

Le Feature Engineering, c’est la grande différence entre Machine Learning et Deep Learning mais… qu’est-ce que c’est au juste ?
J’ai récemment vu sur Google Trends qu’une des phrase les plus recherchée sur internet au sujet de l’IA est « quelle est la différence entre Machine Learning et Deep Learning ? »… à vrai dire, aucune des explications que j’ai trouvé jusqu’alors m’ont satisfait.
C’était sans compter sur Deep Learning with PyTorch, un livre que je viens de commencer et qui explique certains concepts de Deep Learning.
La différence entre le Machine et le Deep Learning est en fait assez simple. L’un nécessite que l’utilisateur transforme la donnée en une bonne représentation tandis que l’autre trouve la bonne représentation de cette donnée par lui-même.
Souvent, ces représentations conçues automatiquement sont bien meilleures que celles réalisées à la main et c’est çà l’avantage du Deep Learning !
Feature Engineering ce qui fait la différence entre Machine et Deep Learning
Qu’est-ce que le feature engineering ?
Feature Engineering est un mot compliqué pour dire une chose simple.
Concrètement :
Feature Engineering = nettoyage des données
Ce nettoyage comporte plusieurs étapes que nous allons aborder à travers un rapide exemple de Machine Learning !
Ici, notre objectif est de prédire le nombre de tablette de chocolat que vendra notre épicerie ce mercredi.
Voilà les données à notre disposition :
| Jour | Pourcentage de Cacao par Tablette | Nombre de Client | Promo -20% | Vente |
| Lundi | 70 | 10 | Oui | 8 |
| Mardi | 70 | 15 | Non | 6 |
| Mercredi | 70 | 13 | Oui | ? |
Réaliser le Feature Engineering
Étape 1 : Analyser les caractéristiques des données
Premièrement on analyse les données, on regarde quelles caractéristiques sera importantes pour une prédiction.
Dans notre cas, la colonne Promo -20% comporte uniquement des données texte. L’algorithme ne comprends pas ce type données, on doit donc les modifier.
C’est là qu’est le Feature Engineering, littéralement Ingénierie des Caractéristiques : nous devons changer les caractéristiques, les variables de notre jeu de données.
Étape 2 : Déterminer une représentation des données
Pour interpréter la donnée, le ML a besoin de chiffre. Dans la colonne Promo -20% seulement deux choix sont possible, « oui » ou « non ».
On peut donc aisément décider de changer le « oui » en 0 et le « non » en 1.
Étape 3 : Modifier la donnée
Une fois qu’on a fait ce travail intellectuel de compréhension de la donnée, il faut concrétiser cette décision en codant.
Dans notre cas, la tâche est assez simple, on peut facilement faire une boucle for sur l’ensemble du tableau pour modifier chaque « oui » en 0 et chaque « non » en 1.
Cependant, si au lieu d’un choix binaire (« oui » ou « non ») on aurait eu une phrase entière à chaque ligne du tableau, il aurait été plus difficile de trouver une bonne représentation. On aborde justement ce sujet dans cet article qui vous explique comment rendre compréhensible par une machine le langage humain.
Dans notre exemple sur les tablettes de chocolat, nous avons expressément choisis un exemple simple mais il faut savoir qu’habituellement le Feature Engineering est la tâche la plus complexe qu’effectue le Data Scientist.
Effectivement dans cette étude, réalisée par Forbes, on peut voir que 60% du travail d’un Data Scientist consiste au nettoyage et à l’organisation de la donnée (le Feature Engineering) !
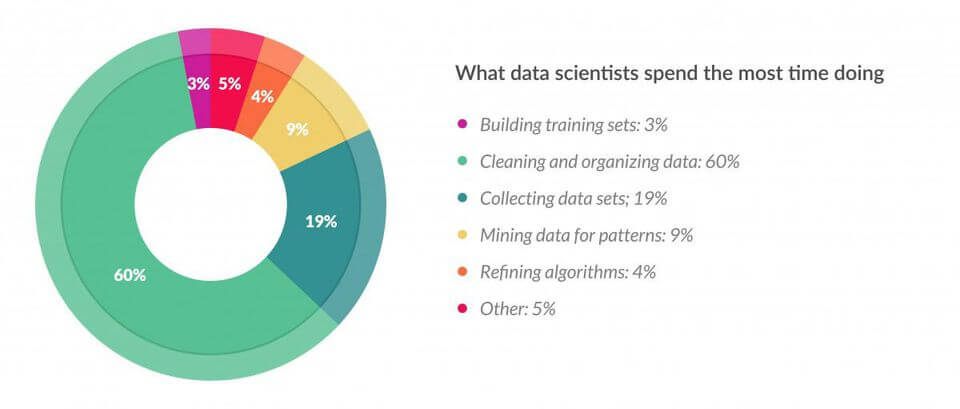
Analyser le Feature Engineering
Étape 4 : Choisir et utiliser notre modèle de Machine Learning
Ensuite, on peut choisir notre modèle de Machine Learning et l’utiliser.
Le choix de ce modèle mériterait un article (même plusieurs) à part entière, nous n’allons donc pas l’aborder ici.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Cette étape est néanmoins, avec le feature engineering, une des plus importantes dans la réalisation d’un bon algorithme de Machine Learning.
Étape 5 : Analyser le résultat
Une fois qu’on a réalisé la prédiction avec notre modèle de ML, il nous faut analyser le résultat et bien souvent… il ne sera pas optimal.
C’est là toute l’arduosité de cette tâche.
Pour améliorer notre prédiction il faudra retourner à l’étape 1, analyser à nouveau les données pour les modifier.
Dans notre cas on peut imaginer que le Pourcentage de Cacao par Tablette n’influence pas le nombre de vente étant donnée qu’il ne change pas au fil des jours. Alors on peut l’enlever et relancer le processus pour analyser à nouveau le résultat.
On en revient à l’adage du Machine Learning : expérimenter !
Il faut expérimenter, tester de nouvelles manières de faire. Même si je conseil a tous débutants de comprendre les concepts du Machine Learning.. bien souvent dans ce domaine la pratique a raison de la théorie.
(À savoir : ici on se concentre sur le Feature Engineering mais le choix du modèle a lui aussi une influence sur la qualité de la prédiction 😉 )
La fin du Feature Engineering ? – différence entre Machine et Deep Learning
Plus haut, on a dit que la différence entre le Machine Learning est le Deep Learning est le Feature Engineering mais soyons clair : il faut effectuer le Feature Engineering pour les deux types d’apprentissages.
En fait, la différence se trouve dans le degré de Feature Engineering a effectuer. Le Deep Learning en nécessite beaucoup moins.
C’est là l’avantage du Deep Learning.
Par exemple, dans cet article, on a utilisé du Deep Learning pour classer des images.
Une image représentait soit un chien, soit un chat.
Eh bien, le seul Feature Engineering que l’on a effectué fut de transformer ces images en chiffres interprétable par le modèle.
Avec du Machine Learning, on aurait dû faire des aller-retours entre nos données et notre prédiction pour trouver une bonne représentation.
Avec le Deep Learning au contraire, il suffit de rendre interprétable nos données (données numériques). Ensuite, le modèle se charge seul de trouver les représentations qui lui permettent d’accomplir sa prédiction.
Souvent, ce Feature Engineering réalisé automatiquement est bien meilleur que celui fait manuellement. C’est ce qui rend le Deep Learning si puissant !
En résumé la différence entre Machine Learning et Deep Learning
Pour du Machine Learning, le Feature Engineering est entièrement fait par le Data Scientist.
Alors que pour du Deep Learning, le Feature Engineering est fait en majeur partie par le modèle de Deep Learning lui-même, seule une part minime de ce travail est laissée au Data Scientist.
Sur internet, la plupart des articles dise que ce travail de Feature Engineering réalisé par le Deep Learning est une Boîte Noire car « on ne voit pas ce qu’il se passe à l’intérieur ».
Je ne suis pas d’accord avec ce concept de Boîte Noire, dans cet article par exemple, on peut voir comment un Réseau de Neurones (Deep Learning) fait ses choix pour une prédiction.
Cela implique donc que ce n’est pas une Boîte Noire car le fait est qu’on peut voir ce qu’il se passe à l’intérieur.
Je dirai à la place que, pour certains Réseau de Neurones, il y a tellement de paramètres (des millions voir des milliards) qu’analyser l’algorithme est concrètement irréalisable par un humain.
Le Feature Engineering c’est donc la différence fondamentale entre le Machine Learning et le Deep Learning
Maintenant, si tu veux aller plus loin et apprendre le Deep Learning – j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j’ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
Sources:
- L. Antiga, Deep Learning with PyTorch (2020, Manning Publications)
- Photo by ThisisEngineering RAEng on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :




explication très très simple et très bonne je vous remercie beaucoup