

Feature Engineering is the big difference between Machine Learning and Deep Learning but… what is it exactly ?
I recently saw on Google Trends that one of the most searched sentence on the internet about AI is “what is the difference between Machine Learning and Deep Learning?”… to be honest, none of the explanations I found so far satisfied me.
That was without counting on Deep Learning with PyTorch, a book I just started that explains some Deep Learning concepts.
La différence entre le Machine et le Deep Learning est en fait assez simple. L’un nécessite que l’utilisateur transforme la donnée en une bonne représentation tandis que l’autre trouve la bonne représentation de cette donnée par lui-même.
Souvent, ces représentations conçues automatiquement sont bien meilleures que celles réalisées à la main et c’est çà l’avantage du Deep Learning !
The difference between Machine and Deep Learning is actually quite simple. One requires the user to transform the data into a good representation while the other finds the right representation of the data by itself.
Often, these automatically designed representations are much better than those made by hand and that’s the strength of Deep Learning !
Feature Engineering what makes the difference between Machine and Deep Learning
What is feature engineering ?
Feature Engineering is a complicated word for a simple thing.
In practical terms :
Feature Engineering = data cleaning
This cleaning involves several steps that we will approach through a quick example of Machine Learning !
Here, our objective is to predict the number of chocolate bars that our grocery store will sell this Wednesday.
Here is the data at hand :
| Day | Percentage of Cocoa per Bar | Number of Customers | Promo -20% | Sale |
| Monday | 70 | 10 | Yes | 8 |
| Tuesday | 70 | 15 | No | 6 |
| Wednesday | 70 | 13 | Yes | ? |
Performing Feature Engineering
- Step 1 : Analyze the characteristics of the data
First we analyze the data, we see which features will be important for a prediction.
In our case, the Promo -20% column contains only text data. The algorithm does not understand this type of data, so we have to modify it.
This is where Feature Engineering comes in : we need to change the features, the variables in our dataset.
- Step 2 : Establish a data representation
In order to interpret the data, ML needs numbers. In the Promo -20% column only two choices are possible, “yes” or “no”.
So we can easily decide to change the “yes” to 0 and the “no” to 1.
- Step 3 : Modify the data
Once we have done this intellectual work of understanding the data, we must concretize this decision by coding.
In our case, the task is quite simple, we can easily make a for loop on the whole table to modify each “yes” in 0 and each “no” in 1.
However, if instead of a binary choice (“yes” or “no”) we would have had a whole sentence for each row of the table, it would have been more difficult to find a good representation. This is the subject of this article, which explains how to make human language understandable by a machine.
In our example on chocolate bars, we have expressly chosen a simple example but it is important to know that Feature Engineering is usually the most complex task performed by the Data Scientist.
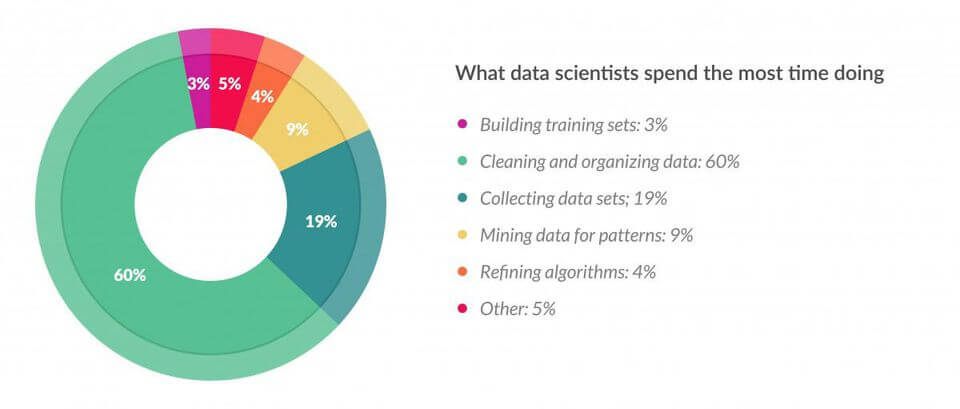
In fact, in this study, carried out by Forbes, we can see that 60% of a Data Scientist’s work consists of cleaning and organizing the data (Feature Engineering) !
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
Analyzing Feature Engineering
- Step 4 : Choose and use our Machine Learning model
Next, we can choose our Machine Learning model and use it.
The choice of this model would deserve an article (even several) of its own, so we won’t deal with it here.
This step is nevertheless, along with feature engineering, one of the most important in the realization of a good Machine Learning algorithm.
- Step 5 : Analyze the result
Once we have made the prediction with our ML model, we need to analyze the result and very often… it will not be optimal.
This is the difficulty of this task.
To improve our prediction we will have to go back to step 1, analyze the data again and modify it.
In our case we can imagine that the Percentage of Cocoa per Bar does not influence the number of sales since it does not change over the days. So we can remove it and restart the process to analyze the result again.
We come back to the Machine Learning adage: experiment !
We must experiment, test new ways of doing things. Even if I advise all beginners to understand the concepts of Machine Learning… often in this field the practice is better than the theory.
(To know : here we focus on Feature Engineering but the choice of the model also has an influence on the quality of the prediction 😉 )
The difference with Deep Learning
The end of Feature Engineering ?
Above, we said that the difference between Machine Learning and Deep Learning is Feature Engineering but let’s be clear: Feature Engineering must be performed for both types of learning.
In fact, the difference lies in the degree of Feature Engineering to be performed. Deep Learning requires much less.
This is the benefit of Deep Learning.
For example, in this article for French speakers, we used Deep Learning to classify images.
One image was either a dog or a cat.
Well, the only Feature Engineering we did was to transform these images into digits that could be interpreted by the model.
With Machine Learning, we would have to go back and forth between our data and our prediction to find a good representation.
With Deep Learning, on the contrary, we only need to make our data (numerical data) interpretable. Then, the model takes care of finding the representations that allow it to accomplish its prediction.
Often, this automatic Feature Engineering is much better than the one done manually. This is what makes Deep Learning so powerful !
To sum up the difference between Machine Learning and Deep Learning
For Machine Learning, the Feature Engineering is entirely done by the Data Scientist.
While for Deep Learning, the Feature Engineering is mostly done by the Deep Learning model itself, only a few part of this work is left to the Data Scientist.
On the internet, most of the articles say that this Feature Engineering work done by Deep Learning is a Black Box because “you can’t see what’s going on inside”.
I don’t agree with this concept of Black Box, in this article for example, we can see how a Neural Network (Deep Learning) makes its choices for a prediction.
This implies that it is not a Black Box because the fact is that we can see what is going on inside.
I would say instead that, for some Neural Networks, there are so many parameters (millions or even billions) that analyzing the algorithm is practically impossible for a human.
To go further…
Well… Feature Engineering… that was before 2019.
Recently Google released a new library : AutoKeras.
With this library, there is no need to perform Feature Engineering anymore !
This is what I show you in this article that I strongly recommend you to read.
You don’t even need to do text preprocessing or even choose a model or neural layers.
On top of that… this library does better than most models in only three lines of code.
In a word : the future !
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



