Comment coder un algorithme de Deep Learning pour la détection d’objet avec la bibliothèque PyTorch ? Nous allons voir maintenant !
Cette article fait partie d’une série sur les modèles de Classification Binaire en PyTorch avec :
- une première partie sur la normalisation (accessible ici)
- une deuxième partie sur les modèles de Deep Learning
Nous allons reprendre les données de la première partie, n’hésitez pas à la consulter avant de continuer la lecture
Continuons cette série en nous intéressant à la création et l’entraînement d’un modèle de Deep Learning avec PyTorch.
Construire un Modèle PyTorch
La classe Net()
Comme vous le savez Python est un langage de programmation orienté objet, c’est-à-dire qu’en Python nous pouvons(devons… ?) créer nos propres objets et fonctions.
En ce sens, on dit que PyTorch est ‘pythonique’ : il reprend les même principes que la programmation orienté objet de Python.
Là où avec Keras nous pouvons appeler les fonctions assez facilement, avec PyTorch il faudra dans la plupart des cas créer des objets… et c’est une bonne nouvelle !
Pour les non habitué à l’orienté objet cela peut sembler déroutant mais plus tôt on rentre dedans, plus tôt on pourra créer nos propres objets, nos propres bibliothèques et s’adapter à toutes les situations !
Si vous voulez en apprendre plus sur l’orienté objet en Python je vous recommande ce site.
Pour les autres, continuons ! 🙂
Nous allons construire une classe (class) qui permettra d’initaliser un réseau de neurones en tant qu’objet.
Pour cela on définit un constructeur (init) : à l’appel de l’objet, nous obtiendrons une variable qui contient chacun des attributs indiqués dans ce constructeur. C’est ici qu’on définit les couches entièrement connectées (fully connected) de notre réseau de neurones.
Puis on définit une fonction qui va permet d’activer notre modèle : la fonction forward. Elle permet de relier les différentes couches entre elles et ainsi transmettre les données le long du réseau de neurones.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 8, kernel_size=3, padding=1)
self.fc1 = nn.Linear(8 * 8 * 8, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = F.max_pool2d(torch.tanh(self.conv1(x)), 2)
out = F.max_pool2d(torch.tanh(self.conv2(out)), 2)
out = out.view(-1, 8 * 8 * 8)
out = torch.tanh(self.fc1(out))
out = self.fc2(out)
return outExplication
Notre objet est un fils du module nn.Module cela est spécifié lorsque l’on écrit Net(nn.Module) et lors de l’appel de la fonction super().
Dit autrement super() relie notre objet Net() à la classe nn.Module (qui devient son parent).
Ensuite on appelle toutes les couches fully connected dans notre constructeur : les couches de convolutions et les couches linéaires.
Puis on relie entre elles ces couches avec les couches de Max Pooling, out.view (l’équivalent de Flatten en Keras), ainsi que les fonctions d’activations (ici tanh).
Même si notre modèle n’est pas encore entraîner on peut l’utiliser pour voir si tout ce passe bien.
Pour cela on définit un tenseur au hasard que le passer dans notre modèle :
import torch
random_tensor = torch.rand((1, 3, 32, 32))
nn_test = Net()
result = nn_test(random_tensor)
print(result)On a bien en sortie deux float qui, une fois que le modèle sera entraîné, correspondront chacun à la probabilité d’être dans la classe ‘cerf’ et dans la classe ‘cheval’.

Entraîner un Modèle PyTorch
Avec CPU
Boucle d’entraînement
Sous PyTorch il n’y a pas d’équivalent à Keras.fit(), il faut créer soi-même sa training loop.
Cette boucle d’entraînement est expliqué en détail dans cet article à l’étape 3.
import datetime
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs + 1):
loss_train = 0.0
for imgs, labels in train_loader:
outputs = model(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch % 10 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch,
loss_train / len(train_loader)))En fait le processus est assez simple. À chaque epoch il faut initialiser la loss (loss_train) à 0. Puis :
- Utiliser le modèle sur nos données (faire une prédiction)
- Calculer la loss (l’erreur entre nos prédictions et la réalité)
- Mettre le gradient à zéro
- Calculer la backpropagation (calcul du gradient)
- Mettre à jour les paramètres (via le gradient)
- Mettre à jour la loss (loss_train) global
Ensuite on peut afficher le résultat à chaque epoch. Ici on le fait tous les 10 epochs.
Pour cela on divise la loss global par la longueur de notre dataset.
L’entraînement
On initialise nos trois objets principales :
- le modèle
- la fonction d’optimisation (ici on prend la classique Stochastique Gradient Descent) )
- la loss fonction
import torch.optim as optim
model = Net()
optimizer = optim.SGD(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()Ensuite pour ce qui est des données, nous allons utiliser un objet très spécial appelé DataLoader.
Lors de l’entraînement d’un modèle, nous souhaitons généralement transmettre nos données en batchs (lot de données), mélanger les données à chaque epoch pour réduire l’overfitting du modèle et utiliser le multitraitement (multiprocessing) de Python pour accélérer les calculs.
DataLoader est un objet itérable qui simplifie cette tâche pour nous dans un module (aussi appelée API) simple.
import torch
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=True)
val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=64,
shuffle=False)On peut enfin entraîner notre modèle en indiquant les paramètres souhaités dans notre training loop !
training_loop(
n_epochs = 100,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader)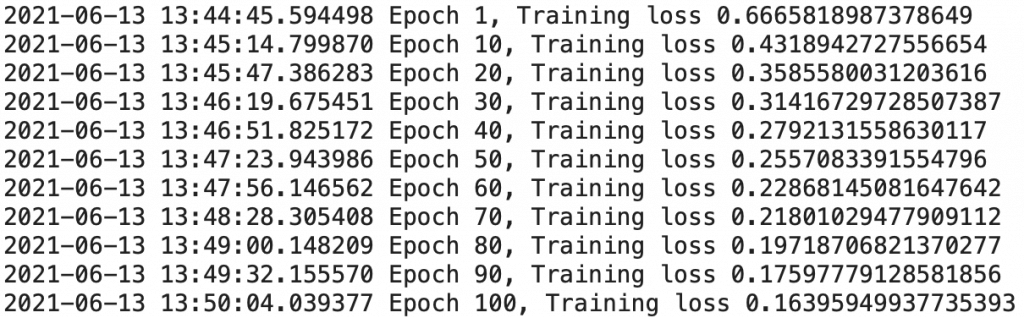
Notre entraînement est terminé. On obtient une loss de 0.151, plutôt pas mal pour un premier entraînement !
Et si on poussait l’analyse de performance un peu plus loin ?
La validation
Dans la fonction suivante, on calcule la précision du modèle sur nos données d’entraînement et sur nos données de validation, pour vérifier qu’il n’y est pas d’overfitting.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
L’overfitting, c’est le fait qu’un modèle se spécialise tellement sur ses données d’entraînement qu’il devient inefficace sur d’autres données, des données réelles. On appelle aussi ce phénomène le surapprentissage.
def validate(model, train_loader, val_loader):
for name, loader in [("train", train_loader), ("val", val_loader)]:
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in loader:
outputs = model(imgs)
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels).sum())
print("Accuracy {}: {:.2f}".format(name , correct / total))Pour chaque batch de nos DataLoader (train & val), la fonction regarde le nombre de prédiction bonne.
validate(model, train_loader, val_loader)On obtient 0.92 pour le train et 0.88 pour le val.
En plus d’être très proches (ce qui indique qu’il n’y a pas d’overfitting), ces précision sont aussi vraiment haute, notre modèle de Deep Learning est particulièrement efficace pour cette classification !
Sauvegarder / Charger les poids
On peut alors sauvegarder les poids de notre modèle pour l’utiliser ailleurs sans avoir à l’entraîner à nouveau ! 🙂
torch.save(model.state_dict(), 'birds_vs_airplanes.pt')Et voilà le code pour l’utiliser dans un autre programme.
Remarquez qu’il faudra aussi transférer notre réseau de neurones, l’objet Net().
loaded_model = Net()
loaded_model.load_state_dict(torch.load('birds_vs_airplanes.pt'))Et voilà ! On peut maintenant utiliser notre modèle de Deep Learning partout !

Avec GPU
Initialiser le GPU
Avec PyTorch, on peut accélerer le temps d’entraînement de notre modèle de Deep Learning si l’on a un GPU.
Le Graphics Processing Unit ou processeur graphique permet de faire plusieurs calculs en même temps, en parallèle. Dit simplement, un GPU permet d’accélèrer grandement le temps de calcul, idéal pour faire du Deep Learning !
On rappelle que vous pouvez accéder gratuitement à un GPU en utilisant Google Colab 😉
Après avoir modifié les paramètres d’Exécution dans Colab, il faut utiliser cette brique de code pour utiliser le GPU cuda avec PyTorch:
device = (torch.device('cuda') if torch.cuda.is_available()
else torch.device('cpu'))
print(f"Training on device {device}.")L’entraînement
Une fois qu’on a initialiser le GPU, il ne nous reste plus qu’à indiquer à PyTorch que nous voulons que les calculs soient réalisé dessus dans notre training loop.
Pour cela on utilise la fonction to().
Lorsqu’on code : imgs.to(torch.device(‘cuda’)); on indique à PyTorch de réaliser les calculs du tenseur imgs sur le GPU ‘cuda’.
Par défaut, les tenseurs PyTorch sont calculés sur CPU.
import datetime
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs + 1):
loss_train = 0.0
for imgs, labels in train_loader:
imgs = imgs.to(device=device)
labels = labels.to(device=device)
outputs = model(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch % 10 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch,
loss_train / len(train_loader)))On remarque que le code est exactement comme notre version sur CPU, à l’exception des deux lignes qui transfère les entrées ‘imgs’ et ‘labels’ vers le GPU.
Lors de l’appel de l’objet Net() il faut aussi spécifier le transfère vers GPU :
import torch.optim as optim
model = Net().to(device=device)
optimizer = optim.SGD(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()Les données du DataLoader seront transférer vers le GPU dans chaque epoch, on laisse donc l’initilisation inchangée :
import torch
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=True)
val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=64,
shuffle=False)On lance l’entraînement qui, on peut le voir, est bien plus rapide que sur CPU !
training_loop(
n_epochs = 100,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader)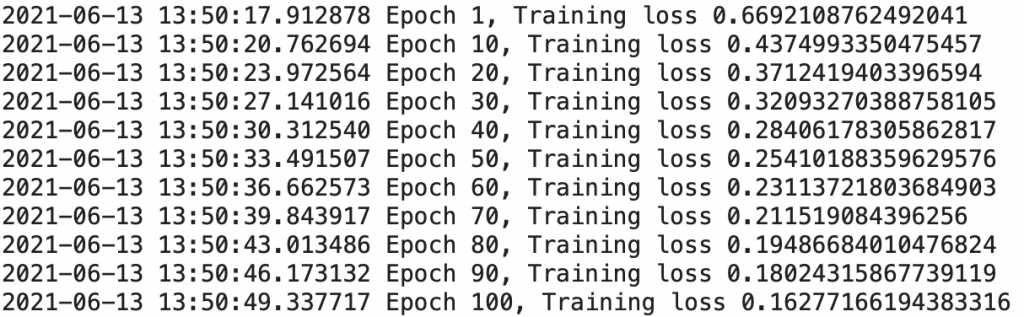
Il faut aussi transférer vers le GPU les variables imgs et label de notre fonction de validation :
def validate(model, train_loader, val_loader):
for name, loader in [("train", train_loader), ("val", val_loader)]:
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in loader:
outputs = model(imgs.to(device))
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels.to(device)).sum())
print("Accuracy {}: {:.2f}".format(name , correct / total))On valide notre modèle :
validate(model, train_loader, val_loader)Tester le modèle
On peut aussi tester notre modèle sur une image, prenons celle-ci :
import matplotlib.pyplot as plt
img, _ = cifar2[290]
plt.imshow(unorm(img).permute(1, 2, 0))
plt.show()
Ensuite, pour prédire le label de cette image on utilise notre modèle avec ce bout de code :
# evaluate model:
loaded_model.eval()
with torch.no_grad():
out_data = loaded_model(img.unsqueeze(0).to(device=device))
print(out_data)
print(class_names)Plus le résultat est grand, plus la probabilité d’appartenir à la classe est forte et inversement.
Ici notre modèle prédit avec une forte probabilité que l’image appartient à la classe ‘cerf’ !
Sauvegarder / Charger les poids
Pour sauvegarder les poids de notre modèle, le processus est le même qu’avec CPU :
torch.save(model.state_dict(), 'birds_vs_airplanes_wgpu.pt')Cependant, pour les charger il faudra indiquer le transère de GPU lors de l’appel de Net() et le paramètre map_location=device lorsque l’on charge les poids :
loaded_model = Net().to(device=device)
loaded_model.load_state_dict(torch.load('birds_vs_airplanes_wgpu.pt',
map_location=device))sources :
- L. Antiga, Deep Learning with PyTorch (2020, Manning Publications) – notre lien affilié
- Photo by Tobias Keller on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :