

Dans cet article, nous allons explorer une des tâches qu’il est possible d’accomplir en Machine Learning : la régression.
Lorsqu’un ML Engineer travail avec des données étiquetées, il peut faire face à deux types de labels:
- continu
- discret
Selon le type de label, la tâche de Machine Learning à réaliser sera différente. Cela impactera la difficulté du projet, mais également l’approche utilisée pour le mener à bien.
Ici, je te propose d’explorer le cas d’une tâche de régression.
Les différents types de labels
Un label est une valeur spécifique associée à un élément d’un ensemble de données.
Un label continu est une variable quantitative : le nombre de valeurs possibles pour ce label est indénombrable.
Lorsqu’un dataset est étiqueté avec des labels continus, la plupart des lignes possèdent une valeur distincte.
Par exemple, supposons que nous ayons un ensemble de données représentant le prix du loyer dans Paris enregistré annuellement : 2015 – 24,4€/m2, 2016 – 24,8€/m2, 2017 – 24,5€/m2, etc. Ici, le prix du loyer est un label continu car les valeurs sont potentiellement infinis.
À l’inverse, si nous avions un label discret, le nombre de valeurs serait dénombrable. Il serait alors possible de regrouper les individus du dataset en fonction de ce label.
Par exemple, supposons que nous ayons un ensemble de données représentant discrètement l’évolution du prix du loyer dans Paris, enregistré annuellement : 2015 – hausse, 2016 – hausse, 2017 – baisse, etc. Ici, l’évolution du prix du loyer est un label discret car le nombre de valeurs distinctes est dénombrable.
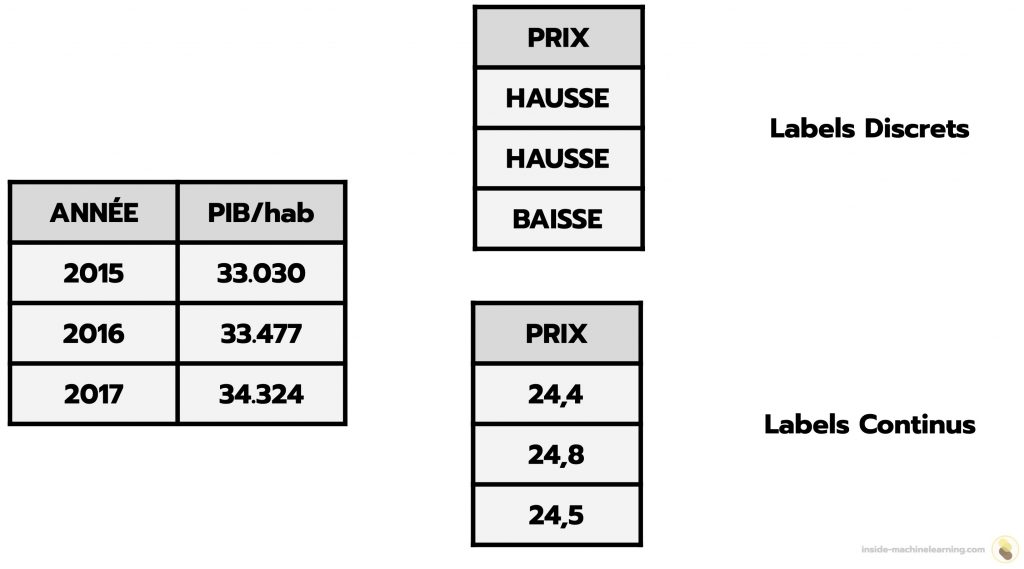
Lorsqu’un label est continu, il regroupe un ensemble de valeurs indénombrables. Cette propriété implique que les individus du dataset sont distincts.
En Machine Learning, l’objectif d’un algorithme est de prédire un (ou des) label. Lorsque ce label est continu, la tâche est appelé « régression ».
La régression
La régression est une tâche de Machine Learning dans laquelle le praticien doit utiliser des données d’entrées pour prédire une valeur numérique.
En d’autres termes, la régression permet de trouver une relation mathématique pour déterminer une valeur en fonction des features d’un dataset.
Difficulté de la régression
Ce type de tâche est particulièrement plus ardu qu’une tâche de prédiction de classe, comme la classification binaire.
En effet, lors d’une classification binaire, seul deux options sont possible: 0 ou 1. Cela implique un risque de succès (et d’échec) moyen de 50%, ce qui est relativement acceptable.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Remarque: tu peux trouver plus d’informations sur la classification binaire dans cet article dédié au sujet.
Au contraire, lors d’une régression, il y autant de résultats possibles que d’individus.
En effet, les labels continus impliquent un nombre exponentiel de possibilités de valeur. Dans ce contexte, le taux d’échec moyen est supérieur à celui de la classification binaire.
La prédiction de variables quantitatives pose ainsi un obstacle plus élevé que la prédiction de classes.
Évaluation de la régression
De surcroît, la régression ne peut pas être évalué aisément.
Lors d’une classification, il est possible de déterminer la qualité d’une prédiction de manière simple: soit la classe prédite correspond à la classe attendue, soit elle n’y correspond pas.
On appelle cette métrique d’évaluation le « recall ».
Mais cette approche est impraticable dans une régression.
Effectivement, lorsque l’on prédit une valeur continue, l’aspect infini du nombre de possibilités implique que le résultat prédit sera très rarement (voir jamais) parfaitement égale au résultat attendu.
Par conséquent, si nous souhaitions comparer la classe prédite à la classe attendue, on aurait un nombre considérable de mauvaises prédictions.
Alors, pour pallier ce problème, d’autres métriques d’évaluation sont utilisées.
Parmi elles, on trouve: la mean squared error (erreur quadratique moyenne) et la mean absolute error (erreur absolue moyenne).
Pour faire simple, ces métriques permettent de calculer l’écart entre la prédiction et le résultat attendu. Plus cet écart est faible, plus la régression est précise.
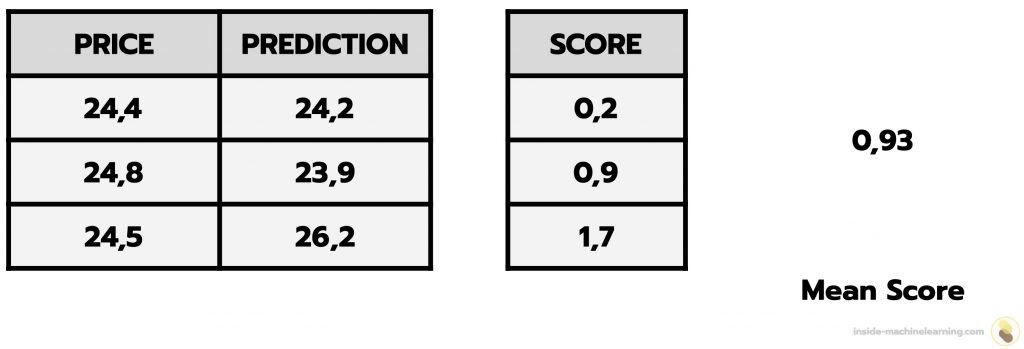
Grâce à cette approche, on peut déterminer la qualité de prédiction de notre modèle!
La régression appartient à une approche de Machine Learning : l’apprentissage supervisé. L’apprentissage est dit « supervisé » car le label guide l’algorithme de Machine Learning dans son apprentissage.
Il permet à l’algorithme de connaître le résultat attendu pour un élément spécifique.
D’autres tâches d’apprentissage supervisé existent. Tu pourras les étudier en naviguant sur mon blog.
Mais tu peux également accéder à mes bonus privés dans lesquels, je résume l’ensemble de mes articles sur le sujet de l’apprentissage supervisé.
Tu trouveras la totalité des points clés et schémas pour maitriser les concepts du domaine :
- classification binaire
- classification multi-classes
- régression
Pour y accéder clique ici :
source:
- Observatoire des Loyers de l’Agglomération Parisienne – Évolution en 2020 des loyers d’habitation du secteur locatif privé dans l’agglomération parisienne
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



