

Dans cet article, nous allons explorer les 3 piliers du Deep Learning qui lui confère sa puissance phénoménale.
Ces derniers mois, il est devenu impossible de contester la révolution technologique que promet le Deep Learning.
J’en veux pour preuves les sommets inégalés atteints par les Intelligences Artificielles actuelles:
- ChatGPT – capable de tenir des conversations et de générer des textes de qualité humaine
- Midjourney – capable de générer des images photoréalistes à partir de simples descriptions textuelles
- AlphaFold – capable de prédire la structure tridimensionnelle de protéines avec une précision sans précédent
- SeamlessM4T – capable de traduire et de transcrire de manière fluide la parole et le texte dans une centaine de language
Ces résultats ont été obtenus grâce aux travaux de chercheurs en IA des différentes entreprises comme Meta et Google.
Mais ils n’auraient pas pu avoir lieu sans la puissance phénoménale que possède le Deep Learning.
Cette puissance se divise en trois piliers qui permettent aux réseaux de neurones de:
- traiter de manière pertinente l’information
- analyser en profondeurs les ensembles de données
- s’adapter à différents contextes aisément.
Je te propose d’explorer ces trois piliers dès maintenant 🚀
Feature Engineering
Le premier pilier du Deep Learning lui donne sa pertinence dans le traitement de données: le Feature Engineering.
Le Feature Engineering est le processus consistant à créer, sélectionner ou transformer les caractéristiques (features) d’un dataset afin d’améliorer les performances d’un modèle de Machine Learning.
Ce processus est cruciale pour permettre aux modèles de comprendre et extraire des informations pertinentes dans la résolution d’une tâche.
Cependant, le Feature Engineer est souvent fastidieux. Il exige une expertise humaine pour concevoir des caractéristiques appropriées.
Ce problème n’existe pas en Deep Learning car le Feature Engineering est réalisé – automatiquement.
En effet les réseaux de neurones permettent d’automatiser la création, sélection et transformation de caractéristiques.
Ainsi, la conception et transformation de caractéristiques ne dépendent plus d’experts. En effet, les réseaux de neurones sont capables d’extraire automatiquement à partir des données brutes des informations pertinentes.
Pour bien comprendre ce concept, on peut comparer les données brutes d’un dataset aux pièces d’un puzzle éparpillées. Dans ce contexte, le Feature Engineering est l’art d’assembler ces pièces de manière à ce que l’image finale soit claire et compréhensible.
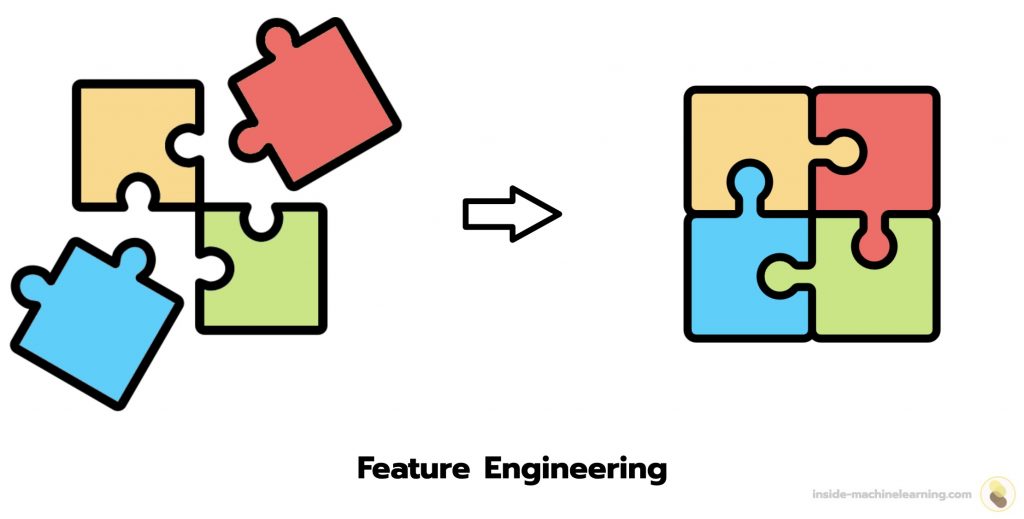
Le Feature Engineering automatique en Deep Learning apporte plusieurs avantages essentiels au traitement des données.
Avantages du Feature Engineering
Tout d’abord, le Feature Engineering réduit considérablement la charge de travail humaine.
En automatisant le processus de création de caractéristiques, le Deep Learning élimine le besoin de concevoir manuellement des caractéristiques pertinentes.
Cela permet aux experts en Machine Learning de se concentrer sur des tâches plus stratégiques.
De plus, le Feature Engineering automatique s’adapte à tout types de données – même les plus complexes.
Les réseaux de neurones sont ainsi capables de traiter des données brutes sans nécessiter un pré-traitement (preprocessing) intensif.
Le flux de travail est donc grandement simplifié, ce qui économise, là aussi, un temps de travail considérable.
Finalement, les réseaux de neurones peuvent également s’adapter efficacement à des ensembles de données évolutif.
En effet, grâce au Feature Engineering réalisé pendant l’entraînement du modèle, les caractéristiques créées par le modèle peuvent être ajuster en fonction des nouvelles données.
Cela garantit qu’un modèle restent pertinents, même dans des environnements en constante évolution.
Comment le Feature Engineering donne sa puissance au Deep Learning ?
Le Feature Engineering automatique en Deep Learning se traduit par des performances accrues. C’est le cas dans diverses applications, notamment la vision par ordinateur, le traitement du langage naturel et la recommandation.
Dans la vision par ordinateur, les réseaux de neurones convolutifs (CNN) sont conçus pour extraire automatiquement des caractéristiques pertinentes à partir d’images.
Ils utilisent des filtres convolutifs pour détecter des motifs visuels comme des bords, des textures et des formes.
Ensuite, dans le traitement du langage naturel, les Transformers génèrent également des caractéristiques. Ici, ils conçoivent des vecteurs de caractéristiques pour chaque mot dans une séquence.
Ces vecteurs sont calculées en fonction des relations entre les mots et peuvent être utilisées pour diverses tâches: traduction automatique, génération de texte, analyse de sentiments.
Enfin, dans le domaine de la recommandation, le Feature Engineering automatique consiste à analyser le comportement de l’utilisateur. Par exemple ses interactions passées, ses préférences, ses achats, etc.
Cela est réalisé sans avoir besoin de définir explicitement les caractéristiques à extraire.
Le Feature Engineering automatique permet aux réseaux de neurones d’extraire automatiquement des caractéristiques pertinentes à partir des données brutes.
Il simplifie le travail des experts, rend le Machine Learning plus performant, et permet de capturer des informations plus riches. Cela en fait un des piliers du Deep Learning – mais ce n’est pas le seul.
PS: si tu veux en savoir plus sur le Feature Engineering, un article sur le sujet t’attend sur ce lien.
Hierarchical Feature Learning
Le deuxième pilier du Deep Learning est le Hierarchical Feature Learning qui permet une analyse poussée de l’information.
Le Hierarchical Feature Learning est une méthode permettant d’analyser les caractéristiques des données selon plusieurs niveaux d’abstraction.
C’est une propriété qui permet aux réseaux de neurones de parcourir plusieurs niveaux de complexité pour comprendre en profondeur une caractéristique.
Cela signifie que le modèle peut extraire des informations de base, telles que des bords ou des textures dans une image, et les combiner pour former des représentations de plus haut niveau, comme des formes ou des objets.
Cette hiérarchie de caractéristiques permet au modèle d’acquérir une compréhension plus profonde et plus précise des données. C’est ce qui le rend apte à résoudre des problèmes complexes néanmoins ce n’est pas le seul avantage de cette propriété.
Avantages du Hierarchical Feature Learning
Le premier avantage majeur du Hierarchical Feature Learning est la capacité à apprendre des représentations hiérarchiques.
En structurant les caractéristiques à différents niveaux de complexité, le modèle peut visualiser des informations à des échelles variées.
Par exemple, dans le domaine de la vision par ordinateur, le modèle peut apprendre à détecter des motifs simples tels que les contours d’un animal, puis les combiner pour identifier la tête, le corps, les oreilles, et finalement, catégoriser cet animal.
Cette capacité à gérer des informations à différentes échelles permet au modèle de mieux comprendre la structure des données et de résoudre des tâches complexes telles que la reconnaissance d’objets.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Un autre avantage important du Hierarchical Feature Learning réside dans sa facilité de transfert de connaissances.
En effet, les caractéristiques apprises à différents niveaux de hiérarchie peuvent être réutilisées pour d’autres tâches similaires.
Par exemple, si un modèle a été entraîné à la reconnaissance des personnes dans des images, les caractéristiques de haut niveau qu’il a apprises peuvent être transférées à d’autres tâches de vision par ordinateur, comme la détection de visages.
Cela accélère considérablement le processus d’apprentissage, car le modèle n’a pas besoin de tout réapprendre à partir de zéro.
Il peut capitaliser sur les connaissances déjà acquises, ce qui est particulièrement utile lorsque les données d’apprentissage sont limitées.
Finalement, le Hierarchical Feature Learning contribue également à la réduction de la dimensionnalité des données.
En extrayant des caractéristiques discriminantes à différents niveaux de hiérarchie, il est possible de représenter les données de manière plus compacte.
Cela offre plusieurs bénéfices, notamment la meilleure généralisation des connaissances du modèle et la réduction des besoins en puissance de calcul.
En réduisant la dimensionnalité, le modèle devient moins susceptible à l’overfitting, ce qui améliore sa capacité à généraliser ses connaissances lorsqu’il est exposé à de nouvelles données.
De plus, une dimensionnalité réduite signifie que moins de ressources informatiques sont nécessaires pour traiter et stocker les données, ce qui peut être un facteur critique dans les applications en temps réel ou sur des plateformes à ressources limitées.
Comment le Hierarchical Feature Learning donne sa puissance au Deep Learning
Prenons un exemple concret en Deep Learning pour illustrer le Hierarchical Feature Learning: la classification d’images de chiens et de chats.
Dans ce contexte, le modèle apprendra des caractéristiques à différents niveaux de complexité.
Tout d’abord, il peut identifier des contours de poils et des nuances de couleurs spécifiques à chaque animal. Ce sont les caractéristiques de bas niveau.
Ensuite, il peut reconnaître des formes plus complexes, telles que les yeux, les oreilles, les pattes, et les motifs spécifiques aux races de chiens et de chats. Ce sont les caractéristiques de niveau intermédiaire.
Enfin, le modèle peut apprendre à détecter des caractéristiques de plus haut niveau, telles que la présence d’un museau, d’une queue, ou d’autres parties du corps caractéristiques de chaque animal. Ce sont les caractéristiques de haut niveau.
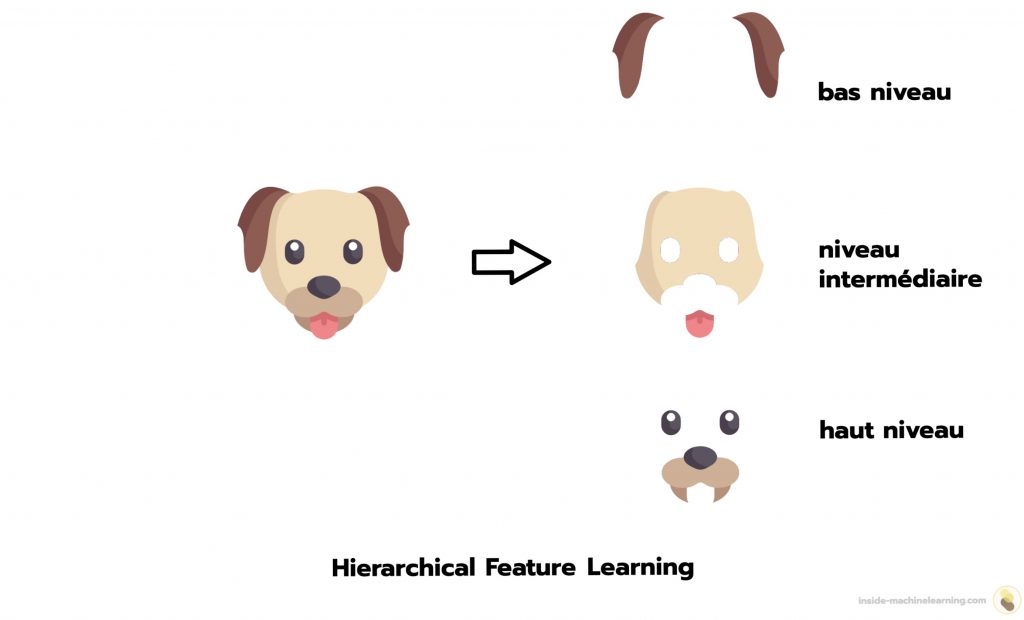
En combinant ces caractéristiques de différents niveaux hiérarchique, le modèle peut différencier les chiens et les chats avec précision.
Les réseaux de neurones ont la capacité de comprendre l’information à un niveau profond de détails grâce au Hierarchical Feature Learning. En plus de permettre une meilleure compréhension de la donnée, cette propriété est également un atout dans la réutilisation de modèles et dans l’optimisation de l’espace.
Le Hierarchical Feature Learning confère de précieux bénéfices, mais ce n’est pas la dernière qualité des réseaux de neurones. Une propriété majeure du Deep Learning lui confère également de nombreux avantages.
Scalabilité
Le troisième pilier, la scalabilité, permet aux algorithmes de Deep Learning de s’adapter à une large variété de contextes.
La scalabilité est la capacité d’un système à gérer de manière efficace des charges de travail de plus en plus importantes, notamment en ajoutant des ressources matérielles ou logicielles.
En Deep Learning, la scalabilité représente l’évolution des capacités dans le but de créer des modèle plus complexes, traiter des données plus vastes et résoudre des problèmes plus variés.
Cela est notamment réalisé grâce à l’utilisation de processeurs graphiques (GPU), d’unités de traitement tensoriel (TPU) ou de clusters de machines.
La scalabilité est inhérente à la plupart des bibliothèques de Deep Learning comme PyTorch et TensorFlow.
Cela veut dire qu’un modèle peut facilement être déplacé d’un appareil à un autre, par exemple d’un CPU à un GPU.
Le Deep Learning est donc scalable et cette propriété est à la source de nombreux avantages essentiels dans la création d’Intelligence Artificielle puissante.
Avantages de la scalabilité
Premièrement, la scalabilité en Deep Learning améliore considérablement les performances des modèles.
En augmentant leur capacité de traitement, les modèles peuvent être entraînés sur des datasets plus importants.
Cela permet aux modèles d’apprendre des caractéristiques plus détaillés et de généraliser plus efficacement.
Ces performances augmentées conduisent naturellement à une amélioration de la précision.
La scalabilité est, par conséquent, essentielle pour résoudre des problèmes complexes.
Deuxièmement, elle réduit le temps nécessaire à l’entraînement des modèles.
En distribuant la charge de calcul sur plusieurs ressources, le temps d’entraînement est significativement réduit.
Cela accélère le développement de nouveaux modèles, ce qui est essentiel pour la recherche et le développement de solutions de Deep Learning dans un délai raisonnable.
Troisièmement, la scalabilité confère une flexibilité accrue lors du choix des architectures de modèles et des hyperparamètres.
Avec des ressources évolutives, les chercheurs et les ingénieurs peuvent explorer de manière plus efficace différentes options sans avoir besoin de matériels surdimensionnés.
Cela facilite l’expérimentation, l’optimisation et l’adaptation des modèles pour des tâches spécifiques.
Comment la scalabilité donne sa puissance au Deep Learning
Un exemple concret de scalabilité en Deep Learning est l’utilisation de GPU pour l’entraînement de modèles.
Les GPU, conçus à l’origine pour les calculs graphiques, se sont révélés être d’excellentes unités de traitement parallèle pour les tâches de Deep Learning.
En distribuant la charge de calcul sur plusieurs GPU, il est possible d’entraîner des réseaux de neurones sur de vastes datasets – en un temps record.
Effectivement, en utilisant un seul CPU, le modèle pourrait prendre des semaines pour s’entraîner sur un ensemble de données volumineux.
En revanche, en utilisant plusieurs GPU, la même tâche pourrait être accomplie en quelques jours, voire en quelques heures.
Cette réduction significative du temps d’entraînement permet aux chercheurs de tester plus rapidement de nouvelles idées, d’itérer sur les modèles et d’accélérer la recherche en Deep Learning.
Cependant, tu peux tout à fait commencer le Deep Learning sans avoir de GPU.
Tu peux très bien entraîner des réseaux de neurones puissants avec ton ordinateur actuel (tout ordinateur possède au minimum un CPU – et certains outils te donnent même accès à des GPU gratuitement).
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
En bonus, tu recevras un récapitulatif de cet article sur la puissance du Deep Learning au format PDF 😉
Si ça t’intéresse, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



