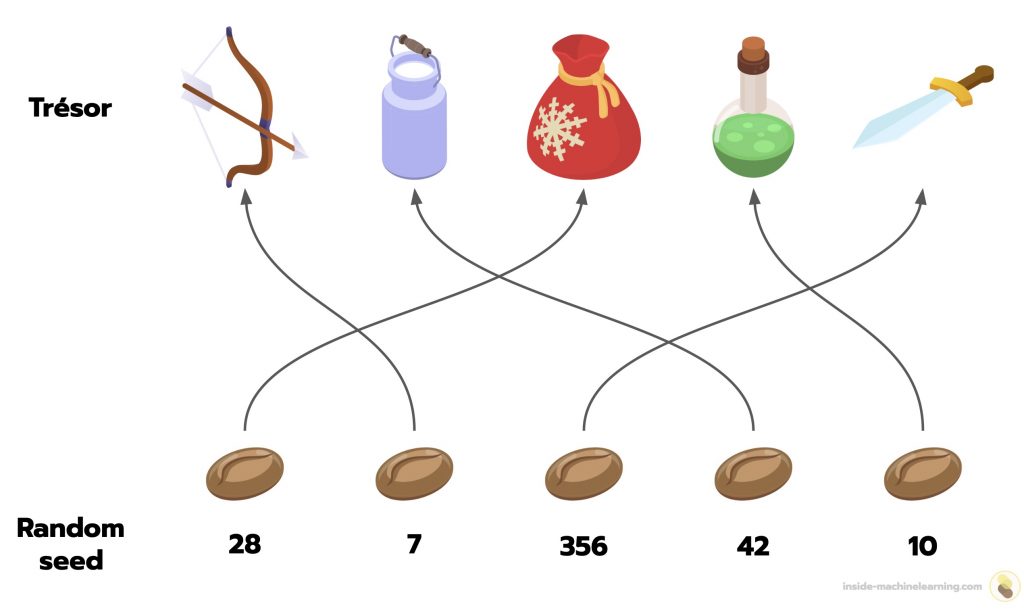
La random seed en informatique est un concept crucial pour garantir la reproductibilité et le contrôle des processus. Elle permet aux développeurs et chercheurs d’avoir une emprise sur les algorithmes.
Ainsi, bien que certains algorithmes soient en apparence aléatoire, leur processus peut en réalité être maîtrisé. C’est le cas des algorithmes de Deep Learning.
Pourquoi utiliser avoir des résultats reproductibles lors de l’entraînement de modèles de Deep Learning
Dans le Deep Learning, une random seed peut être utilisée, par exemple, pour initialiser les poids d’un réseau de neurones.
La principale raison d’utiliser une random seed est de garantir la reproductibilité des résultats.
En Deep Learning, même de légères variations dans les conditions initiales peuvent conduire à des résultats très différents. En fixant une seed, les chercheurs et ingénieurs s’assurent que leurs expériences puissent être reproduites et validées par d’autres.
Cet aspect est crucial !
En effet, un chercheur peut obtenir des résultats prometteurs avec un modèle spécifique. Mais sans une seed fixe, il serait extrêmement difficile pour d’autres chercheurs de reproduire exactement les mêmes conditions d’entraînement pour vérifier sa solution.
La random seed permet également un meilleur contrôle des expériences.
Grâce à elle, les scientifiques peuvent isoler et comprendre l’effet de certains changements dans l’architecture du modèle ou dans les hyperparamètres.
De surcroît, différentes seeds peuvent conduire à de légères variations dans les performances du modèle.
Les chercheurs peuvent utiliser cela à leur avantage, en testant plusieurs seeds pour trouver celle qui offre les meilleures performances.
L’utilisation d’une random seed dans l’entraînement de modèles de Deep Learning est essentielle pour la reproductibilité, le contrôle et l’optimisation des expériences.
Voyons comment fixer une random seed en TensorFlow dans la partie suivante.
Comment utiliser une Random Seed lors de l’entraînement de modèles de Deep Learning
Dans un modèle de Deep Learning, de nombreux éléments dépendent de la random seed.
La reproduction des résultats est alors réalisable si les conditions de programmation initiales sont reproduites.
Par conséquent, si tu veux reproduire mes résultats, je te recommande d’être dans les mêmes conditions de programmation:
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
- Environnement: Google Colab
- Version:
- Python – 3.10.12
- TensorFlow – 2.14.0
- NumPy – 1.23.5
Cela étant dit, même si ton environnement n’est pas similaire au mien, tu pourras obtenir des résultats reproductibles à condition que ton environnement ne changent pas drastiquement d’un essai à l’autre.
Précision: si tu ne change pas la version de tes bibliothèques et de Python entre deux exécutions, les résultats seront reproductibles.
Pour commencer, nous allons déterminer la random seed de TensorFlow grâce à deux fonctions:
import tensorflow as tf
SEED = 42
tf.config.experimental.enable_op_determinism()
tf.random.set_seed(SEED)tf.config.experimental.enable_op_determinism(): garantit que les opérations TensorFlow se comportent de manière déterministe, c’est-à-dire que les mêmes entrées donneront toujours les mêmes sorties.tf.random.set_seed(SEED): définit une seed globale pour TensorFlow. Cela affecte la génération de nombres aléatoires dans TensorFlow, ce qui est crucial pour l’initialisation des poids du modèle et d’autres aspects aléatoires de l’entraînement.
Ensuite, on charge des données arbitraires que nous utiliserons pour entraîner notre modèle:
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Normalize the input image so that each pixel value is between 0 to 1.
train_images = train_images / 255.0
test_images = test_images / 255.0Puis, on définit une structure pour notre modèle de Deep Learning en initialisant les poids avec notre random seed:
# Define the model architecture.
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(28, 28)),
tf.keras.layers.Reshape(target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu', kernel_initializer=tf.keras.initializers.GlorotUniform(seed=SEED)),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, kernel_initializer=tf.keras.initializers.GlorotUniform(seed=SEED))
])GlorotUniform permet de définir une seed pour garantir que les poids sont initialisés de manière identique à chaque exécution.
On peut, à présent, compiler le modèle est l’entraîner:
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_images,
train_labels,
epochs=10,
validation_split=0.1,
)Si tu exécutes ce code dans les mêmes conditions que moi, tes résultats seront identiques à ceux là:

On peut finalement évaluer les performances du modèle:
_, model_accuracy = model.evaluate(test_images, test_labels, verbose=0)
print('Test accuracy:', model_accuracy)Sortie:Test accuracy: 0.9821000099182129
Ici également, si tes conditions d’exécution sont les mêmes que les miennes, tu obtiendra ce score.
En général, quelque soit ton résultat, si tu exécutes à nouveau la totalité de ce code, tu obtiendras les mêmes résultats que ceux obtenus lors de la première exécution.
Grâce à la random seed, nous avons pu initialiser les poids du modèle et obtenir des résultats reproductibles.
Cette technique est la clé de voûte pour obtenir des résultats stables et contrôler ton réseau de neurones. Mais ce n’est pas l’unique technique à connaître pour apprendre le Deep Learning.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources:
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



