

In this article, we’ll explore the 3 pillars of Deep Learning and understand how they give it its phenomenal power.
In recent months, it has become impossible to argue with the technological revolution promised by Deep Learning.
The evidence lies in the unparalleled heights reached by today’s Artificial Intelligences:
- ChatGPT – capable of holding conversations and generating human-quality texts
- Midjourney – capable of generating photorealistic images from simple text descriptions
- AlphaFold – capable of predicting the three-dimensional structure of proteins with unprecedented accuracySeamlessM4T – capable of seamlessly translating and transcribing speech and text into hundreds of languages.
These results were achieved thanks to the work of AI researchers at companies such as Meta and Google.
But they would not have been possible without the phenomenal power of Deep Learning.
This power is divided into three pillars that enable neural networks to:
- process relevant information
- analyze data sets in depth
- easily adapt to different contexts.
I invite you to explore these three pillars right now 🚀
Feature Engineering
The first pillar of Deep learning gives it its pertinence in data processing: Feature Engineering.
Feature Engineering is the process of creating, selecting or transforming the features of a dataset in order to improve the performance of a Machine Learning model.
This process is crucial to enable models to understand and extract relevant information to solving a task.
However, Feature Engineering is often tedious. It requires human expertise to design appropriate features.
This problem does not exist in Deep Learning, because Feature Engineering is performed – automatically.
Neural networks automate the creation, selection and transformation of features.
As a result, feature creation and transformation no longer depend on experts. Neural networks are capable of automatically extracting relevant information from raw data.
To understand this concept, we can compare the raw data in a dataset to the scattered pieces of a jigsaw puzzle. In this context, Feature Engineering is the art of assembling these pieces in such a way that the final picture is clear and comprehensible.
Automatic Feature Engineering in Deep Learning brings several essential advantages to data processing.
Advantages of Feature Engineering
Firstly, Feature Engineering dramatically reduces the human workload.
By automating the feature creation process, Deep Learning eliminates the need to manually design relevant features.
This allows Machine Learning experts to concentrate on more strategic tasks.
What’s more, automatic Feature Engineering adapts to all types of data – even the most complex.
Neural networks can process raw data without the need for intensive pre-processing.
This greatly simplifies the workflow, which likewise saves a considerable amount of time.
Finally, neural networks can also adapt efficiently to evolving data sets.
Indeed, thanks to the Feature Engineering performed during model training, the features created by the model can be adjusted according to new data.
This ensures that the model remains relevant, even in constantly changing environments.
How Feature Engineering gives Deep Learning its power?
Automatic Feature Engineering in Deep Learning translates into enhanced performance. This is the case in a variety of applications, including computer vision, natural language processing and recommendation.
In computer vision, convolutional neural networks (CNNs) are designed to automatically extract relevant features from images.
They use convolutional filters to detect visual patterns such as edges, textures and shapes.
Then, in natural language processing, Transformers also generate features. Here, they design feature vectors for each word in a sequence.
These vectors are calculated according to the relationships between words and can be used for a variety of tasks: machine translation, text generation, sentiment analysis.
Finally, in the field of recommendation, automatic Feature Engineering involves analyzing user behavior. For example, past interactions, preferences, purchases and so on.
This is achieved without the need to explicitly define the features to be extracted.
Automatic Feature Engineering enables neural networks to automatically extract relevant features from raw data.
It simplifies the work of experts, makes Machine Learning more efficient, and enables richer information to be captured. This makes it one of the pillars of Deep Learning – but not the only one.
PS: if you want to know more about Feature Engineering, an article on the subject awaits you at this link.
Hierarchical Feature Learning
The second pillar of Deep Learning is Hierarchical Feature Learning, which enables advanced analysis of information.
Hierarchical Feature Learning is a method for analyzing data features at several levels of abstraction.
It’s a property that enables neural networks to o explore multiple levels of complexity to gain an in-depth understanding of a feature.
It means that the model can extract basic information, such as edges or textures in an image, and combine them to form higher-level representations, such as shapes or objects.
This hierarchy of features enables the model to gain a deeper, more precise understanding of the data. This is what makes it capable of solving complex problems, but it’s not the only advantage of this property.
Advantages of Hierarchical Feature Learning
The first major advantage of Hierarchical Feature Learning is the ability to learn hierarchical representations.
By structuring features at different levels of complexity, the model can visualize information at a variety of scales.
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
For example, in computer vision, the model can learn to detect simple patterns such as the outline of an animal, then combine them to identify the head, body and ears, and finally categorize the animal.
This ability to handle information at different scales enables the model to better understand data structure and solve complex tasks such as object recognition.
Another major advantage of Hierarchical Feature Learning is its ease of knowledge transfer.
Indeed, features learned at different levels of the hierarchy can be reused for other similar tasks.
For example, if a model has been trained to recognize people in images, the high-level features it has learned can be transferred to other computer vision tasks, such as face detection.
This speeds up the learning process considerably, as the model doesn’t have to relearn everything from scratch.
It can capitalize on knowledge already acquired, which is particularly useful when training data is limited.
Last but not least, Hierarchical Feature Learning also helps to reduce the dimensionality of data.
By extracting discriminating features at different levels of hierarchy, it is possible to represent data more compactly.
This offers several benefits, including better generalization of model knowledge and reduced computing power requirements.
By reducing dimensionality, the model becomes less susceptible to overfitting, which improves its ability to generalize its knowledge when exposed to new data.
Furthermore, reduced dimensionality means that fewer computing resources are required to process and store data, which can be a critical factor in real-time applications or on resource-limited platforms.
How Hierarchical Feature Learning gives Deep Learning its power?
Let’s take a concrete Deep Learning example to illustrate Hierarchical Feature Learning: the classification of dog and cat images.
In this context, the model will learn features at different levels of complexity.
First, it can identify hair contours and color nuances specific to each animal. These are low-level features.
Next, it can recognize more complex shapes, such as eyes, ears, paws, and patterns specific to dog and cat breeds. These are intermediate-level features.
Finally, the model can learn to detect higher-level features, such as the presence of a muzzle, tail, or other body parts characteristic of each animal. These are the high-level features.
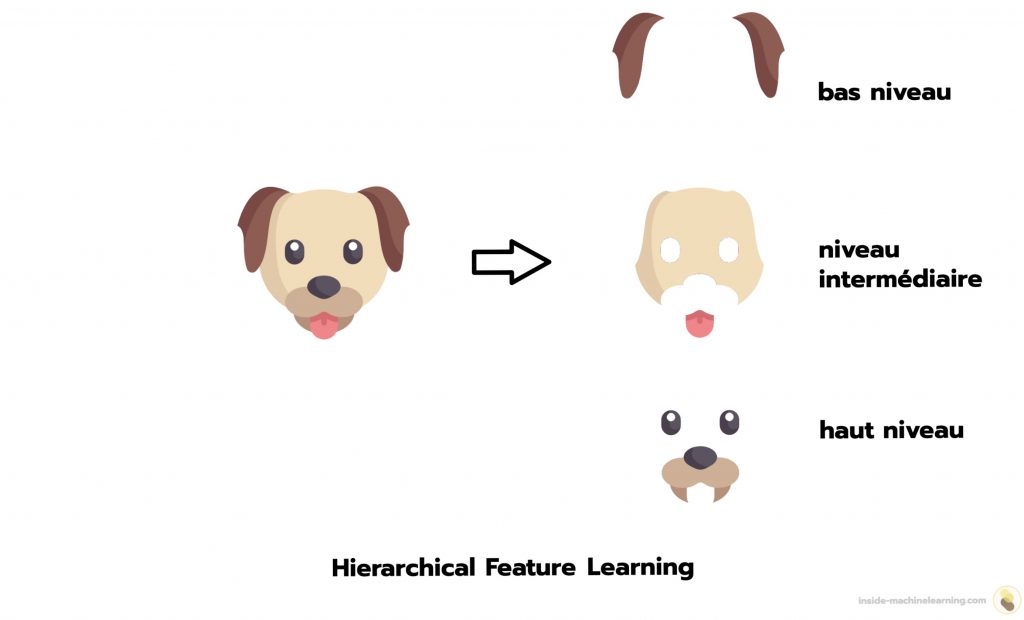
By combining these features from different hierarchical levels, the model can accurately differentiate between dogs and cats.
Neural networks have the ability to understand information at a deep level of detail, thanks to Hierarchical Feature Learning. As well as enabling a better understanding of the data, this property is also an asset in model reuse and space optimization.
Hierarchical Feature Learning confers valuable benefits, but it is not the last quality of neural networks. A major property of Deep Learning also confers many advantages.
Scalability
The third pillar, scalability, enables Deep Learning algorithms to adapt to a wide variety of contexts.
Scalability is the ability of a system to efficiently handle increasingly large workloads, notably by adding hardware or software resources.
In Deep Learning, scalability represents the evolution of abilities with the aim of creating more complex models, processing larger data sets and solving more varied problems.
This is notably achieved through the use of graphics processing units (GPUs), tensor processing units (TPUs) or machine clusters.
Scalability is inherent in most Deep Learning libraries, such as PyTorch and TensorFlow.
This means that a model can easily be moved from one device to another, for example from a CPU to a GPU.
Deep Learning is therefore scalable, and this property is the source of many essential advantages in the creation of powerful Artificial Intelligence.
Advantages of scalability
Firstly, scalability in Deep Learning significantly improves model performance.
By increasing their processing capacity, models can be trained on larger datasets.
This enables models to learn more detailed features and generalize more efficiently.
This increased performance naturally leads to improved accuracy.
Scalability is therefore essential for solving complex problems.
Secondly, it reduces the time needed to train models.
By distributing the computational load over several resources, training time is significantly reduced.
This speeds up the development of new models, which is essential for the timely research and development of Deep Learning solutions.
Thirdly, scalability provides greater flexibility when choosing model architectures and hyperparameters.
With scalable resources, researchers and engineers can explore different options more efficiently without the need for massive hardware.
This facilitates experimentation, optimization and adaptation of models for specific tasks.
How scalability gives Deep Learning its power?
A concrete example of scalability in Deep Learning is the use of GPUs for model training.
GPU, originally designed for graphical computing, have proved to be excellent parallel processing units for Deep Learning tasks.
By distributing the computational load across several GPU, it is possible to train neural networks on vast datasets – in record time.
Indeed, using a single CPU, the model could take weeks to train on a large dataset.
By contrast, using multiple GPU, the same task could be accomplished in days, or even hours.
This significant reduction in training time allows researchers to test new ideas faster, iterate on models and accelerate Deep Learning research.
However, you can easily start Deep Learning without a GPU.
You can train powerful neural networks with your current computer (every computer has at least one CPU – and some tools even give you access to GPU for free).
If you’d like to learn more about neural networks, take a look at my Action plan to Master Neural networks.
A program of 7 free courses that I’ve prepared to guide you on your journey to learn Deep Learning.
As a bonus, you’ll receive a summary of this article on Deep Learning power in PDF format 😉
If you’re interested, click here:
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



