

Dans cet article, on voit en détail ce qu’est Optuna, la librairie qui te permet d’optimiser tes Modèles de Machine Learning en 2 clics.
Optuna est une librairie permettant l’optimisation automatique des hyperparamètres de tes modèles de Machine Learning.
Elle te permet d’identifier facilement les hyperparamètres optimaux en effectuant plusieurs essais avec différentes combinaisons d’hyperparamètres.
Les hyperparamètres jouent un rôle crucial dans :
- les prédictions finales de ton modèle
- sa capacité à s’adapter
- sa capacité à généraliser
C’est pourquoi Optuna, utilisée à bon escient, peut considérablement augmenter les performances de tes modèles.
Rentrons dans le détails ! 🧐
Optuna – Comment ça marche ?
L’idée de base
L’idée derrière Optuna est simple : fournir un espace d’hyperparamètres à tester pour déterminer la combinaison d’hyperparamètres qui optimisent ton modèle.
Tout d’abord, tu dois donner une métrique de performance à Optuna.
Son objectif sera de l’optimiser.
Par exemple, si tu lui donne la loss, son objectif sera de la minimiser pour qu’elle s’approche le plus possible de 0.
Ensuite, il faut lui donner un espace de recherche pour les hyperparamètres que tu veux investiguer.
Par exemple, si tu veux tester le nombre de couches cachées, tu peux lui dire de tester une plage de 1 à 10 couches cachées.
Le module testera chacune des possibilités pour déterminer le meilleur nombre de couches selon la métrique de performance précédemment indiquer, la loss.
Tu peux aussi indiquer plusieurs paramètres à la fois.
Par exemple, le nombre de couches cachées ET le learning rate.
Optuna lancera alors une série de tests, au bout desquels, elle te donnera les valeurs des hyperparamètres pour lequel ta métrique est optimale.
À noter que tu peux indiquer plusieurs métriques à optimiser en même temps, comme la loss ET l’accuracy.
Les avantages d’Optuna
Voici les principaux avantages de la librairie Optuna :
- Facilité : elle possède une API simple qui permet aux utilisateurs de définir la métrique à optimiser et l’espace d’hyperparamètres à investiguer. Pour exécuter le processus d’optimisation il suffit d’un seul appel de fonction.
- Scalibilité : elle est conçu pour s’adapter aux problèmes d’optimisation de grande échelle, grâce à la prise en charge de la parallélisation des tests et de la désactivation (pruning) des essais infructueux.
- Flexibilité : elle prend en charge un large choix d’algorithmes d’optimisation, notamment le Random Search, le Grid Search et l’optimisation Bayésienne.
- Adaptabilité – Framework : elle prend en charge l’optimisation de modèles de Machine Learning implémentés dans de multiple frameworks : PyTorch, TensorFlow et scikit-learn.
- Adaptabilité – Hyperparamètres : elle prend en charge l’optimisation d’hyperparamètres continus, entiers et catégoriels, ainsi que des hyperparamètres présentant des dépendances complexes (la valeur optimale d’un hyperparamètre peut dépendre des valeurs d’autres hyperparamètres).
Passons à ma partie préférée, la pratique ! ☄️
Comment utiliser Optuna en Python
Pour utiliser Optuna, il te faudra tout d’abord l’installer avec la commande pip :
!pip install optunaEnsuite, on va charger des données.
Nos données
N’importe quelles données feront l’affaire, l’objectif de cet article n’étant pas de mener a bien un projet mais de voir comment utiliser Optuna.
Ici on utilise le dataset de Keras « Reuters ». Le but est de classifier chaque news dans une ou plusieurs catégories en fonction de son contenu.
C’est un problème classique de NLP, multi-classe.
Chargeons le dataset :
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.reuters.load_data(path="reuters.npz")Les news sont déjà tokeniser, on a plus qu’a normaliser chacune des news :
X_train = tf.keras.utils.pad_sequences(X_train, maxlen=max_len)
X_test = tf.keras.utils.pad_sequences(X_test, maxlen=max_len)Ici on focus sur Optuna mais si tu souhaite en savoir plus sur le preprocessing en NLP, on rentre dans le détails dans cet article.
Là ça va se compliquer !
On va créer une fonction définissant deux choses :
- les hyperparamètres à optimiser
- la création du modèle grâce à ces hyperparamètres
Optuna
Pour définir l’espace d’un hyperparamètre à investiguer on utilise une des ces fonctions selon le type de nos variables :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
- suggest_categorical – Suggère une valeur pour un hyperparamètre catégorique.
- suggest_discrete_uniform – Suggère une valeur pour un hyperparamètre discret.
- suggest_float -Suggère une valeur pour un hyperparamètre à virgule flottante.
- suggest_int – Suggère une valeur pour un hyperparamètre entier.
- suggest_loguniform – Suggère une valeur pour un hyperparamètre continu.
- suggest_uniform – Suggère une valeur pour un hyperparamètre continu.
Par exemple pour le nombre de couches cachées, on aura :
N’exécute pas cette ligne c’est un exemple.
n_hidden = trial.suggest_int('n_hidden', 1, 3)Ici on teste 1, 2 et 3 couches cachées pour déterminer le nombre qui optimise notre métrique.
Il faut ensuite adapté la création du modèle.
Par exemple, vu qu’on a potentiellement N (1, 2 ou 3) couches cachées, il faut créer une boucle qui prend en compte le fait que N peut être varier :
for i in range(n_hidden):
model.add(Dense(50, activation='relu'))Voilà le code complet de la création du modèle qui prend en compte 3 hyperparamètres :
- Entre 1 et 3 couches cachées
- Entre 32 et 128 neurones par couches
- Un learning rate entre 0.00001 et 0.1
def create_model(trial):
# Some hyperparameters we want to optimize
n_hidden = trial.suggest_int('n_hidden', 1, 3)
n_units = trial.suggest_int('n_units', 32, 128)
learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-1)
model = Sequential()
model.add(Dense(n_units, input_dim=X_train.shape[1], activation='relu'))
for i in range(n_hidden):
model.add(Dense(n_units, activation='relu'))
model.add(Dense(y_train[0].size, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
metrics=['accuracy'])
return modelEnsuite, on peut créer la fonction objective().
Dedans, on utilise la fonction que l’on vient de créer : create_model().
Puis on entraîne le modèle.
On extrait la métrique que l’on veut optimiser.
Dans notre cas on choisis la loss qu’on place dans la variable score.
Optuna va optimiser ce que retourne cette fonction (la variable score) :
def objective(trial):
model = create_model(trial)
model.fit(X_train, y_train,
epochs=10,
batch_size=32,
validation_split=0.2,
verbose=0)
score = model.evaluate(X_test, y_test, verbose=0)[1]
return scoreOn crée un objet Study qui va nous permettre de stocker les résultats de l’investigation d’Optuna :
import optuna
study = optuna.create_study()Et finalement on lance l’investigation sur 100 essais grâce à la fonction optimize() :
study.optimize(objective, n_trials=100, n_jobs=-1)Sortie : Trial 0 finished with value: 0.0467497780919075 and parameters: {‘n_hidden’: 2, ‘n_units’: 119, ‘learning_rate’: 0.005641381456976518}. Best is trial 1 with value: 0.0467497780919075.
Optuna va ainsi tester 100 différentes combinaisons de nos hyperparamètres, indiqués dans la fonction create_model().
Résultats
À la fin de l’investigation, on peut afficher la meilleure combinaison d’hyperparamètres :
print(study.best_params)Sortie : {‘n_hidden’: 3, ‘n_units’: 121, ‘learning_rate’: 0.019243253125586307}
Pour notre modèle, Optuna a trouver que la meilleur combinaison est :
- 3 couches cachées
- 121 neurones par couches
- Un learning rate de 0.019
On peut aussi afficher sous forme de graph le résultat de chacun des essais d’Optuna:
from optuna.visualization import plot_optimization_history
plot_optimization_history(study)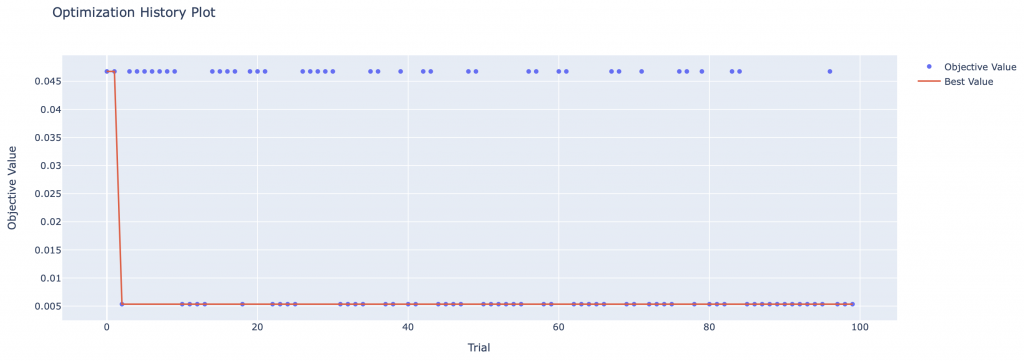
On peut utiliser la combinaison optimal trouvée par Optuna pour créer un modèle :
best_model = create_model(study.best_trial)Et l’utiliser sur nos données test :
best_model.evaluate(X_test, y_test)[1]Sortie : 0.046
On obtient une loss de 0.046, pas mal !
Et toi ? Quel score tu as eu ?
Malgré tout, garde à l’esprit que la librairie Optuna ne te donne pas LE meilleur modèle.
Elle te donne le meilleur modèle qu’elle a trouvé en fonction de :
- ses essais – Optuna ne teste pas l’ensemble des possibilités mais seulement un nombre restreint que tu lui indique (n_trials)
- l’espace d’hyperparamètres que tu lui as donné – Optuna n’investigue pas l’ensemble des hyperparamètres mais seulement ceux que tu lui donne
À bientôt sur Inside Machine Learning 😉
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



