

Le Recall, la Precision, le F1 Score comment retenir facilement leur utilité et ce que ces métriques impliquent ?
Pour comprendre ces métriques il faut connaître les concepts de Vrais Positifs / Faux Négatifs (détaillés dans cet article avec en plus une méthode pour ne pas les oublier)
À partir de ces concepts, nous allons déduire des métriques qui nous permettront de mieux analyser les performances de notre modèle de Machine Learning !
Recall
Le recall permet de savoir le pourcentage de positifs bien prédit par notre modèle.
En d’autres termes c’est le nombre de positifs bien prédit (Vrai Positif) divisé par l’ensemble des positifs (Vrai Positif + Faux Négatif).
Sous forme mathématique, on a :
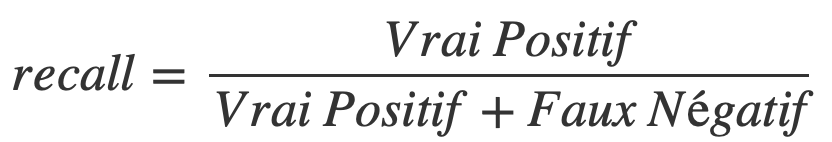
Mais quel est l’intérêt du recall ?
Plus il est élevé, plus le modèle de Machine Learning maximise le nombre de Vrai Positif.
Mais attention, cela ne veut pas dire que le modèle ne se trompe pas.
Quand le recall est haut, cela veut plutôt dire qu’il ne ratera aucun positif. Néanmoins cela ne donne aucune information sur sa qualité de prédiction sur les négatifs.
Precision
La precision est assez similaire au recall, il faut donc bien comprendre leur différence.
Elle permet de connaître le nombre de prédictions positifs bien effectuées.
En d’autres termes c’est le nombre de positifs bien prédit (Vrai Positif) divisé par l’ensemble des positifs prédit (Vrai Positif + Faux Positif).
Cela nous donne sous forme mathématique :
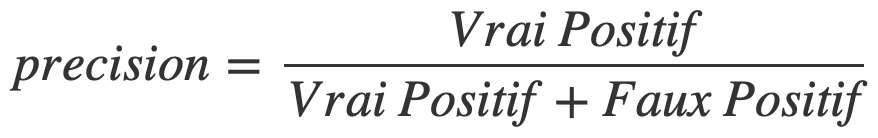
Qu’est ce que nous apporte la precision ?
Plus elle est élevé, plus le modèle de Machine Learning minimise le nombre de Faux Positif.
Quand la précision est haute, cela veut dire que la majorité des prédictions positives du modèle sont des positifs bien prédit.

Un exemple concret pour mieux comprendre
Reprenons notre exemple de l’article sur les Vrais Positif et Faux Négatifs.
Nous sommes en face d’un tunnel et nous devons prédire si c’est une voiture (Positif) ou une moto (Négatif) qui en sortira.
Eh bien le recall, c’est le nombre de voiture que notre modèle a prédit, et qui se sont avérés être effectivement des voitures, divisé par l’ensemble des voitures qui ont traversé le tunnel.
La precision, c’est aussi le nombre de voiture que notre modèle a prédit, et qui se sont avérés être effectivement des voitures, mais ici, divisé par le nombre total de voiture que notre modèle a prédit, et qui se sont avérés être vrai (voiture) ou fausse (moto).
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
En fait avec le recall, on regarde le nombre de positif que le modèle a bien prédit sur l’ensemble des positifs.
Alors qu’avec la precision, on regarde le nombre de positif que le modèle a bien prédit sur l’ensemble des positifs prédit.
Méthode pour retenir
En une phrase :
- Plus le recall est haut, plus le modèle repère de positif
- Plus la precision est haute, moins le modèle se trompe sur les positifs

F1 Score
Bien qu’ils soient utiles, ni la précision ni le recall ne permettent d’évaluer entièrement un modèle de Machine Learning.
Séparément c’est deux métrique sont inutiles :
- si le modèle prédit uniquement « positif », le recall sera élevé
- au contraire, si le modèle ne prédit jamais « positif », la precision sera élevée
On aura donc des métriques indiquant que notre modèle est efficace alors qu’il sera au contraire – naïf. En d’autres termes, le haut score présenté n’indiquera pas une réelle performance.
Heureusement pour nous, une métrique permettant de combiner la precision et le recall existe : le F1 Score.
Le F1 Score permet d’obtenir une évaluation relativement correct de la performance de notre modèle.
Il se calcule ainsi :
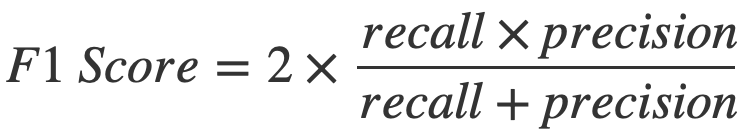
Le F1 Score ressemble à une moyenne du recall et de la precision mais en plus complexe.
Pourquoi, dans ce cas, ne pas remplacer le F1 Score par une moyenne de ces deux métriques ?
La raison vient du faire que, en statistique, le calcul sur les pourcentages n’est pas exactement le même que sur les nombres entiers.
Ici le F1 Score est ce qu’on appelle la moyenne harmonique. C’est une « moyenne » adaptée aux calculs de taux/pourcentage (ici le recall et la precision).
Le F1 Score est donc utilisé dans notre contexte.
Plus le F1 Score est élevé, plus le modèle est performant.
La precision, le recall et le F1 Score font parti des mesures les plus utilisées par les Data Scientists.
Il est donc fondamentale de les connaître ou, au moins, de les avoir sous-mains 👋🏻
C’est pour cela que j’ai préparé un PDF qui récapitule l’ensemble des points majeurs de cet article. Si tu veux accéder au bonus (et également à 7 jours de conseils gratuit pour apprendre l’Intelligence Artificielle), il te suffit de cliquer ici :
sources :
- L. Antiga, Deep Learning with PyTorch (2020, Manning Publications) – notre lien affilié
- Photo by Jonathan Körner on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



