

Les Réseaux de Neurones récurrents, Recurent Neural Network ou RNN représentent une avancée majeure dans le Deep Learning.
Je vous propose dans cet article de découvrir ce que c’est et comment les utiliser !
Pour bien comprendre les RNN, il faut comprendre la place qu’ils ont dans le Deep Learning.
Les Réseaux de Neurones de bases sont appelés feedforward, littéralement nourrit vers l’avant. En fait, par feedforward il faut comprendre que l’information (la donnée d’entrée) passe une fois dans chaque couche.
Le problème avec ce type de Réseau c’est qu’ils traitent les données les une après les autres sans se soucier des relations entre elles.
Par exemple, dans cet article on a créé un modèle pour traiter des critiques de films. Ce modèle traite les phrases par bloc, les unes après les autres.
Avec les RNN, l’approche est différente. Le modèle évalue chaque mot d’une phrase, l’un après l’autre, mais en gardant en mémoire les mots qu’il a déjà traité.
Cela permet au modèle de comprendre le contexte de chaque mot et sa place dans la phrase car les mots précédemment traités vont être analyser de manière de récurrentes.
Grâce à cette mémoire, les RNN sont capable de traiter les séries temporelles comme des prévisions météos, des données de marchés financier, etc pour ensuite réaliser des prédictions.
Qu’est-ce qu’un RNN ?
L’important pour savoir ce qu’est un RNN est de bien comprendre son fonctionnement.
Quand on parle de RNN cela peut avoir deux signification:
- une couche RNN (ou couche récurente)
- un modèle de Deep Learning composé de couches RNN
Ainsi, quand on sait ce qu’est une couche RNN, on sait ce qu’est un modèle de Deep Learning a RNN !
On va donc se concentrer sur les couches RNN classique.
Les couches RNN sont récurrentes, c’est à dire que les informations qu’elles calculent vont être stockés en mémoire pour être réutiliser sur un prochain calcul.
Dans une couche classique non récurrente un neurone effectue un produit vectoriel entre l’entrée qu’il reçoit et son poids puis ajoute un biais. Ce calcul va ensuite passer dans sa fonction d’activation. En bref :
fonction_d_activation( prod_vecteur(donnée, poids) + biais)
Dans une couche RNN un deuxième produit vectorielle contenant les données en mémoire vient s’ajouter au calcul :
fonction_d_activation( prod_vecteur(donnée, poids_1) + prod_vecteur(donnée en mémoire, poids_2) + biais)
Ainsi, lorsqu’on veut prédire la valeur d’une action cotée en bourse à un temps t+1, le modèle RNN prend en compte les précédentes valeurs dans sa prédiction.
En quelques sorte, le modèle comprend la variation du prix qui a eu lieu entre t-2 et t-1, entre t-1 et t et peut prédire la futur variation entre t et t+1 !
Un schéma sur un exemple de NLP sera peut-être plus précis. Ici, on calcul la signification de la phrase « je vais à la plage » :
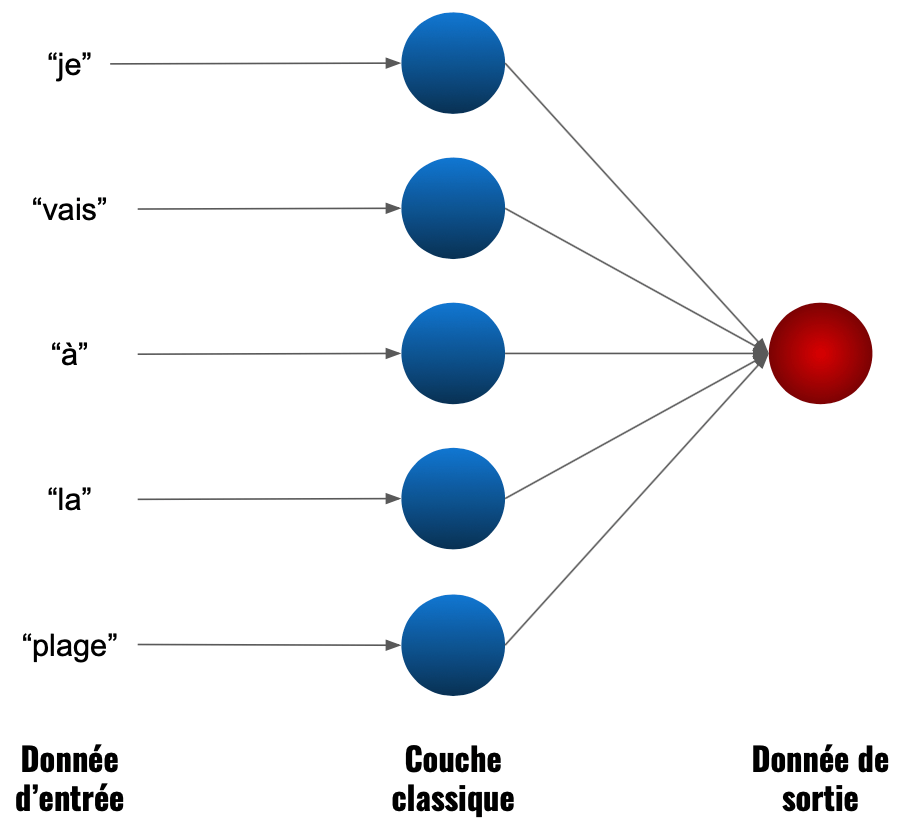
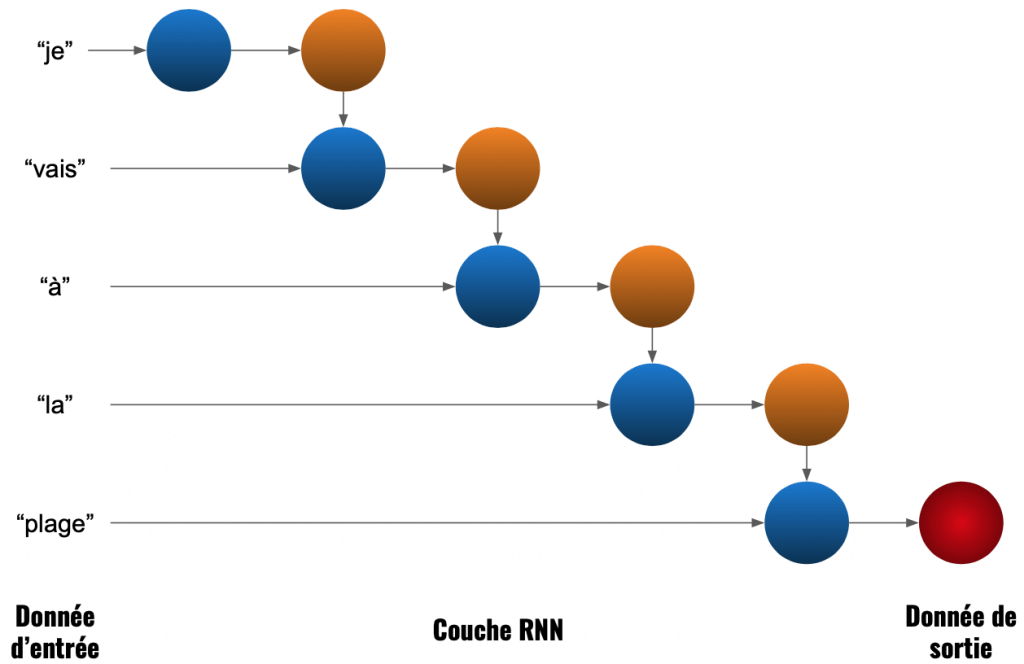
Dans une couche non récurrente, les neurones traitent bien chaque donnée (chaque mot) mais il n’y a pas de partage d’information. Il calcule en bloc.
Dans la couche RNN, chaque donnée a une importance selon sa position. Le calcul de « je » a une importance dans le calcul de « vais » puis ces deux calculs ont une importance dans le calcul de « à ».
En fait, le modèle interprète chaque élément comme faisant partie d’un même ensemble.
Avec ce genre de calcul, la machine se rapproche de plus en plus d’une réflexion humaine basée sur le contexte.
Implémentation d’un RNN avec Keras
Charger les données
Pour ce notebook disponible sur Github, nous allons utiliser le même jeu de données que dans cet article.
Nous devons donc entraîner notre modèle sur des critiques de cinéma. Une fois que l’apprentissage sera réalisé, le modèle pourra détecter si une critique est positive ou négative !
Les critiques sont déjà encodés de telle sorte qu’un même mot est représenté par un même chiffre et donc une phrase par une suite de chiffre.
Par exemple :
« un chat attrape un oiseau » sera représenté par [1, 2, 3, 1, 4].
Les critiques dans notre jeu de données sont très longues et nous voulons que notre modèle apprenne vite. On réduit donc le nombre de mots de chaque critique pour prendre seulement les 1000 qui apparaissent le plus fréquemment !
On charge ces critiques avec la fonction imdb.load_data() en précisant que nous voulons au maximum 1000 mots.
Par la suite, on a :
- les critiques contenues dans x_train et x_test
- le sentiment (1 pour ‘positif’ ou 0 pour ‘négatif’) de chaque critique contenus dans y_train et y_test
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 1000
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')Preprocessing
Il y a une dernière étape avant d’entraîner le modèle, le preprocessing.
En fait, dans ce modèle nous allons utiliser une couche Embedding qui permet d’avoir une représentation plus optimisée du texte.
Cette couche Embedding prend en entrée des tenseurs, cela implique qu’il faut que tous nos vecteurs (qui représentent les critiques) aient la même taille.
Actuellement nous avons plusieurs critiques de cinéma. Certaines sont courtes, d’autres sont longues.
Nous allons donc normaliser les vecteurs qui représentent les critiques pour qu’ils aient tous une taille de 500 :
- Pour les plus courts on rajoute des 0 au début
- Pour les plus longs on tronque le vecteur
Heureusement, la fonction de Keras sequence.pad_sequences() permet de réaliser cela simplement.
maxlen = 500
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)Construire le modèle
Couche d’Embedding
Pour construire notre modèle, on commencer par utiliser la couche Embedding. Cette couche permet de changer la représentation des données.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Au lieu d’avoir un entier pour chaque mot, on aura un nombre réel entre 0 et 1 pour chaque mot. Plus les mots sont similaires plus les nombres réels seront proches.
Ainsi, les mot ‘homme’ et ‘garçon’ auront une valeur très proche car les deux mots ont un sens très similaire.
Par exemple:
- ‘homme’ donne 0.73
- ‘garçon’ donne 0.69
- ‘fille’ donne 0.39
En quelque sorte la couche Embedding traduit en langage informatique le sens, le contexte des critiques.
Embedding est une couche car c’est un processus qui apprend durant le Deep Learning. À chaque ajustement des poids, la couche Embedding ajuste, elle aussi, ses poids et donc ajuste sa représentation des critiques de cinéma.
Plus le modèle apprend, plus la représentation sera précise.
Cette couche appliquant un changement essentiel pour nos données, elle sera toujours utilisée comme première couche d’un modèle.
from keras.models import Sequential
from keras.layers import Embedding
model = Sequential()
model.add(Embedding(max_features, 32, input_length = maxlen))Couche RNN Simple
Enfin, on utilise la couche SimpleRNN qui est la couche basique pour faire du RNN avec Keras !
SimpleRNN prend en entrée le résultat de la couche Embedding.
On y inque la dimension du vecteur de sortie, ici 32.
from keras.layers import SimpleRNN
model.add(SimpleRNN(32))Pour la couche de prédiction on utilise Dense avec la fonction sigmoïd pour fonction d’activation comme expliqué dans cet article.
from keras.layers import Dense
model.add(Dense(1, activation='sigmoid'))On peut finalement voir le schèma du modèle RNN pour avoir une meilleure représentation de ce qu’on vient de construire.
from keras.utils.vis_utils import plot_model
plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)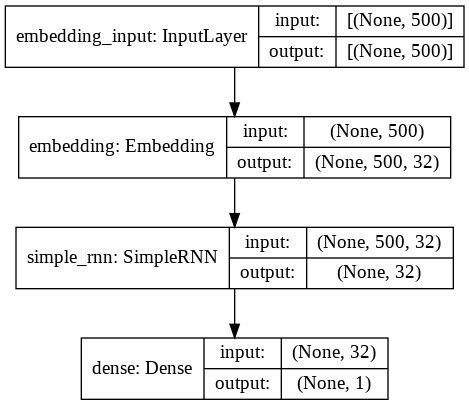
Informations supplémentaire :
N’hésitez pas à changer les dimensions du vecteur de sortie de la couche SimpleRNN ou même à ajouter d’autres couches SimpleRNN car n’oubliez pas… le Machine Learning c’est avant tout de la pratique et des tests personnels ! 😉
Lorsqu’on ajoute des couches SimpleRNN il faut insérer le paramètre return_sequences = True dans les couches SimpleRNN supérieurs, comme suit :
model = Sequential()
model.add(Embedding(max_features, 32, input_length = maxlen))
model.add(SimpleRNN(64, return_sequences = True))
model.add(SimpleRNN(32, return_sequences = True))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))Entraîner le modèle
Pour entraîner le modèle il faut configurer son apprentissage en déterminant :
- l’optimisateur
- la loss function
- la métrique pour l’évaluer
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])On entraîne le modèle avec la fonction fit().
On utilise un paramètre que nous n’avons pas vu précédement : validation_split.
Ce paramètre permet de prendre des données de validation directement depuis les données d’entraînement.
Ici, 20% des données d’entraînement seront donc utilisées, non pas pour l’entrainement.. mais pour la validation.
history = model.fit(x_train,
y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
Évaluer le modèle
La dernière étape est l’évaluation des performances du modèle.
On compare la précision qu’il a sur les données d’entraînement avec celle qu’il a eu sur les données de validation. Puis, on fait la même chose avec son erreur, sa perte.
Si l’écart est trop grand le modèle est en overfitting, il faudra alors le réajuster.
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()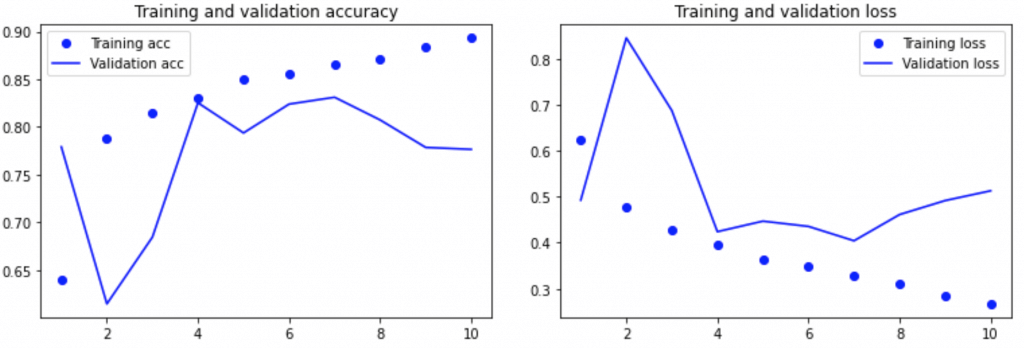
Si les performances ne nous conviennent pas, on peut ré-entrainer le modèle avec différents paramètres ou en ajoutant des couches.
Sinon, on évalue notre modèle sur les données de test !
model.evaluate(x_test, y_test)
Pour aller plus loin… Vanishing Gradient Problem
En théorie les RNN devrait être vraiment efficace pour analyser du texte néanmoins… en pratique ses performances n’ont pas l’air exceptionnelle.
Cela est lié a un problème : la disparition du gradient.
Comme vu dans cet article, durant la backpropagation on dérive la loss function pour obtenir le gradient.
Pour être plus précis, on dérive successivement l’ensemble des couches présentent dans notre modèle.
Cette dérivation successive a pour cause de réduire excessivement la valeur du gradient. Le problème se trouve ici.
Plus le gradient est petit moins il permet de changer la loss function et donc d’améliorer le modèle.
C’est-à-dire que même si le modèle peut encore s’optimiser, il n’y arrive plus car le gradient est trop faible pour provoquer une amélioration.
Ce problème arrive aussi chez les modèles feedforward (non récurrents).
Heureusement pour nous, ce problème a été résolu par Hochreiter et Schmidhber. On peut aujourd’hui utilisé de meilleures couches récurrentes :
- la couche LSTM
- la couche GRU
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Pour y accéder, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



