

Voyons en détail ce qu’est la Skewness et le Kurtosis ! Deux mesures de la Data Science pour analyser la disparité dans un dataset.
Quand on fait de la Data Science, il est important de savoir analyser la disparité d’un dataset.
La disparité mesure l’équilibrage dans la répartition des données d’un dataset.
Par exemple, si l’on mesure l’âge des personnes dans un parc de jeux pour enfants dans lequel il y a 20 enfants et 6 adultes. L’âge des personnes de ces personnes sera disparate.
Effectivement, la majorité des personnes sont des enfants, disons entre 4 et 8 ans. Et pour les adultes, il y aura deux babysitter de 20 et 24 ans, 3 parents entre 28 et 35 ans et finalement une grand-mère de 60 ans.
Et parce qu’une image vaut mille mot, voilà le graphe de ces données :
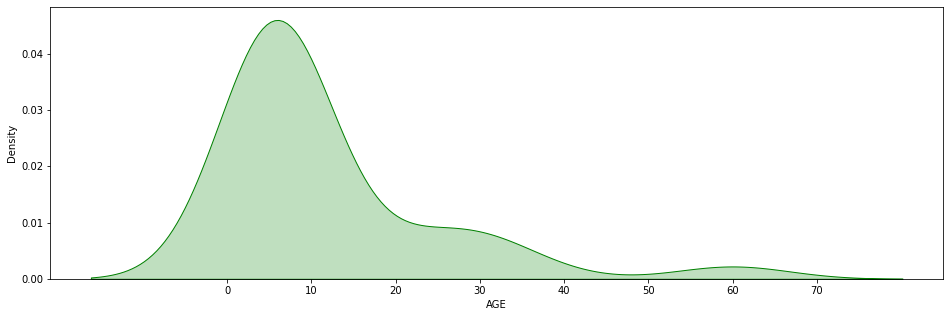
Ici on voit bien que l’ensemble de données est disparate. La plupart des données sont regroupées sur la gauche, quand des individus unique se trouve à droite. On appelle ces données solitaires des « outliers », des données « hors de la norme » ou « hors du cadre ».
Dans ce contexte – à quoi sert la Skewness et le Kurtosis ? Et comment les utilise-t-on dans la Data Science ?
Skewness
Plus haut on a analysé la disparité d’un dataset à l’oeil nu.
Sur le graphe, la disparité est assez évidente car j’ai pris un exemple exagérément déséquilibré. Dans ce cas, l’oeil fait l’affaire pour déterminer la disparité.
Mais il existe des mesures mathématiques pour approfondir cette analyse.
Des mesures beaucoup plus précise qui, quand on les connaît, nous renseignent précisément sur notre dataset.
La première est la Skewness.
La Skewness permet de calculer la symétrie de notre dataset.
Un dataset est symétrique quand les données sont également réparties de part et d’autre de la moyenne.
Lorsque la Skewness est égale 0, le dataset est symétrique.
En calculant la symétrie de notre dataset, on obtient également des informations sur l’asymétrie. Quand un dataset est asymétrique, on dit qu’il est skewed.
Si la Skewness est supérieur à 0, alors le dataset est skewed sur la droite. C’est à dire que la majorité des données se trouvent sur la gauche et les outliers se trouvent sur la droite.
Si la Skewness est inférieur à 0, alors le dataset est skewed sur la gauche. C’est à dire que la majorité des données se trouvent sur la droite et les outliers se trouvent sur la gauche.
Dans notre exemple du parc pour enfant, la Skewness est de 2.47.
Effectivement on peut voir sur le graphique que le dataset est skewed sur la droite :
Les adultes ayant un âge bien plus grand que les enfants, ils déséquilibrent le dataset sur la droite.
Nettoyons un peu le dataset en enlevant tous les adultes.
On obtient ce graphe :
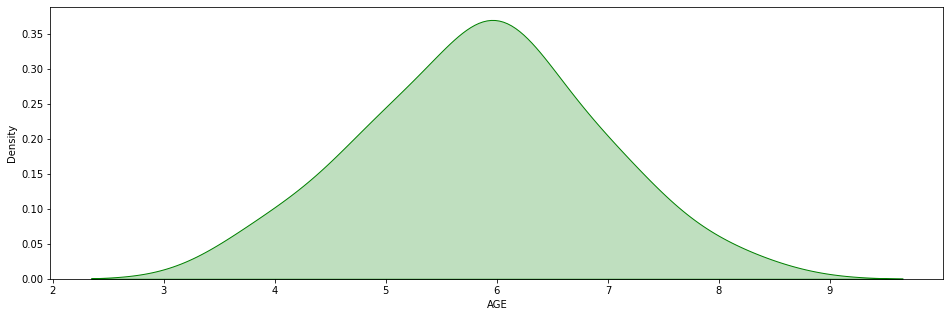
Ici, il y a déséquilibre. Mais il est beaucoup plus difficile à voir à l’oeil nu.
Quand on calcule la Skewness on obtient -0.006.
Le déséquilibre est très léger, sur la gauche cette fois.
C’est la précision de la Skewness qui nous permet de déterminer ce déséquilibre.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
En plus de l’asymétrie, la Skewness permet de calculer la force du déséquilibre. Ici -0.006 indique un très léger déséquilibre. Une valeur de 1 est un déséquilibre normal.
Voici le code pour calculer la Skewness sur un Dataframe Pandas en Python :
df['AGE'].skew()Kurtosis
Le Kurtosis permet lui aussi de calculer la disparité d’un dataset. Mais en utilisant une autre approche.
Le Kurtosis calcule la hauteur des queues du graphe.
La queue désigne essentiellement la partie de la distribution qui est très éloignée de la moyenne.
Plus il y a d’ouliers, plus la queue est épaisse.
Prenons le contexte d’un dataset relativement symétrique comme celui de notre exemple :
Dans notre exemple, le graphe est bossu et symétrique. Cela indique qu’il y a un regroupement des données au niveau de la moyenne.
Nous constatons également que nos queues semblent être normales. Elles ne sont ni trop épaisses ni trop fines.
Comment cela se traduit-il en Kurtosis ?
Ici, le Kurtosis est de -0,03.
Pour un ensemble de données symétriques :
Si le Kurtosis est supérieur à 0, alors l’ensemble de données est leptokurtique, c’est-à-dire que les queues sont plus épaisses que la normale. Cela indique un regroupement d’outliers.
Si le Kurtosis est inférieur à 0, alors l’ensemble de données est platykurtique, c’est-à-dire que les queues sont plus fines que la normale. Cela indique un excès négatif d’outlier. En d’autres termes, la plupart des données ont tendance à se rassembler autour de la moyenne.
Lorsque le Kurtosis est égal à 0, alors l’ensemble de données est mésokurtique, c’est-à-dire que les queues sont les mêmes que dans une distribution normale.
Voici le code pour calculer le Kurtosis sur un dataframe Pandas en Python :
df['AGE'].kurtosis()Attention ne dites surtout pas que le Kurtosis calcule l’aplatissement du graphe, au risque de te faire taper les doigts par des mathématiciens.
Gardons également à l’esprit que : « La queue d’une distribution n’est pas un terme précisément défini. En d’autres termes, il n’y a pas d’endroit spécifique où l’on cesse d’être au milieu de la distribution et où l’on commence à être dans la queue. »
Dataset disparate = mauvais dataset ?
Un dataset disparate n’est pas forcément un mauvais dataset !
Avant tout, la Skewnes & le Kurtosis sont de bons indicateurs pour comprendre tes données. L’interprétation de ce résultat dépendra du contexte de ton projet.
Ces deux métriques sont cruciales dans l’analyse de données.
Pour que tu te rappelles de ces concepts, j’ai préparé un PDF récapitulant les points importants de cette article. En plus de cela tu auras accès gratuitement à 7 jours de conseils pour apprendre l’Intelligence Artificielle. Pour accéder à ces bonus clique ici :
sources :
- Texas A&M University-Commerce – Running Descriptive on SPSS
- Quora – What is the tail of a probability distribution?
skewness kurtosis skewness kurtosis
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :




Simple. Clair. Efficace. Je me devais de laisser un commentaire pour dire à quel point nous avons besoin de ce genre de page internet qui nous font comprendre rapidement une notion et par conséquent apporter des skills chacun respectivement dans nos métiers. un grand merci.
Merci Lola.
Je ne publie plus d’articles, mais si vous êtes intéressé par l’IA, vous pouvez retrouver mes posts sur linkedin en cliquant ici.
Bien à vous,
Tom Keldenich