

« Segment Anything Model » – SAM – est un modèle de Deep Learning créé et entraîné par une équipe de chercheurs à Meta.
L’innovation a été présenté dans un papier de recherche publié le 5 avril 2023.
Elle a tout de suite attiré un intérêt massif du public – la publication Twitter associée cumule plus de 3.5 millions de vues à ce jour :
Les professionnels en Computer Vision dirige actuellement leur regard vers SAM – mais pourquoi ?
Qu’est-ce que SAM ?
Dans le papier de recherche Segment anything, SAM est présenté comme un modèle de fondation (en anglais « foundational model »).
Un modèle de fondation est un modèle de Machine Learning entraîné sur une quantité massive de données (souvent par apprentissage auto-supervisé ou semi-supervisé) et dont le but est d’être utilisé et ré-entraîné sur un tâche plus spécifique.
En d’autres termes, SAM est un modèle pré-entraîné pensé pour être adapté sur des tâches annexes (notamment grâce au « fine tuning »).
Par exemple, SAM peut être ré-entraîné et utilisé pour segmenter uniquement les personnes dans un dataset.
La segmentation de personne est une tâche annexe que SAM peut réaliser car il a été entraîné sur un dataset contenant ce type d’objets – mais pas que !
Comment SAM a-t-il été entraîné ?
SAM a été entraîné sur le SA-1B dataset, un jeu de données introduit par Meta en parallèle du papier de recherche Segment Anything.
Le dataset de l’entreprise parente de Facebook contient plus de 11 millions d’images collectées sur la quasi-totalité de la planète – un aspect important pour développer un modèle capable de généraliser.
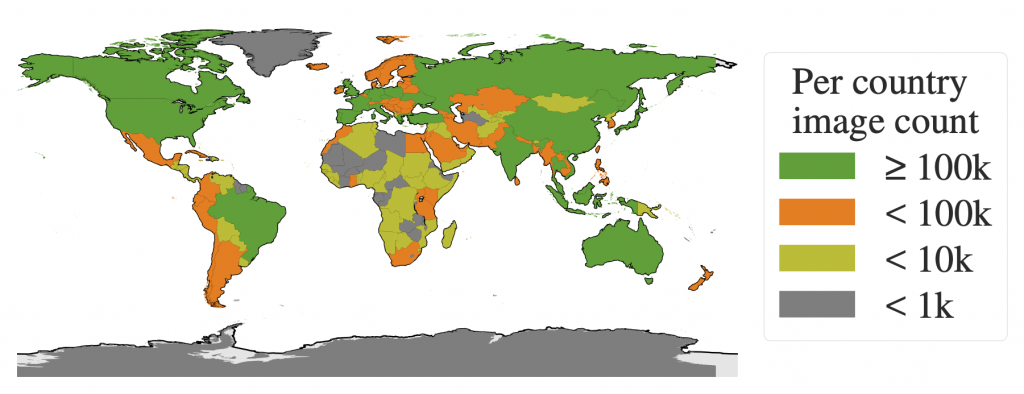
Ces images de hautes qualités (en moyenne 1500×2250 pixels) sont accompagnés de 1.1 milliards de masques de segmentation correspondant au label de ce dataset.
L’objectif de Meta avec ce dataset est de créer une référence de segmentation pour les docteurs en Intelligence Artificielle. Il est officiellement libre de droit à des fins de recherche.
Malgré cette quantité massive d’informations, il est important de noter que les masques ne sont pas associés à des classes. C’est-à-dire que même si SAM peut générer le masque d’une personne, il sera incapable d’indiquer que ce masque représente une personne.
Cet aspect est important à prendre en considération car il implique que, pour être réellement utiliser SAM doit être combiner à d’autres algorithmes.
Voyons cela de plus près.
Comment utiliser Segment Anything – SAM ?
Pour commencer, il nous faut charger 2 éléments :
- le dossier GitHub
segment-anythingqui contient les classes et fonctions permettant d’utiliser SAM - les poids du modèle pré-entraîné permettant d’utiliser la version du modèle obtenue par les chercheurs de Meta
!pip install git+https://github.com/facebookresearch/segment-anything.git &> /dev/null
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pthEnsuite, on crée 3 variables globales :
MODEL_TYPE: l’architecture de SAM à utiliserCHECKPOINT_PATH: le chemin du fichier contenant les poids du modèleDEVICE: le processeur utilisé ,"cpu"ou"cuda"(si un GPU est disponible)
MODEL_TYPE = "vit_h"
CHECKPOINT_PATH = "/content/sam_vit_h_4b8939.pth"
DEVICE = "cuda" #cpu,cudaNous pouvons à présent charger le modèle SAM grâce à la fonction sam_model_registry et en indiquant les poids du modèle :
from segment_anything import sam_model_registry
sam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)Le modèle chargé, Meta nous laisse deux options pour l’utiliser :
- l’option Generator qui permet d’obtenir l’ensemble des masques générés par le modèle à partir d’une image
- l’option Predictor qui permet d’obtenir un ou plusieurs masques spécifiques à partir d’une image et selon un prompt
Nous allons explorer ces deux options dans les lignes qui suivent.
Avant cela, chargeons une image depuis internet sur laquelle nous expérimenterons notre modèle :
from urllib.request import urlopen
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
resp = urlopen('https://images.unsplash.com/photo-1615948812700-8828458d368a?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=2072&q=80')
image = np.asarray(bytearray(resp.read()), dtype='uint8')
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
image = cv2.resize(image, (int(image.shape[1]/2.5), int(image.shape[0]/2.5)))
cv2_imshow(image)
Notre image contient plusieurs personnes, un chien et des voitures.
À présent nous allons utiliser SAM avec l’option Generator pour segmenter cette image.
Generator
Dans cette partie nous allons utiliser SAM en version Generator. Cela nous permettra d’obtenir l’ensemble des masques générés à la suite de l’analyse de notre image par le modèle.
Initialisons l’objet SamAutomaticMaskGenerator :
from segment_anything import SamAutomaticMaskGenerator
mask_generator = SamAutomaticMaskGenerator(sam)Ensuite on lance la génération de masque via la fonction generate() :
masks_generated = mask_generator.generate(image)Avec cette fonction, nous obtenons un masque par objet détecté mais également d’autres données. SAM génère en réalité un ensemble d’informations (sous forme de dictionnaire) associé aux objets qu’il détecte.
Résultat de la prédiction
On peut afficher les clés obtenues pour chaque ensemble d’informations :
print(masks_generated[0].keys())Sortie :
dict_keys([‘segmentation’, ‘area’, ‘bbox’, ‘predicted_iou’, ‘point_coords’, ‘stability_score’, ‘crop_box’])
On obtient un ensemble de 7 informations. La première 'segmentation' représente les pixels correspondant à l’emplacement de l’objet détecté : True si le pixel contient l’objet, False sinon.
On peut afficher un masque comme suit :
cv2_imshow(masks_generated[3]['segmentation'].astype(int)*255)
Les autres informations de l’ensemble correspondent aux descriptions suivantes :
area: la surface du masque en pixelsbbox: la boîte englobante du masque au format XYWHpredicted_iou: le score de qualité du masque prédit par le modèlepoint_coords: le point d’entrée échantillonné qui a généré ce masquestability_score: un score additionnel de qualité du masquecrop_box: le recadrage de l’image utilisé pour générer ce masque au format XYWH
La plupart des praticiens n’exploiteront pas ces informations, néanmoins, pour répondre à certains cas spécifiques, il est important de savoir que SAM ne permet pas uniquement de générer des masques mais également des informations annexes comme celles-ci.
Voilà le reste des informations obtenues pour le masque affiché précédemment :
print('area :', masks_generated[3]['area'])
print('bbox :',masks_generated[3]['bbox'])
print('predicted_iou :',masks_generated[3]['predicted_iou'])
print('point_coords :',masks_generated[3]['point_coords'])
print('stability_score :',masks_generated[3]['stability_score'])
print('crop_box :',masks_generated[3]['crop_box'])Sortie :
area : 5200 bbox : [499, 284, 92, 70]
predicted_iou : 1.005275845527649
point_coords : [[582.1875, 318.546875]]
stability_score : 0.981315553188324
crop_box : [0, 0, 828, 551]
On peut égalemment afficher le nombre de masques générés par SAM :
print(len(masks_generated))Sortie : 111
SAM a généré un total de 111 masque à partir de notre image.
Afficher la prédiction
Grâce à la fonction draw_masks_fromDict détaillée dans cette article, nous pouvons tracer la totalité des masques générés sur notre image :
segmented_image = draw_masks_fromDict(image, masks_generated)
cv2_imshow(segmented_image)
L’image de départ contient à présent les masques générés par SAM.
Dans cette partie nous avons utilisé la version Generator de SAM. Celle-ci nous a permis de générer 111 masques à partir d’une image. En plus, de masques, SAM génère également des informations additionnels de détection. Pour visualiser la prédiction du modèle, nous avons finalement tracé la totalité des masques sur notre image de départ.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
SAM nous a ainsi permis de faire de la segmentation sur image. Néanmoins, on peut voir que les masques générés sont dèsordonnés : il n’y a pas de classes permettant de distinguer les différents masques. Par exemple les masques de personnes ne sont pas associées à une couleur unique. On ne peut donc pas ordonner les segmentations obtenues. La seule information obtenue ici est l’emplacement et la délimitation des objets.
De plus, les masques générés peuvent se superposer. En effet, SAM peut détecter les objets à l’intérieur d’autres objets. Cette particularité possède un aspect positif : cela démontre la capacité de SAM a détecter quasiment tous les objets d’une image. Ainsi, on peut à la fois segmenter un chien, une voiture, une personne mais également, des objets diverses : une roue, une fenêtre, un pantalon. Ainsi, la version Generator de SAM permet de segmenter la totalité des objets d’une image et même les objets qui se superposent.
Par delà le Generator
Mais cette particularité possède également un aspect négatif : cela accroît le nombre de prédiction en une même zone ce qui peut perturber l’atteinte d’un objectif. Par exemple, si l’on souhaite repérer les personnes sur une image, il n’est pas pertinent de détecter également les masques correspondants à la veste et au pantalon de ces personnes.
En outre, étant donné que SAM n’est pas entraîné sur des données labellisées, il est impossible de filtrer ses prédictions pour garder celle qui nous intéresse. Cela veut dire que même si nous segmentions l’ensemble des images d’un dataset avec la version Generator de SAM, il serait impossible d’extraire facilement, par exemple, les masques de personnes. Ainsi, la capacité du Generator SAM à segmenter la totalité des objets d’une image peut ne pas convenir dans la résolution de certains problèmes.
Par conséquent, pour faire de la détection d’objets ciblés, il n’est pas pertinent d’utiliser la version Generator de SAM. Il faudra, en lieu de celle-ci, utiliser la version Predictor. Cette version va nous permettre d’utiliser SAM avec des prompts pour préciser notre demande et cibler des objets à détecter.
Predictor
Dans cette partie nous allons utiliser SAM en version Predictor. La version Predictor va nous permettre de détecter des objets ciblés. Pour réaliser cela, nous allons envoyer à SAM des « prompts » (en français « requêtes ») pour préciser les objets que nous souhaitons détecter.
Actuellement, les prompts que l’on peut envoyer à SAM peuvent se formuler selon deux approches :
- par points d’intérêt
- par bounding boxes
SAM peut prendre en entrée un point d’intérêt (coordonnées x et y) ciblant un pixel de l’image représentant un objet. L’objet désigné par le point d’intérêt permettra alors à SAM de générer le masque associé à cet objet.
SAM peut également prendre en entrée une bounding box délimitant les contours d’un objet sur une image. En se basant sur ces contours, SAM produira un masque approprié.
Remarque : Le « prompting » est un terme tendance utilisé, en majorité, pour désigner les requêtes textuelles envoyées à ChatGPT. Néanmoins, comme démontré ici avec SAM, le prompting ne se limite pas à des requêtes textuelles. Il s’étend à un ensemble de requêtes que peut envoyer le praticien à un modèle de Machine Learning.
Il est important de noter que, même si la fonctionnalité n’est actuellement pas disponible publiquement, Meta a prévu la compréhension de requête textuelle par son Segment Anything Model.
Cela étant dit, pour la suite de ce tutoriel, nous devons posséder un prompt à envoyer à SAM. Les bounding boxes étant une norme en Computer Vision, nous utiliserons celles-ci.
Prompting par bounding boxes
Si tu souhaites poursuivre ce tutoriel, tu dois préalablement posséder les bounding boxes associées aux objets que tu souhaites segmenter.
Si tu ne possèdes pas de bounding boxes pour ton image, tu peux en produire facilement en quelques lignes de code avec le modèle YOLO.
Tu peux apprendre à utiliser ce modèle pour produire rapidement tes propres bounding boxes. Un tutoriel dédié à la version la plus récente de YOLO t’attend ici.
Une fois YOLO utilisé sur notre image, on obtient ce résultat :
image_bboxes = image.copy()
boxes = np.array(results[0].to('cpu').boxes.data)
plot_bboxes(image_bboxes, boxes, score=False)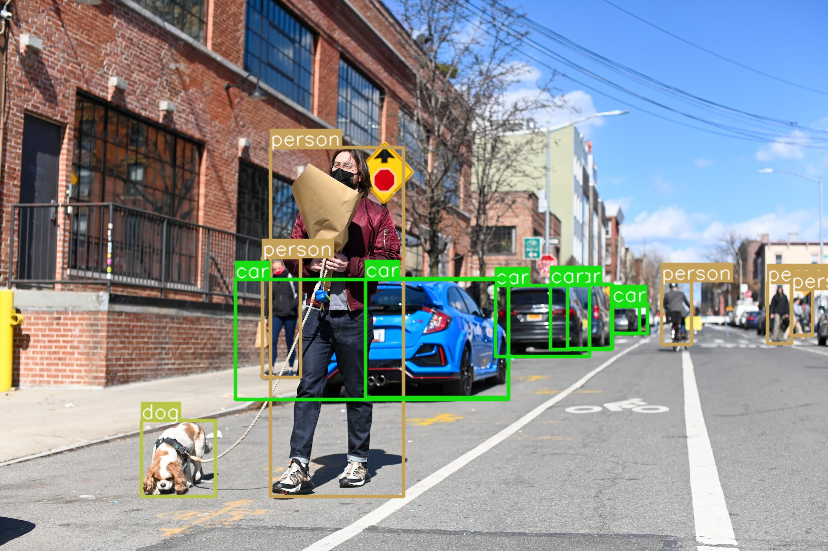
Remarque : la variable results est le résultat de la prédiction du modèle.
Les bounding boxes obtenues avec YOLO sont sous cette forme :
print(boxes)Sortie :
[[ 495.96 285.65 589.8 356.48 0.89921 2]
[ 270.63 147.99 403.17 496.82 0.79781 0]
…
[ 235.32 279.23 508.93 399.63 0.3193 2]
[ 612.13 303.94 647.61 333.11 0.2854 2]]
Les 4 premières valeurs représentent les coordonnées des bounding boxes, la 5ème valeur représente le score de confiance pour la bounding box prédite et la 6ème valeur est la classe détectée.
À présent que nous avons notre prompt, initialisons l’objet SamPredictor :
from segment_anything import SamPredictor
mask_predictor = SamPredictor(sam)Ensuite, on indique l’image que SAM doit analyser :
mask_predictor.set_image(image)À partir d’ici, le tutoriel se divise en deux :
- la détection d’un seul objet
- la détection par batch : un lot d’objets
Commençons par la première option.
Détecter un seul objet
Pour prédire le masque d’un objet, on indique à notre Predictor la bounding box correspondant à cet objet dans la fonction predict() :
mask, _, _ = mask_predictor.predict(
box=boxes[1][:-2]
)Nous obtenons un masque sous la forme d’un tableau de booléen indiquant l’emplacement de l’objet détecté (comme précédemment dans la clé 'segmentation' du dictionnaire) : True si le pixel contient l’objet, False sinon.
On peut tracer ce masque sur notre image avec la fonction draw_mask explicitée dans cet article :
mask = np.transpose(mask, (1, 2, 0))
segmented_image = draw_mask(image, mask)
cv2_imshow(segmented_image)
Notre image contient à présent le masque détecté par SAM.
Grâce au prompt indiqué à SAM, nous avons pu obtenir un masque de l’objet pour l’afficher sur notre image.
Voyons maintenant comment détecter les masques correspondants à l’ensemble de nos bounding boxes.
Détecter plusieurs objets
Pour effectuer des prédictions sur un lot de bounding boxes, il faut les rassembler dans un tenseur PyTorch.
On utilise ensuite la fonction transform.apply_boxes_torch() pour mettre à jour notre objet.
Finalement, on utilise predict_torch pour prédire les masques correspondants.
import torch
input_boxes = torch.tensor(boxes[:, :-2], device=mask_predictor.device)
transformed_boxes = mask_predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = mask_predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)Le résultat obtenu est un batch de 13 masques encodé sur une dimension (1, 551, 828).
Pour mieux manipuler ce tenseur, supprimons la première dimension qui n’est pas pertinente :
print(masks.shape)
masks = torch.squeeze(masks, 1)
print(masks.shape)Sortie :
torch.Size([13, 1, 551, 828])
torch.Size([13, 551, 828])
L’avantage d’avoir des bounding boxes en amont de l’utilisation de SAM est de pouvoir associer à chaque masque généré, le label correspondant à la bounding box, et donc, une couleur pour les différencier lors de leur affichage.
Définissons un dégradé de couleurs associées aux classes que YOLO peut prédire :
COLORS = [(89, 161, 197),(67, 161, 255),(19, 222, 24),(186, 55, 2),(167, 146, 11),(190, 76, 98),(130, 172, 179),(115, 209, 128),(204, 79, 135),(136, 126, 185),(209, 213, 45),(44, 52, 10),(101, 158, 121),(179, 124, 12),(25, 33, 189),(45, 115, 11),(73, 197, 184),(62, 225, 221),(32, 46, 52),(20, 165, 16),(54, 15, 57),(12, 150, 9),(10, 46, 99),(94, 89, 46),(48, 37, 106),(42, 10, 96),(7, 164, 128),(98, 213, 120),(40, 5, 219),(54, 25, 150),(251, 74, 172),(0, 236, 196),(21, 104, 190),(226, 74, 232),(120, 67, 25),(191, 106, 197),(8, 15, 134),(21, 2, 1),(142, 63, 109),(133, 148, 146),(187, 77, 253),(155, 22, 122),(218, 130, 77),(164, 102, 79),(43, 152, 125),(185, 124, 151),(95, 159, 238),(128, 89, 85),(228, 6, 60),(6, 41, 210),(11, 1, 133),(30, 96, 58),(230, 136, 109),(126, 45, 174),(164, 63, 165),(32, 111, 29),(232, 40, 70),(55, 31, 198),(148, 211, 129),(10, 186, 211),(181, 201, 94),(55, 35, 92),(129, 140, 233),(70, 250, 116),(61, 209, 152),(216, 21, 138),(100, 0, 176),(3, 42, 70),(151, 13, 44),(216, 102, 88),(125, 216, 93),(171, 236, 47),(253, 127, 103),(205, 137, 244),(193, 137, 224),(36, 152, 214),(17, 50, 238),(154, 165, 67),(114, 129, 60),(119, 24, 48),(73, 8, 110)]Enfin, on peut utiliser la fonction draw_masks_fromList développée dans cet article pour tracer l’ensemble de nos masques en leur associant une couleur par label :
segmented_image = draw_masks_fromList(image, masks.to('cpu'), boxes, COLORS)
cv2_imshow(segmented_image)
Nous avons affiché l’ensemble des masques prédit par YOLO grâce aux bounding boxes que nous avons fourni. En plus de cela, chacun des masques est colorisé en fonction de la classe indiquée par nos bounding boxes. Cela nous permet de distinguer facilement les différents objets segmentés.
Segmenter une vidéo
Cette dernière méthode de prédiction de masques semble être celle à privilégier pour la segmentation d’images.
Mais SAM peut être utilisé pour faire plus que cela !
Dans cet article nous avons discuté extensivement de SAM. Tout d’abord nous avons vu que SAM est un modèle de fondation, entraîné sur le SA-1b dataset. Ensuite, nous avons exploré les différents objectifs que peut accomplir SAM. Finalement nous avons appris, en pratique, à utiliser le Segment Anything Model.
Néanmoins, un cas d’usage n’a pas été discuté ici.
Nous avons vu comment utiliser SAM pour segmenter une image mais il est également possible d’utiliser SAM pour segmenter des vidéos.
J’ai récemment créer une formation gratuite pour maîtriser YOLO (le modèle qui prédit l’emplacement d’objets par bounding boxes) sur des vidéos pré-enregistrés et des flux videos en temps réel.
Dès aujourd’hui tu pourras également trouver dans cette formation gratuite un tutoriel pour apprendre à utiliser SAM sur des vidéos.
Pour obtenir ton accès, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



