

Dans cet article nous allons voir en détail pourquoi utiliser un Convolutional Neural Network (CNN) et qu’est-ce qu’une couche de convolution !
Un modèle de Deep Learning composé de couche de convolution se nomme un réseau de neurones convolutifs, Convolutional Neural Network (CNN), ou convnet.
Les CNN sont particulièrement utilisés pour le traitement d’image, de vidéo et la reconnaissance/détection d’objet mais ils peuvent aussi s’appliquer à d’autres types de données.
Dans cet article je vous propose de découvrir le cœur des CNN et les couches principales qui le composent !
Qu’est-ce qu’une Couche de Convolution ?
Un CNN possèdent différents types de couches. Parmi elle, les couches de convolution.
Une couche de convolution est une couche fully-connected (FC), c’est-à-dire que tous les neurones de la couche précédente sont relié à tous les neurones de cette couche.
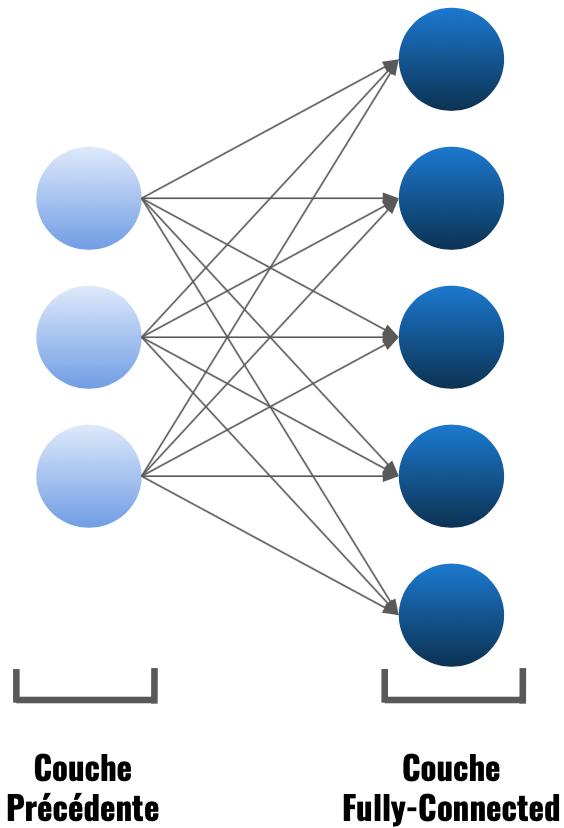
Si vous êtes un habitué de nos articles ce n’est pas la première fois que vous voyez des couches fully-connected notamment dans ce modèle de Deep Learning, nous avons utilisé des couches Dense qui sont des couches FC.
Les couches Dense apprennent en observant une image, une donnée, dans sa totalité.
À l’inverse, les couches de convolution analyse l’image par zone. Elles se focalisent sur chaque partie de la donnée.
Les couches Dense ont une approche globale là où les couches de convolutions ont une approche locale.
Cette approche locale permet aux couches convolutionnelles d’extraire les motifs, les tendances d’une donnée.
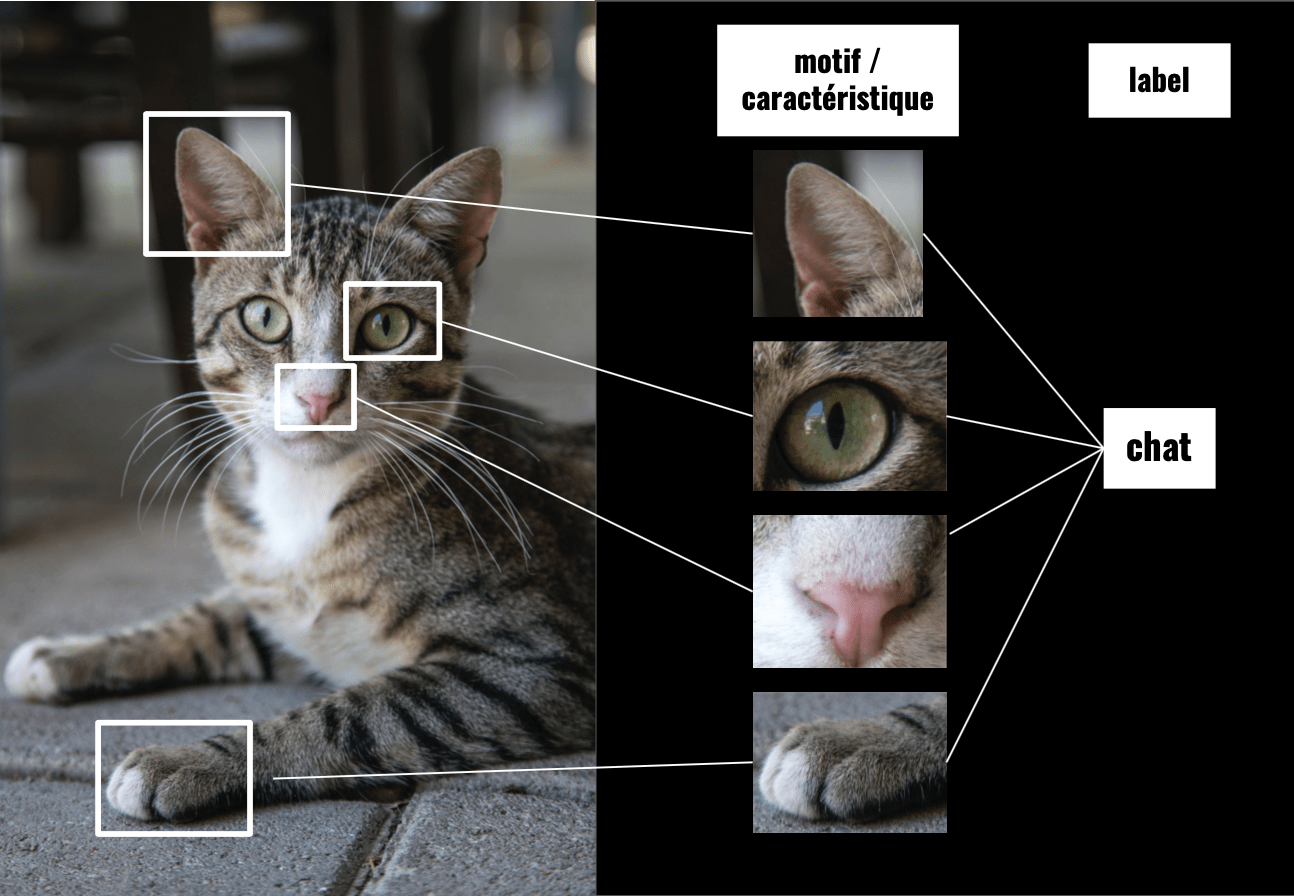
Prenons un exemple plus concret : nous devons repérer si un chat se trouve sur une image.
Un modèle classique analyserait l’image dans sa généralité. Cette approche est efficace mais la précision du modèle pourrait être largement supérieur !
Avec des couches de convolution, le modèle de Deep Learning détecte les zones de l’image qui ressemble à un chat. Ainsi il peut repérer les endroits où se trouve:
- des oreilles
- un museau
- des pattes
Le modèle garde ces caractéristiques en mémoire et comprend qu’ils représentent le label « chat ».
Par la suite, il comprend facilement si un chat se trouve sur une image en recherchant ces caractéristiques.
Cette méthode est bien plus efficace que l’approche classique pour deux principales raisons :
- Moins d’erreur dans l’apprentissage car le modèle n’apprend pas des images mais des caractéristiques, des motifs
- Plus de précision dans la détection, car le modèle doit justement reconnaître des caractéristiques, des motifs
Utiliser un CNN Convolutional Neural Network
Conv2D
Vous l’aurez compris l’important dans les couches de convolution est le motif qu’elles apprennent !
Les CNN peuvent également apprendre la hiérarchie spatiales de ces motifs.
Une première couche de convolution apprendra les petits motifs, une deuxième couche de convolution apprendra des motifs plus importants constitués des caractéristiques des premières couches, etc.
Cela permet aux convnets d’apprendre efficacement des concepts de plus en plus complexes et abstraits.
Lorsqu’on utilise une couche de convolution on va s’intéresser à certains aspects de ces motifs:
- le nombre de neurones, chaque neurone d’une couche appliquant une convolution différente sur l’ensemble de l’image
- la taille du motif, le nombre de pixel qu’il contiendra
- le pas, la distance entre les motifs (elle peut être nulle)
Avec la librairie Keras, on l’utilise comme cela:
from keras import layers
model.add(layers.Conv2D(64, (3, 3), strides=(1, 1), activation='relu')) Ici on a une couche de convolution avec plusieurs paramètres :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
- 64 filtres
- un motif de taille (3, 3), aussi appelé kernel – 3×3 pixels
- un pas de (1,1), aussi appelé strides (par défaut il est égal à (1,1)),
- une fonction d’activation… eh oui les couches de convolution possèdent aussi une fonction d’activation !
Cette couche passe sur chaque pixel de l’image (strides = (1,1)) pour en extraire des motifs de taille 3×3 pixels (kernel = (3,3)). La couche exécute cette action 64 fois (filtres = 64).
Cette couche produit ce qu’on appelle des feature-map 64 feature-maps possédant chacune des caractéristiques différentes de l’image.
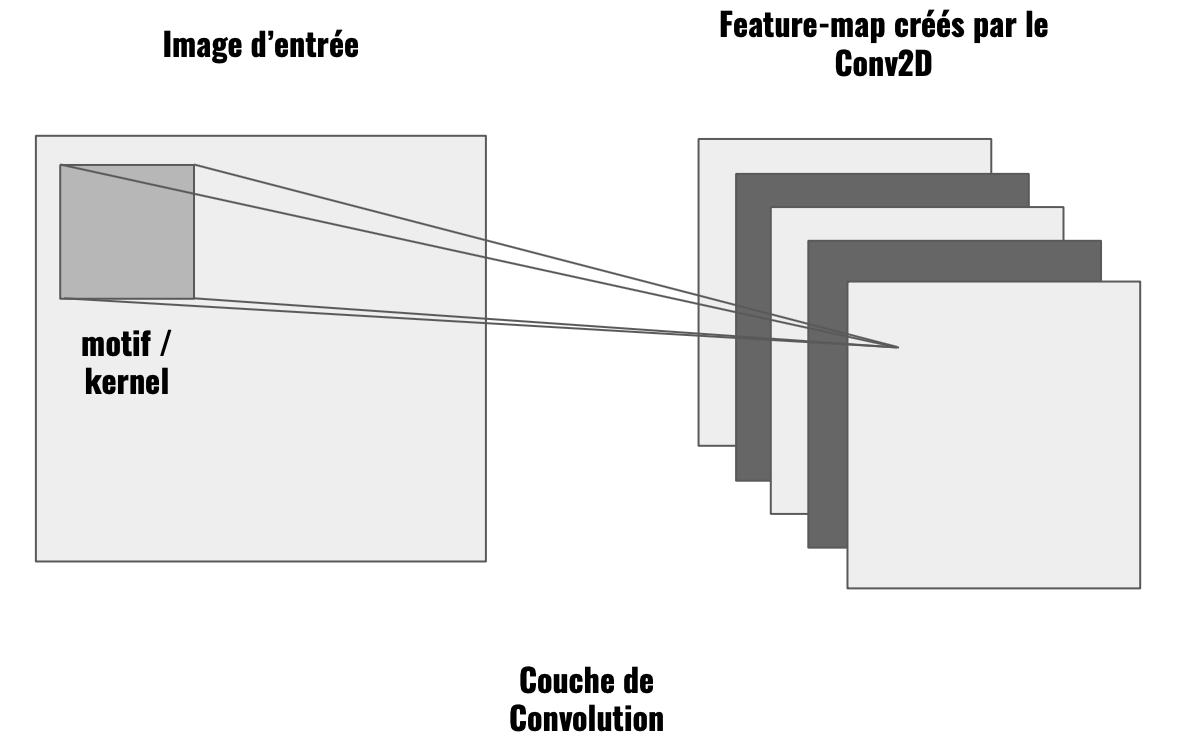
Une couche de convolution Conv2D prend en entrée un image en couleur donc un 3D-tensor et retourne 64 feature-map, donc un 3D-tensor.
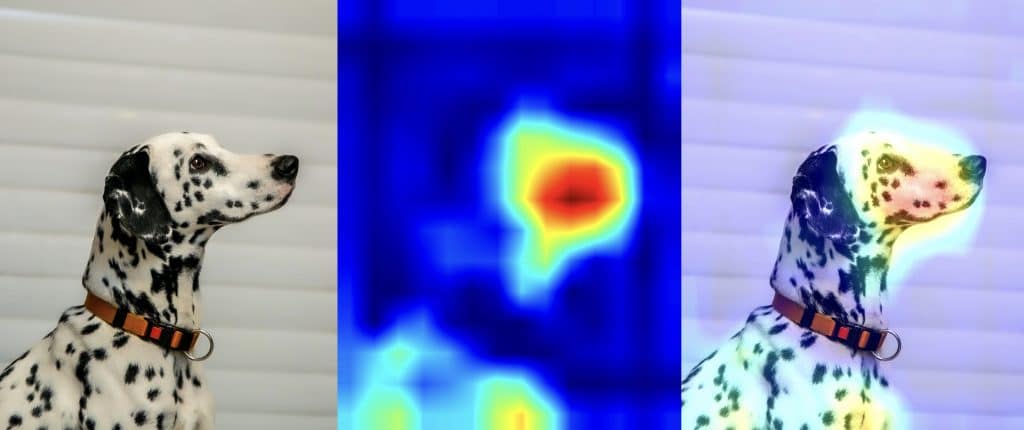
Si vous voulez en savoir plus sur les feature-maps avec des exemples concret, notre article sur GradCam aborde ce concept.
Max Pooling
Avec une couche Conv2D on obtient 64 feature-map, 64 filtre de l’image contenant chacun des caractéristiques. Cela fait beaucoup d’information !
Ces informations sont précieuses mais l’idée principal du Machine Learning est de réduire ces informations pour en faire des données interprétable par l’homme.
Après avoir utilisé une couche Conv2D, il faut donc réduire le résultat obtenu. On peut le faire facilement avec la couche MaxPooling2D.
Le MaxPooling est aussi une couche de convolution. Il extrait des motifs, des tendances d’une donnée.
Mais là où le Conv2D extrait des caractéristiques d’une image pour créer des feature-maps, le MaxPooling2D, lui, extrait la valeur la plus importante de chaque motif des feature-maps.
En fait, le MaxPooling prend en entrée des feature-map pour en extraire la valeur max. Il garde seulement les informations importantes.
Cela permet au modèle de Deep Learning de :
- gagner en précision en gardant seulement les données pertinentes
- gagner en rapidité, l’apprentissage du modèle se fait bien plus vite car la donnée est de plus en plus petite
Le MaxPooling s’utilise comme suit :
from keras import layers
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2), strides=None))La couche MaxPooling a deux paramètres :
- un kernel de taille (2, 2)
- un stride égal à None (None est la valeur par défaut)
On n’a pas spécifié le nombre de filtres car le MaxPooling s’adapte à la couche précédente. La couche prend en entrée les feature-maps créée par le Conv2D et applique le MaxPooling pour réduire la dimension de chacune de ces feature-map !
Flatten
L’idée dans l’analyse d’image par Deep Learning est de donner une image en entrée et de retourner en sortie un label détecté.
Par exemple, on donne une photo d’une forêt à notre modèle, il détecte un arbre et il nous retourne le label ‘arbre’.
On commence donc avec une image en 3 dimensions (hauteur, largeur, couleur), un 3D-tensor, et on finit avec un label à une dimension (une chaîne de caractère), un 1D-tensor.
Une couche de convolution retourne un 3D-tensor, un tenseur à 3 dimensions, ce ne peut donc pas être la couche finale.
On utilise alors une couche appelée Flatten qui permet d’aplatir le tenseur, de réduire sa dimension. Elle prend en entrée un 3D-tensor et retourne un 1D-tensor.
from keras import layers
from keras import models
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax')) C’est une opération simple mais essentielle. La couche Flatten permet d’établir une connexion entre les couches de convolution et les couches de base du Deep Learning.
Elle permet de diffuser la donnée à travers les couches en réduisant sa dimension. La donnée atteint finalement une couche de prédiction, comme la couche Dense, qui permet d’obtenir le label détecté par le modèle de Deep Learning.
Vous pouvez voir l’évolution des dimensions de l’image dans notre schéma du CNN, sur les colonnes de droite :
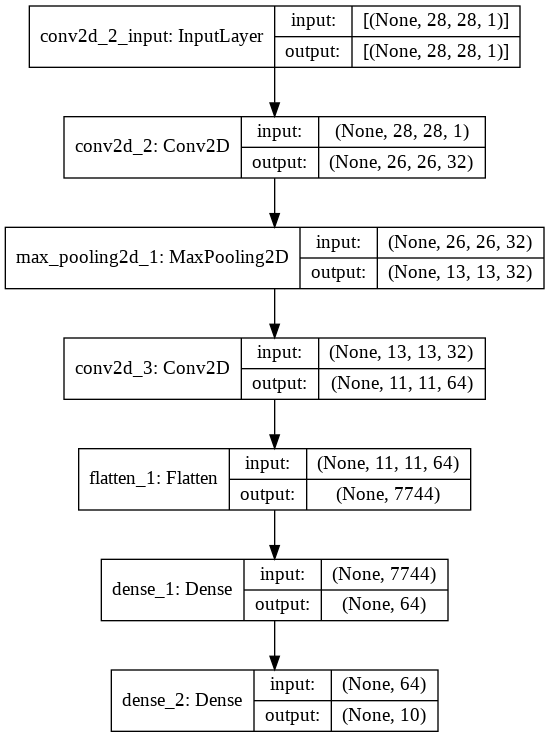
C’est un modèle typique de CNN rassemblant les couches principale que vous utiliserai dans les modèles à convolution.
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Pour y accéder, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



