

In this article, we see what Optuna is, the library that enables you to optimize your Machine Learning Models in a blink of an eye.
Optuna is a library that allows the automatic optimization of the hyperparameters of your Machine Learning models.
It allows you to easily identify the optimal hyperparameters by performing several tests with different combinations of hyperparameters.
Hyperparameters play a crucial role in :
- the final predictions of your model
- its ability to adapt
- its ability to generalize
That’s why Optuna, when used properly, can considerably increase the performance of your models.
Let’s get into the details! 🧐
Optuna – How does it work?
The basic idea
The idea behind Optuna is simple: provide a space of hyperparameters to test in order to determine the combination of hyperparameters that optimize your model.
First, you need to give Optuna a performance metric.
Its objective will be to optimize it.
For example, if you give it the loss, its goal will be to minimize it so that it comes as close to 0 as possible.
Then you have to give it a search space for the hyperparameters you want to investigate.
For example, if you want to test the number of hidden layers, you can tell it to test a range from 1 to 10 hidden layers.
The module will test each of the possibilities to determine the best number of layers according to the previously specified performance metric, loss.
You can also specify several parameters at once.
For example, the number of hidden layers AND the learning rate.
Optuna will then launch a series of tests, at the end of which, it will give you the hyperparameters values that optimize your metric.
Note that you can specify several metrics to optimize at the same time, such as loss AND accuracy.
Optuna’s advantages
Here are the main advantages of the Optuna library:
- Ease of Use: it has a simple API that allows users to define the metric to be optimized and the hyperparameter space to be investigated. It takes only one function call to execute the optimization process.
- Scalability: it is designed to adapt to large-scale optimization problems, thanks to the support of test parallelization and pruning of unsuccessful tests.
- Flexibility: it supports a wide range of optimization algorithms, including Random Search, Grid Search, and Bayesian optimization.
- Adaptability – Framework: it supports the optimization of Machine Learning models implemented in multiple frameworks: PyTorch, TensorFlow and scikit-learn.
- Adaptability – Hyperparameters: it supports optimization of continuous, integer and categorical hyperparameters, as well as hyperparameters with complex dependencies (the optimal value of a hyperparameter may depend on the values of other hyperparameters).
Let’s move on to my favorite part, the practice! ☄️
How to use Optuna in Python
To use Optuna, you will first have to install it with the pip command:
!pip install optunaThen, we will load some data.
Our data
Any data will do the job, the objective of this article is not to carry out a project but to see how to use Optuna.
Here we use the Keras dataset “Reuters”. The goal is to classify each news in one or more categories according to its content.
This is a classic NLP problem, multi-class.
Let’s load the dataset:
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.reuters.load_data(path="reuters.npz")The news are already tokenized, we just have to normalize each of the news:
X_train = tf.keras.utils.pad_sequences(X_train, maxlen=max_len)
X_test = tf.keras.utils.pad_sequences(X_test, maxlen=max_len)Here we focus on Optuna but if you want to know more about NLP preprocessing, we go into detail in this article.
Now it’s going to be more tricky!
We will create a function defining two things :
- the hyperparameters to optimize
- the creation of the model thanks to these hyperparameters
Optuna
To define the space of a hyperparameter to investigate we use one of these functions depending on the type of our variables:
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
- suggest_categorical – Suggest a value for the categorical parameter.
- suggest_discrete_uniform – Suggest a value for the discrete parameter.
- suggest_float -Suggest a value for the floating point parameter.
- suggest_int – Suggest a value for the integer parameter.
- suggest_loguniform – Suggest a value for the continuous parameter.
- suggest_uniform – Suggest a value for the continuous parameter.
For example for the number of hidden layers, we will have :
Do not execute this line, it is an example.
n_hidden = trial.suggest_int('n_hidden', 1, 3)Here we test 1, 2 and 3 hidden layers to determine the number that optimizes our metric.
Then we have to adapt the creation of the model.
For example, since we have potentially N (1, 2 or 3) hidden layers, we must create a loop that takes into account the fact that N can vary:
for i in range(n_hidden):
model.add(Dense(50, activation='relu'))Here is the complete code of the model creation which takes into account 3 hyperparameters:
- Between 1 and 3 hidden layers
- Between 32 and 128 neurons per layer
- A learning rate between 0.00001 and 0.1
def create_model(trial):
# Some hyperparameters we want to optimize
n_hidden = trial.suggest_int('n_hidden', 1, 3)
n_units = trial.suggest_int('n_units', 32, 128)
learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-1)
model = Sequential()
model.add(Dense(n_units, input_dim=X_train.shape[1], activation='relu'))
for i in range(n_hidden):
model.add(Dense(n_units, activation='relu'))
model.add(Dense(y_train[0].size, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
metrics=['accuracy'])
return modelobjective function
Then, we can create the objective() function.
Inside, we use the function we have just created: create_model().
Then we train the model.
We extract the metric we want to optimize.
In our case we choose the loss that we place in the score variable.
Optuna will optimize what this function returns (the score variable):
def objective(trial):
model = create_model(trial)
model.fit(X_train, y_train,
epochs=10,
batch_size=32,
validation_split=0.2,
verbose=0)
score = model.evaluate(X_test, y_test, verbose=0)[1]
return scoreWe create a Study object that will allow us to store the results of the Optuna investigation:
import optuna
study = optuna.create_study()And finally we launch the investigation on 100 trials with the optimize() function:
study.optimize(objective, n_trials=100, n_jobs=-1)Output : Trial 0 finished with value: 0.0467497780919075 and parameters: {‘n_hidden’: 2, ‘n_units’: 119, ‘learning_rate’: 0.005641381456976518}. Best is trial 1 with value: 0.0467497780919075.
Optuna will test 100 different combinations of our hyperparameters, specified in the create_model() function.
Results
At the end of the investigation, we can display the best combination of hyperparameters:
print(study.best_params)Output : {‘n_hidden’: 3, ‘n_units’: 121, ‘learning_rate’: 0.019243253125586307}
For our model, Optuna found that the best combination is :
- 3 hidden layers
- 121 neurons per layer
- A learning rate of 0.019
We can also display in graph form the result of each of Optuna’s trials:
from optuna.visualization import plot_optimization_history
plot_optimization_history(study)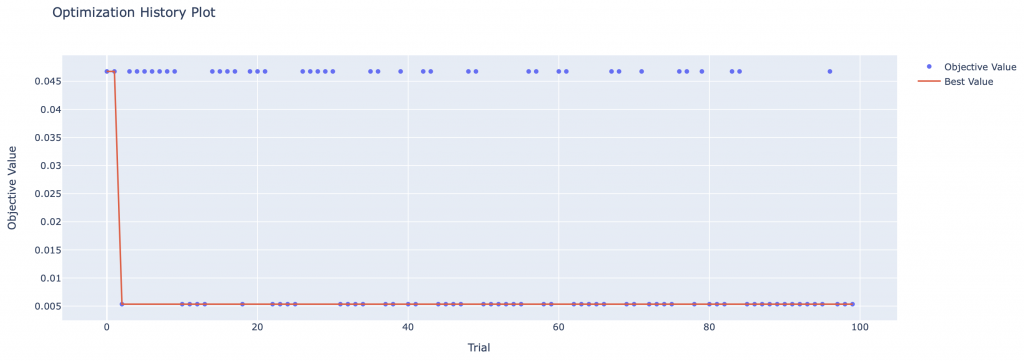
We can use the optimal combination found by Optuna to create a model:
best_model = create_model(study.best_trial)And use it on our test data:
best_model.evaluate(X_test, y_test)[1]Output: 0.046
We get a loss of 0.046, not bad!
What about you ? What score did you get?
However, keep in mind that the Optuna bookshop does not give you THE best model.
It gives you the best model it has found based on :
- its tests – Optuna does not test all the possibilities but only a limited number that you indicate(n_trials)
- the space of hyperparameters you gave – Optuna doesn’t investigate all the hyperparameters but only the ones you give it
See you soon on Inside Machine Learning 😉
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



