

Ultralytics vient de sortir sa dernière version de YOLO : YOLOv8. Dans cet article, on voit en détail comment l’utiliser !
YOLOv8 est la première version de YOLO sortie en 2023, le 10 janvier.
YOLO (You Only Look Once) est un des algorithmes de détection d’objets les plus populaires dans le domaine du Deep Learning.
La première version est sortie en 2016 !
L’idée principale, et qui fait le charme de YOLO, est sa capacité à détecter des objets dans une image en une seul passe.
À l’époque, c’est une avancée majeure car la plupart des algorithmes devait être exécuter à plusieurs reprises sur différentes parties de l’image.
Pourquoi ?
Car ces algorithmes ne pouvait détecter qu’un seul objet à la fois.
Une perte de temps considérable !
Les capacités de YOLO n’ont donc pas tarder à séduire les professionnels.
Et c’est ainsi qu’on a le droit a une nouvelle version de YOLO plusieurs fois par an.
En 2022, on a déjà vu sur Inside Machine Learning :
Je te propose de passer à la version 8.
Mais avant… YOLOv8 vaut-il le coup ?
Je te laisse juger par toi-même avec le graphe de ses performances comparées aux autres versions du modèle :
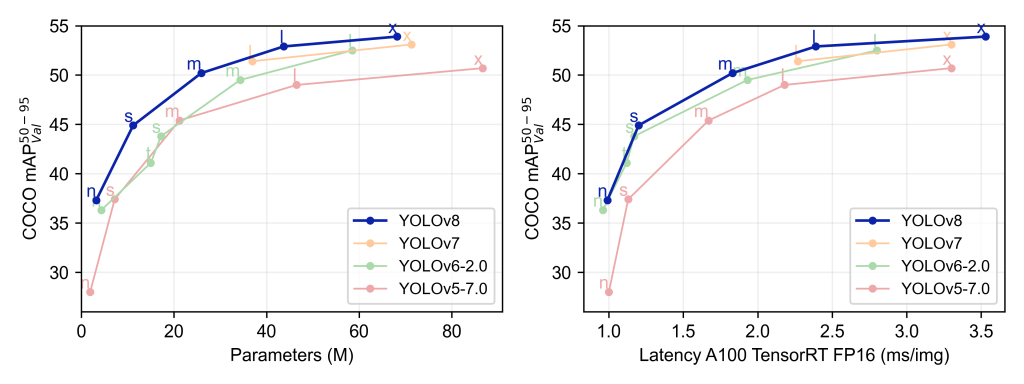
Et maintenant, voyons comment l’utiliser !
Comment utiliser YOLOv8 ?
Tout d’abord, tu auras besoin de la librairie ultralytics.
Pour l’installer depuis python utilise cette commande :
!pip install ultralyticsEnlève le ! si tu utilise un terminal.
Utiliser sur Python
Pour utiliser YOLOv8 et afficher le résultat, il te faudra les librairies suivantes:
from ultralytics import YOLO
import numpy as np
from PIL import Image
import requests
from io import BytesIO
import cv2Et si tu es sur Google Colab aussi importe celle-là :
from google.colab.patches import cv2_imshowMaintenant, on peut charger une version de YOLOv8 pré-entraîné (par défaut ultralytics nous donne la plus récente) :
model = YOLO("yolov8n.pt")Ensuite, on peut charger une image depuis internet et la transformer en array numpy :
response = requests.get("https://images.unsplash.com/photo-1600880292203-757bb62b4baf?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2070&q=80")
image = Image.open(BytesIO(response.content))
image = np.asarray(image)Puis, on lance la prédiction sur notre image (cela devrait être rapide, même sans GPU) :
results = model.predict(image)On a lancé notre prédiction !
La variable results contient la liste des bounding boxes englobant les objets détectés.
Tu peux les voir avec print(results[0].boxes.data). Elles sont au format [x1, y1, x2, y2, score, label].
Maintenant, on va afficher nos Bounding Boxes.
Pour ça on utilise notre fonction (courte et simple) qui nous permet d’afficher les bounding boxes avec le label et le score. Je l’ai détaillée dans cet article.
Une fois que tu as copié la fonction, tu peux l’utiliser comme cela :
plot_bboxes(image, results[0].boxes.data, score=False)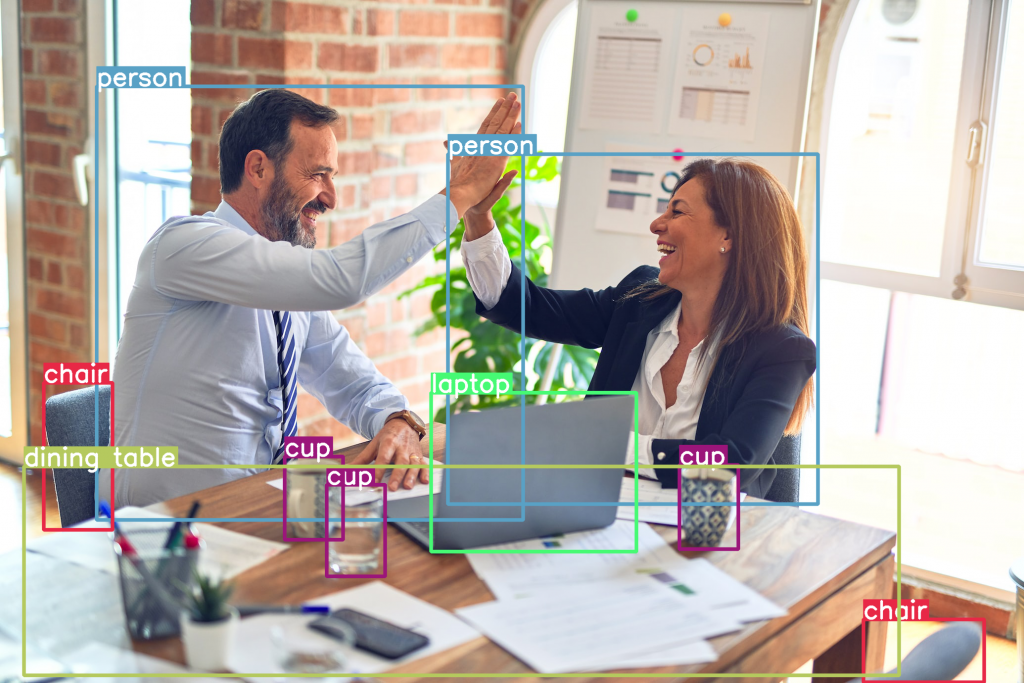
On obtient un bon paquet d’objets.
Certains sont pertinents.
D’autres, ne le sont pas.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Comme la chaise au fond à gauche.
En fait, le modèle n’a pas détecter tout ces objets avec le même score de confiance.
On peut filtrer ces objets selon ce score.
Par exemple, on peut afficher uniquement les bounding boxes ayant un score supérieur à 85%.
Ainsi, tous les objets détectés avec un score inférieur ne seront pas affichés.
Pour filter selon le score de confiance, on indique conf=0.85 :
plot_bboxes(image, results[0].boxes.data, score=False, conf=0.85)
YOLOv8 détecte les deux personnes avec un score supérieur à 85%, pas mal ! ☄️
Utiliser sur Terminal
Ultralytics te permet aussi d’utiliser YOLOv8 sans passer par Python, directement dans un terminal de commande.
Dans ce cas, tu as plusieurs options:
1. YOLOv8 sur une seule image
Tout d’abord tu peux utiliser YOLOv8 sur une seule image, comme vu précédemment en Python.
Pour cela tu as seulement besoin d’utiliser la commande suivante.
yolo task=detect mode=predict model=yolov8n.pt conf=0.25 source='/content/photo.jpeg'conf– indique le seuil de confiance pour accepter une Bounding Box (ici le score doit être au minimum égale à 25%)source– indique l’URL, ou le chemin de ton image si tu l’as en local
Le résultat est dans /runs/detect/predict/.
2. YOLOv8 sur un dossier d’images
Ensuite, tu peux aussi utiliser YOLOv8 directement sur un dossier contenant des images.
Pour cela, tu as seulement à indiquer le chemin de ton dossier contenant les images dans source.
yolo task=detect mode=predict model=yolov8n.pt conf=0.25 source='/img_dossier/'Si tu as exécuté la commande précédente, le résultat sera dans /runs/detect/predict2/.
Ré-entraîner YOLOv8
Pour finir tu peux aussi ré-entraîner YOLOv8.
Pour cela, charge le model yolov8n.yaml. C’est une version non-entrainée du modèle :
from ultralytics import YOLO
model = YOLO("yolov8n.yaml")Ensuite, tu peux entraîné ton modèle sur le dataset COCO comme ceci :
results = model.train(data="coco128.yaml", epochs=3)Puis l’évaluer sur ton dataset :
results = model.val(data=your_data)Et lancer des prédictions sur de nouvelles images (comme vu précédemment) :
results = model.predict("https://images.unsplash.com/photo-1600880292203-757bb62b4baf?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=2070&q=80")Finalement, tu peux aussi enregistrer ton nouveau modèle au format ONNX :
success = model.export(format="onnx")Tu as quasiment tout ce qu’il te faut pour utiliser YOLO v8.
En effet, peut-être qu’en plus de détecter des objets sur une photo, tu aimerais maintenant apprendre à utiliser ce modèle de pointe sur des vidéos pré-enregistrées.
Peut-être même que tu souhaiterais l’utiliser en temps réel sur un flux vidéo continu.
Il est tout à fait possible d’utiliser YOLO v8 pour ces cas, si ça t’intéresse, j’ai créé la mini-formation gratuite Détection d’Objets Tout-Terrain qui te permettra d’apprendre tout cela :
source :
- Ultralytics – Github
Mise-à-jour 06/09/23 :
- Pour accéder au bounding boxes, utilise
results[0].boxes.dataau lieu deresults[0].boxes.boxes
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :




comment utiliser yolov8 en temps réel c’est à dire
sur vidéo direct
NameError: name ‘plot_bboxes’ is not defined
Bonjour Juliette,
Lis l’article 😉
« Pour ça on utilise notre fonction (courte et simple) qui nous permet d’afficher les bounding boxes avec le label et le score. Je l’ai détaillée dans cet article. »
Bonne journée à toi,
Tom
je me suis retrouvée, merci beaucoup. S’il vous plaît, je pourrai savoir comment modifier la solution pour détecter les objets dans une video plutôt que dans une image?
Hello Juliette,
J’ai récemment fait une formation sur YOLO pour apprendre à l’utiliser sur des vidéos pré-enregistrées ainsi que des flux vidéos en temps réel. Ce que tu y apprendras s’applique à YOLO mais également à n’importe quel modèle de Deep Learning. Tu peux y accéder gratuitement en cliquant sur le bouton vert en fin d’article « Débloquer ma formation ».
Bonne journée,
Tom
Bonjour,
Est-il possible d’utiliser Yolo pour (entrainer) et reconnaitre des visages de personnes identifiées dans une grande base de photos documentaire ? Des artistes par exemple. Merci