Ici, nous allons explorer le concept de classification binaire : un des types de tâches que l’on peut accomplir en Machine Learning.
Dans le domaine de l’intelligence artificielle, il est possible d’atteindre de nombreux objectifs différents :
- Prédire la probabilité qu’un événement se produise
- Générer des images
- Détecter des anomalies
- Etc.
Ces objectifs peuvent appartenir à des types de tâches distincts. Il est important de savoir les différencier, car le type de tâche auquel on fait face déterminera la méthode a employer.
Dans cet article, nous commencerons par (ré)établir les bases du Machine Learning ce qui nous donnera une connaissance solide pour comprendre, ensuite, ce qu’est la classification binaire.
Remarque : Ici, j’utiliserai le terme « Machine Learning » pour mentionner à la fois le Machine Learning traditionnel et le Deep Learning. Ainsi, ce que tu apprendras dans cet article s’applique aux deux domaines.
L’apprentissage supervisé
Le Machine Learning est une approche permettant d’optimiser automatiquement un algorithme dans le but d’accomplir une tâche.
En Machine Learning, une tâche est un projet dans lequel on doit atteindre un objectif grâce à des données.
Différents types de tâches peuvent être menées à bien grâce à l’optimisation automatique. De plus, il existe de multiple méthodes de Machine Learning. Avant de se lancer dans un projet, il est important de comprendre à quel type s’apparente notre tâche. En effet, la méthode que le praticien utilisera dépend du type de la tâche.
Il existe deux méthodes principales en Machine Learning :
- L’apprentissage supervisé
- L’apprentissage non-supervisé
Remarque : il existe également deux autres méthodes moins connues : l’apprentissage semi-supervisé et l’apprentissage par renforcement.
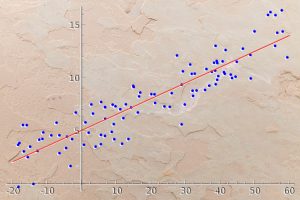
L’apprentissage supervisé est une méthode de Machine Learning dans lequel le praticien entraîne un algorithme sur des données d’entrée ainsi que sur des données de sortie.
Lors de cet entraînement, l’algorithme détecte et apprend les relations existantes entre ces deux types de données.

Grâce à ces relations, l’algorithme établit une règle permettant de produire des résultats à partir de nouvelles données d’entrée qu’il n’a jamais vu auparavant.
Plus les données sur lesquelles l’algorithme est entraîné sont diverses et variées, plus la règle qu’il établit a le potentiel d’être fiable.
La majorité des projets de Machine Learning repose sur l’utilisation d’un ensemble de données composé de données d’entrée et de données de sortie. Par conséquent, cela fait de l’apprentissage supervisé la méthode prédominante dans le domaine du Machine Learning.
Remarque : il existe également des ensembles de données composés uniquement de données d’entrée, dans ce cas il faudra utiliser la méthode d’apprentissage non-supervisé.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
L’apprentissage supervisé englobe plusieurs type de tâches dont la classification binaire fait partie.
La classification binaire
La classification binaire est une tâche de Machine Learning dans laquelle le praticien doit classifier des données d’entrées entre deux catégories, aussi appelées « classes ».
Autrement dit, la classification binaire est le fait de diviser un ensemble de données, aussi appelé « dataset », en deux sous-ensembles distincts.
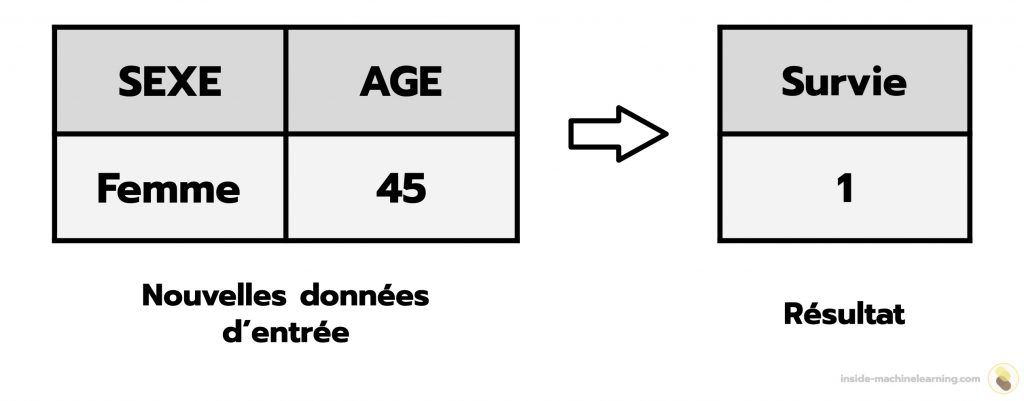
Dans une classification binaire, les données d’entrée sont les caractéristiques des éléments du dataset, et les données de sortie sont les classes associées aux éléments du dataset.
Ainsi, pour entraîner un algorithme, les éléments des données d’entrée sont associées à une classe. On dit alors que les données sont « étiquetées » ou « labellisée ».
Habituellement, un élément est étiqueté comme appartenant à la classe 0 ou, comme appartenant à la classe 1.

0 et 1Entraînement et prédiction
Lors d’un entraînement pour une classification binaire, un algorithme de Machine Learning apprend à associer les éléments d’un dataset à une classe en fonction de leurs caractéristiques ou de leurs attributs.
Par exemple, dans le domaine médical, on peut utiliser une classification binaire pour déterminer si un patient est atteint d’une maladie ou non, en utilisant les caractéristiques du patient telles que les symptômes, les antécédents médicaux, les résultats des tests, etc. Dans le domaine de la détection de spam, on peut utiliser une classification binaire pour distinguer les mails indésirables des mails légitimes en se basant sur des caractéristiques telles que les mots-clés, la syntaxe, etc.
Une fois que l’algorithme est entraîné et a appris à associer les éléments à leur classe correspondante en fonction de leurs caractéristiques, le praticien peut présenter à l’algorithme des données non-étiquetées. L’algorithme entraîné sera alors en capacité d’étiqueter ces nouvelles données – c’est-à-dire de leur attribuer une classe.
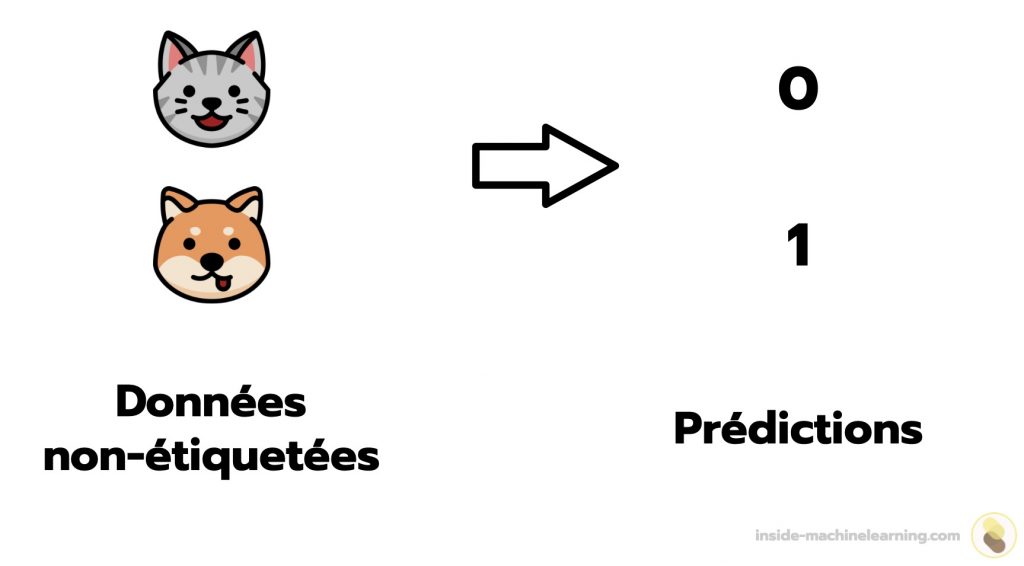
On dit alors que l’algorithme effectue des « prédictions ». Il prédit qu’un élément appartient à une certaine classe en fonction des caractéristiques de cet élément.
La classification binaire est le type de classification le plus courant en apprentissage supervisé. Elle permet de classifier un ensemble de données en deux classes distinctes.
Toutefois, d’autres tâches d’apprentissage supervisé ont également leur importance. Sur mon site, tu trouveras des articles similaires à celui-ci pour explorer les différentes tâches de Machine Learning.
Mais tu peux également accéder à mes bonus privés. À l’intérieur, je résume l’ensemble de mes articles sur le sujet de l’apprentissage supervisé.
Tu trouveras la totalité des points clés et schémas pour maitriser les concepts du domaine :
- classification binaire
- classification multi-classes
- régression
Pour y accéder clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :