
Dans cet article, nous allons apprendre à utiliser YOLOv7 : comment l’implémenter, comprendre les résultats et utiliser différents poids !
YOLOv7 est la deuxième version de YOLO qui est publiée cette année 2022.
YOLO signifie You Only Look Once. C’est un modèle de Deep Learning utilisé pour la détection sur les images et les vidéos.
La première version de YOLO a été publiée en 2016. Depuis, des mises à jour fréquentes sont effectuées avec les dernières améliorations : calcul plus rapide, meilleure précision.
Nous avons déjà publié un tutoriel sur comment utiliser YOLOv6. Cet article sera assez similaire car nous voulons nous en tenir aux bases.
Nous utiliserons la même image comme test pour comparer les performances des deux modèles… mais gardez à l’esprit que la performance sur une image n’est pas la performance du modèle entier. C’est juste une indication pour commencer à comprendre les deux modèles.
Voici les résultats de YOLOv7 comparé aux autres versions sur le dataset COCO :
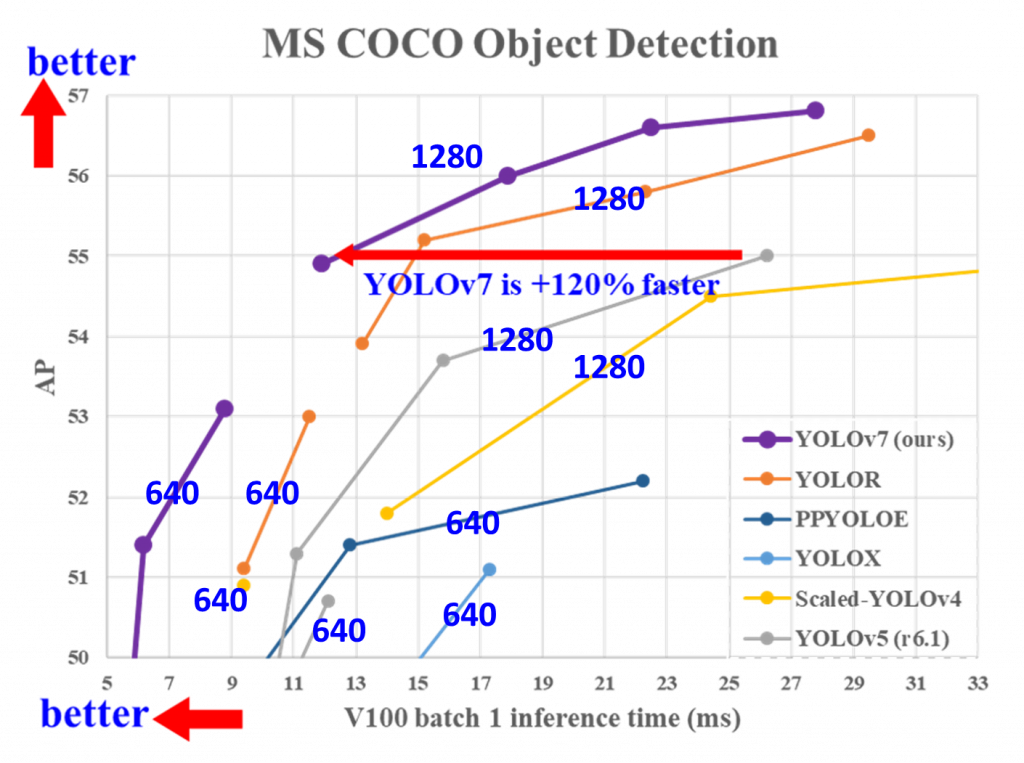
Maintenant, voyons comment l’utiliser !
Comment utiliser YOLOv7 ?
Les lignes de code suivantes fonctionne pour tout instance de Notebook/Colab. Si vous souhaitez exécuter YOLOv7 sur un terminal/en local, il suffit de supprimer le premier « ! » ou « % » de chaque ligne de code.
Pour utiliser YOLOv7, nous devons d’abord télécharger le dépôt Github !
Pour cela, nous allons utiliser la commande git clone pour le télécharger sur notre Notebook :
!git clone https://github.com/WongKinYiu/yolov7.gitEnsuite, on se place dans le dossier qu’on vient de télécharger :
%cd yolov7Puis, nous devons installer toutes les bibliothèques nécessaires pour utiliser YOLOv7.
Les bibliothèques principales sont les suivantes :
- matplotlib
- numpy
- opencv-python
- Pillow
- PyYAML
- requests
- scipy
- torch
- torchvision
- tqdm
- protobuf
Heureusement pour nous, une seule ligne de code suffit pour installer toutes ces dépendances :
!pip install -r requirements.txtIl faut ensuite télécharger les poids du Réseau de Neurones.
Avec la commande git clone, nous avons téléchargé toute l’architecture du Réseau de Neurones (couches du modèle, fonctions pour l’entrainer, l’utiliser, l’évaluer, …) mais pour l’utiliser, nous avons également besoin des poids.
Dans un Réseau de Neurones, les poids sont les informations obtenues par le modèle pendant l’entraînement.
Vous pouvez télécharger manuellement n’importe quelle version des poids ici, puis mettre le fichier dans le dossier yolov7.
Ou téléchargez facilement une des version avec cette ligne de code :
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6e.ptAu moment où j’écris cet article, YOLOv7 vient d’être publié. Des mises à jour peuvent avoir lieu et les poids peuvent changer, ainsi que l’URL de leur dépôt. Si le lien ne fonctionne plus, consultez ce Github pour obtenir la dernière version.
Une dernière chose avant d’utiliser le modèle : uploadez votre image !
Soit une seule image, soit plusieurs dans un dossier (YOLOv7 peut traiter plusieurs images à la fois).
Vous n’avez pas d’images disponible ? Vous pouvez simplement télécharger notre image de test en une ligne de code :
!wget https://raw.githubusercontent.com/tkeldenich/How_to_use_YOLOv7_Tutorial/main/man_cafe.jpg
ENFIN, nous pouvons utiliser YOLOv7 !
Pour cela, nous allons appeler le fichier detect.py.
Le code python contenu dans ce fichier va lancer la détection pour nous.
Nous devons seulement indiquer quelques paramètres importants, dans notre cas :
- les poids que nous utilisons :
--weights yolov7-e6e.pt - l’image sur laquelle nous voulons appliquer la détection :
--source ./man_cafe.jpg
!python detect.py --weights yolov7-e6e.pt --source ./man_cafe.jpgSi vous utilisez votre propre image ou dossier, changez seulement cette dernière partie en ./votre_chemin.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Comprendre nos résultats
Vous trouverez le résultat de la détection dans le dossier yolov7/runs/detect/exp/
Attention ici, si vous faites plusieurs expérimentations, un nouveau dossier expN sera créé. Pour votre deuxième expérimentation, ce sera exp2. Pour la troisième, exp3, etc.
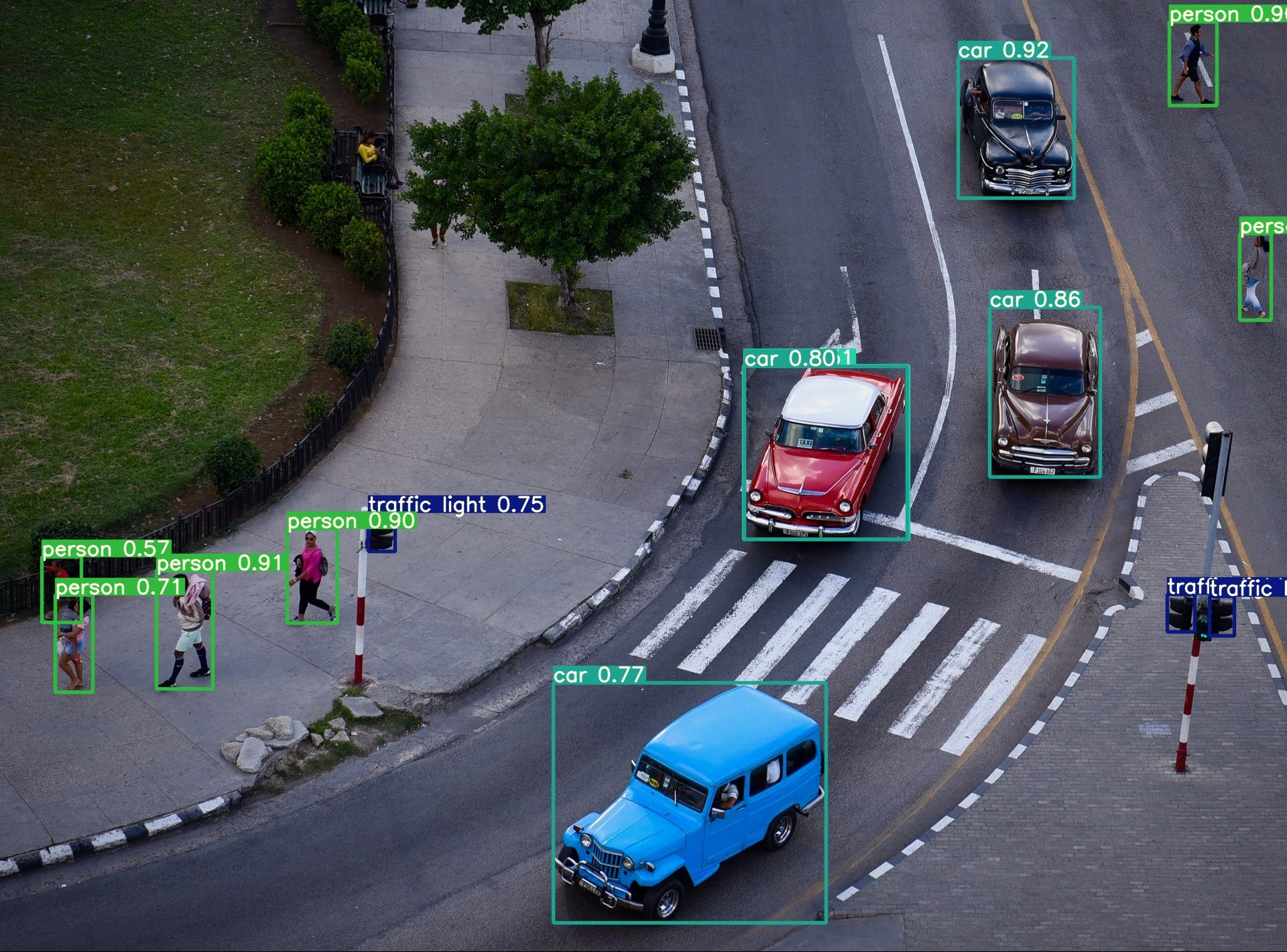
Voici notre résultat :

Tout d’abord, nous pouvons voir que le modèle a une très bonne capacité de détection. Il détecte même la personne juste derrière notre personnage principal.
Vous pouvez voir qu’il indique même la confiance avec laquelle il détecte les objets/personnes. La plupart des objets évidents sont détectés avec un seuil de confiance élevé. En comparaison YOLOv6, il détecte tous les objets sur le premier plan : deux ordinateurs, un téléphone portable, un livre, une tasse. Sur cette image, le modèle est vraiment impressionnant !
Pour l’instant, nous avons un seuil de confiance par défaut de 0,25. Cela signifie que toute détection en dessous du seuil de confiance de 25% sera supprimée.
Le seuil de confiance définit la valeur minimale de confiance à laquelle la détection doit être maintenue.
Il détecte avec 34% de confiance qu’il y a une bouteille sur la table de gauche. Ce qui signifie que YOLOv7 n’est pas du tout sûr de cette prédiction.
Et si nous voulions augmenter ce seuil ?
C’est possible lors du lancement de YOLOv7.
Rappelez-vous que nous avons défini certains paramètres. Les paramètres obligatoires sont les poids et la source (chemin de l’image), mais il y a aussi des paramètres par défaut que vous pouvez modifier selon vos besoins.
Il y a d’autres paramètres, par exemple :
- le seuil de confiance : conf-thres (valeur par défaut : 0.25)
- le seuil d’Intersection over Union : iou-thres (valeur par défaut : 0.45)
Modifions le seuil de confiance à 0.6 :
!python detect.py --weights yolov7-e6e.pt --conf 0.60 --img-size 640 --source ./man_cafe.jpgRésultat :
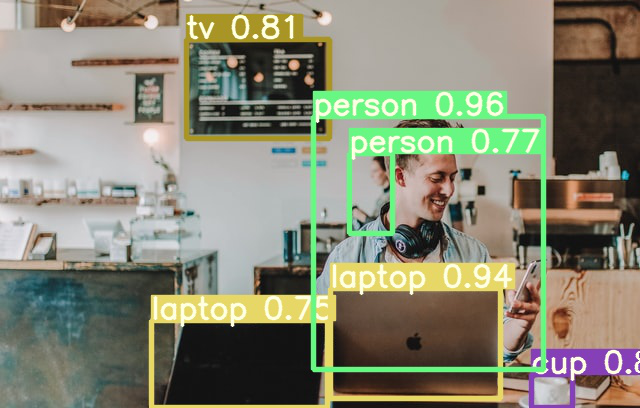
On voit ici que le livra n’a pas été conservée.
Utilisez YOLOv7, faites des hypothèses pour votre projet et définissez le seuil de confiance qui convient à votre besoin 😉 .
Changer de poids
Vous comprenez maintenant un peu mieux ce qu’est YOLOv7.
Allons plus loin.
Il existe différentes versions des poids du modèle.
Nous avons utilisé une version large de ces poids.
Les poids larges signifient trois choses par rapport aux autres versions :
- De meilleurs résultats (ou au moins une meilleure compréhension de la complexité)
- Une vitesse de calcul plus faible
- Plus d’espace mémoire utilisé
Mais qu’en est-il si vous avez des contraintes d’espace et de temps ?
Vous pouvez utiliser d’autres versions de ces poids :
- Petit : https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-tiny.pt
- Moyen : https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
- Grand : https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6e.pt
Encore une fois, vous pouvez les télécharger manuellement sur ce lien puis les mettre dans votre dossier, ou utiliser wget en spécifiant la version que vous voulez :
!wget weight_file_pathSelon la version de poids que vous avez choisie, vous aurez :
- Petit : yolov7-tiny.pt
- Moyen : yolov7.pt
- Grand : yolov7-e6e.pt
Pour l’utiliser, remplacez weight_file ici :
!python tools/infer.py --weights weight_file --source ./man_cafe.jpgTu as quasiment tout ce qu’il te faut pour utiliser YOLO v7.
En effet, peut-être qu’en plus de détecter des objets sur une photo, tu aimerais maintenant apprendre à utiliser ce modèle de pointe sur des vidéos pré-enregistrées.
Peut-être même que tu souhaiterais l’utiliser en temps réel sur un flux vidéo continu.
Il est tout à fait possible d’utiliser YOLO v7 pour ces cas, si ça t’intéresse, j’ai créé la mini-formation gratuite Détection d’Objets Tout-Terrain qui te permettra d’apprendre tout cela :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :




Top, it’s Verry interesting.
Congratulations.
Have you apply yolov7 in ROI Compression ? I need examples.
Article très intéressant! Merci bcp.
Juste une petit question, est ce qu’il n’y aurait une petit coquille sur cette phrase :
Puis, nous devons installer toutes les bibliothèques nécessaires pour utiliser YOLOv6.
Il ne s’agirait pas de YOLOv7 à la place de V6?
Bonjour,
Exact, merci à toi 😉
Bonne journée,
Tom
Merci bien pour vos explications pertinantes.
Comment utiliser Yolo avec la video?
Merci beaucoup.
Bonjour Hammami,
La réponse à ta question est dans l’article, je t’invite à le lire.
À bientôt
Tom
Grand merci cher Ingénieur et maître, cet article m’a beaucoup soulagé et aidé dans mon projet. Soyez béni richement.
Merci