Dans cet article je vous propose de mêler Data Science et environnement : nous allons faire de l’EDA pour comprendre les feux de forêts.
Chaque année c’est plus 2.8 millions d’hectares de forêts qui sont dévastées par des incendies aux U.S.
Ces incendies sont provoqués à des endroits bien spécifiques. On peut imaginer que certaines caractéristiques environnementales influent sur la propagation des incendies : température, sécheresse, vitesse du vent, etc.
Mais est-ce vraiment le cas ?
Dans ce tutoriel je vous propose de faire de l’Exploratory Data Analysis (EDA) pour comprendre ce qui provoque la propagation des feux de forêts.
Le Dataset forestfires.csv
Nous allons utiliser le dataset forestfires.csv que vous pouvez trouver sur ce lien.
Ce dataset regroupe les caractéristiques météorologiques aux départs d’incendies au Portugal.
L’objectif de ce dataset est de prédire le nombre d’hectares dévastés par incendie en fonction des caractéristiques de l’environnement.
Une fois que vous avez téléchargé le dataset, mettez-le dans votre environnement de travail (Notebook ou local).
On peut maintenant charger le dataset dans un Dataframe Pandas et afficher ses dimensions :
import pandas as pd
df = pd.read_csv("forestfires.csv")
df.shapeSortie: (517, 13)
517 lignes pour 13 colonnes.
On remarque tout d’abord que le dataset est petit. Seulement 517 lignes. Cela peut impacter notre analyse et c’est une information importante à prendre en compte.
Effectivement, plus un dataset est grand, plus on peut généraliser les conclusions de ce dataset. Inversement pour un dataset réduit.
Maintenant, essayons de comprendre les colonnes du dataset en affichant leur type (int, float, string, …) :
df.dtypesJ’affiche ici le type et la description de chacune des colonnes :
- X – int64 – coordonnées X
- Y – int64 – coordonnées Y
- month – object – mois de l’année
- day – object – jour de la semaine
- FFMC – float64 – Fine Fuel Moisture Code – Teneur en humidité des combustibles fins
- DMC – float64 – Duff Moisture Code – Indice d’humidité de l’humus (couche supérieure du sol)
- DC – float64 – Drought Code – Indicateur de la sécheresse des sols
- ISI – float64 – Initial Spread Index – Une estimation numérique de la vitesse de propagation du feu
- temp – float64 – Température en C°
- RH – int64 – Relative Humidity – Humidité relative
- wind – float64 – Vitesse du vent en km/h
- rain – float64 – Pluie en mm/m2
- area – float64 – Surface incendiée de la forêt (en ha)
Ensuite nous pouvons afficher les premières lignes de ce dataset :
df.head()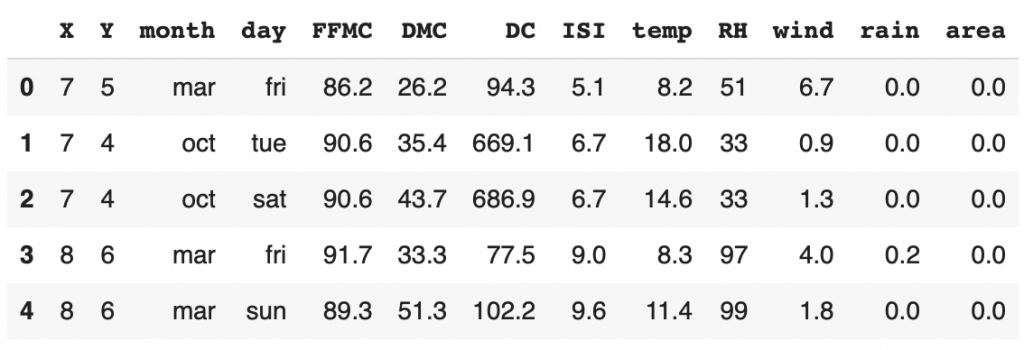
Maintenant que nous avons un bon aperçu de notre dataset, on peut commencer l’EDA avec l’Analyse Univariée.
À noter: certains utiliseront df.describe() pour analyser l’entièreté du dataset en one shot. Je trouve cette méthode trop dense pour une première analyse. Je préfère personnellement effectuer une analyse de chaque feature un par un.
Analyse Univariée
L’Analyse Univariée est le fait d’inspecter chaque feature séparément.
Cela va nous permettre d’approfondir notre connaissance sur le dataset.
On est ici en phase de compréhension.
La question associée à l’Analyse Univariée est : Quelles sont les données qui compose notre dataset ?
Target : Surface impactée par les incendies
Tout d’abord, analysons la cible de ce dataset : la surface impactée par les incendies (area).
On utilise la librairie Seaborn pour afficher la distribution de notre target :
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(16,5))
ax = sns.kdeplot(df['area'],shade=True,color='g')
plt.show()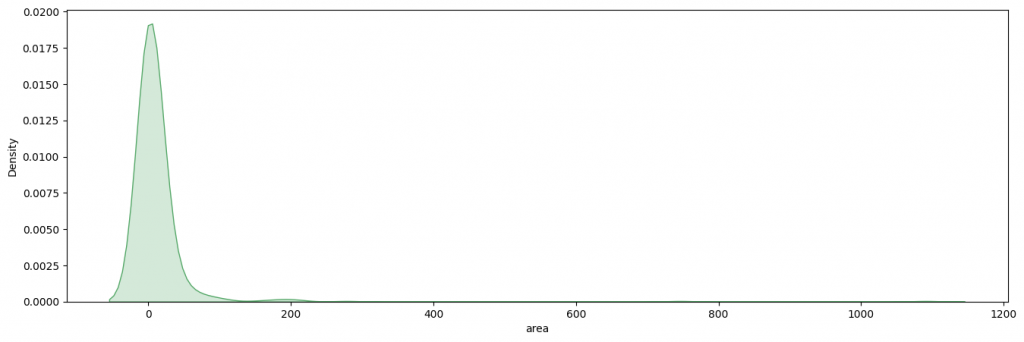
On voit ici que la plupart des feux de forêts ont détruit moins de 100 hectares de forêts et que la majorité en ont détruit 0.
Poussons un peu plus l’analyse en utilisant une boîte de Tukey . Cela nous permettra de comprendre distribution de la target en affichant la médiane, les quartiles déciles et valeurs extrêmes :
plt.figure(figsize=(16,5))
ax = sns.boxplot(df['area'])
plt.show()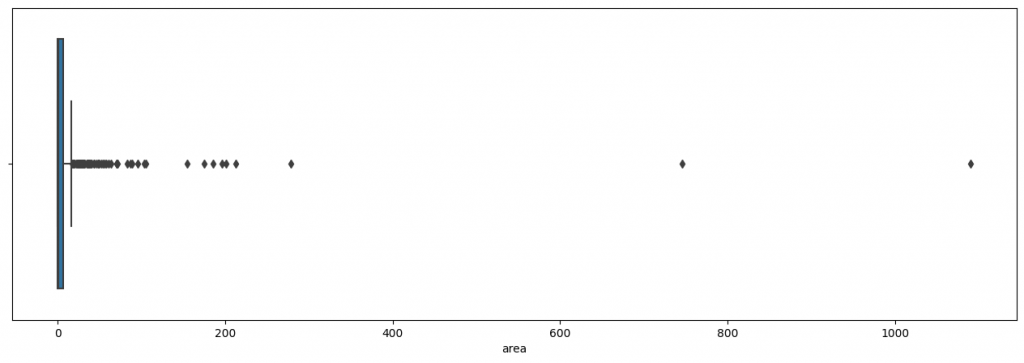
Ici le graphique est impossible à analyser.
Effectivement les valeurs extrêmes sont tellement éloignées de la médiane qu’il nous est impossible de voir clairement la boîte de Tukey
On aimerait quand même analyser cette boîte. Alors, en plus de l’afficher, on va zoomer dedans :
plt.figure(figsize=(16,5))
ax = sns.boxplot(df['area'])
ax.set_xlim(-1, 40)
plt.show()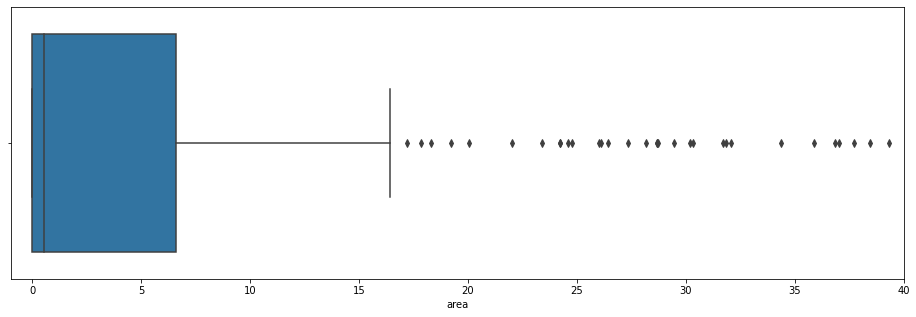
C’est bien plus lisible !
On voit ici que la moyenne est entre 0 et 1. Le troisième quartile est à 6. Et le neuvième décile est à 16.
Tous les valeurs au dessus de 16 sont des valeurs extrêmes. C’est à dire que très peu de valeur se situe à cette échelle.
Les valeurs les plus extrêmes sont appelés les « outliers ». On peut afficher la Skewness et le Kurtosis pour évaluer la disparité de ces valeurs extrêmes :
Vous ne savez pas ce qu’est la Skewness et le Kurtosis ? N’hésitez pas à lire notre court article sur le sujet pour en savoir plus 😉
print("Skew: {}".format(df['area'].skew()))
print("Kurtosis: {}".format(df['area'].kurtosis()))Sortie:
Skew: 12.84
Kurtosis: 194.14
Les valeurs de ces deux métriques sont énorme ! Cela explique pourquoi on a dû zoomer dans notre graphe.
La Skewness nous indique que la majorité des données se trouvent sur la gauche et les outliers se trouvent sur la droite.
Le Kurtosis nous indique que les données ont tendances à s’éloigner de la moyenne.
C’est bien ce qu’on a vu sur notre graphique.
Avec ces deux métriques on peut comprendre à quelle point les outliers affectent notre target.
Passons maintenant à l’analyse de ces outliers.
Z-Score & Outliers
Vous l’avez vu dans la boîte de Tukey, il y a beaucoup de valeurs extrêmes.
Mais attention toutes ces valeurs extrêmes ne sont pas forcément des outliers.
Effectivement il est normal dans toute distribution d’avoir des valeurs extrêmes.
Par contre, il est peu fréquent, voire anormal d’avoir des outliers. Cela peut indiquer une erreur dans le dataset.
Alors affichons ces outliers pour déterminer s’il s’agit d’une erreur.
Pour déterminer les outliers, on utilise le z-score.
Le z-score calcule la distance d’un point avec la moyenne.
Si le z-score est inférieur à -3 ou supérieur à 3, il est considéré comme un outlier.
Voyons ça en affichant tous les points inférieur à -3 et supérieur à 3 :
from scipy.stats import zscore
y_outliers = df[abs(zscore(df['area'])) >= 3 ]
y_outliers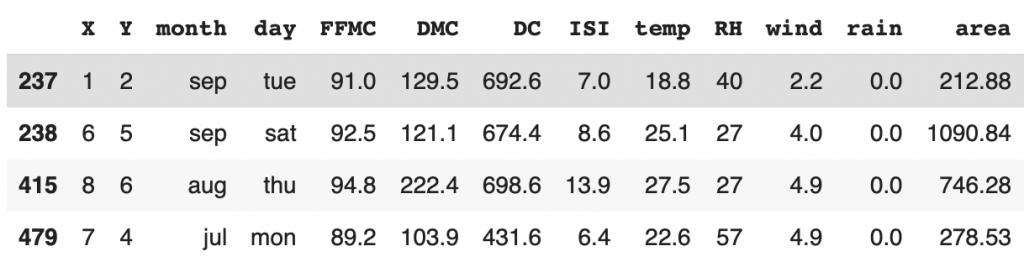
Nous avons 4 outliers et bonne nouvelle pour nous, cela semble être des données correctes.
Pas d’erreur dans le dataset !
On a donc une distribution assez particulière de notre target, qu’il faudra garder en mémoire pour la suite du projet.
Passons maintenant à l’analyse de nos features.
Données catégoriques
Dans un dataset, il faut différencier plusieurs types de données :
- les données catégoriques
- les données numériques
L’analyse de ces deux types de données sera différente. Je vous propose donc d’extraire chacune d’entre elles dans deux sous-Dataframe :
- colonnes catégoriques
- colonnes numériques
Avec Pandas c’est facile ! il faut simplement utiliser la fonction select_dtypes et indiquer include='object' pour les données catégoriques et exclude='object' pour les données numériques :
dfa = df.drop(columns='area')
cat_columns = dfa.select_dtypes(include='object').columns.tolist()
num_columns = dfa.select_dtypes(exclude='object').columns.tolist()
cat_columns,num_columnsSortie:
([‘month’, ‘day’], [‘X’, ‘Y’, ‘FFMC’, ‘DMC’, ‘DC’, ‘ISI’, ‘temp’, ‘RH’, ‘wind’, ‘rain’])
Nous avons deux données catégoriques : les mois et les jours.
Le reste représente des données numériques.
On peut analyser directement les données catégoriques !
Affichons leur distribution :
plt.figure(figsize=(16,10))
for i,col in enumerate(cat_columns,1):
plt.subplot(2,2,i)
sns.countplot(data=dfa,y=col)
plt.subplot(2,2,i+2)
df[col].value_counts(normalize=True).plot.bar()
plt.ylabel(col)
plt.xlabel('% distribution per category')
plt.tight_layout()
plt.show()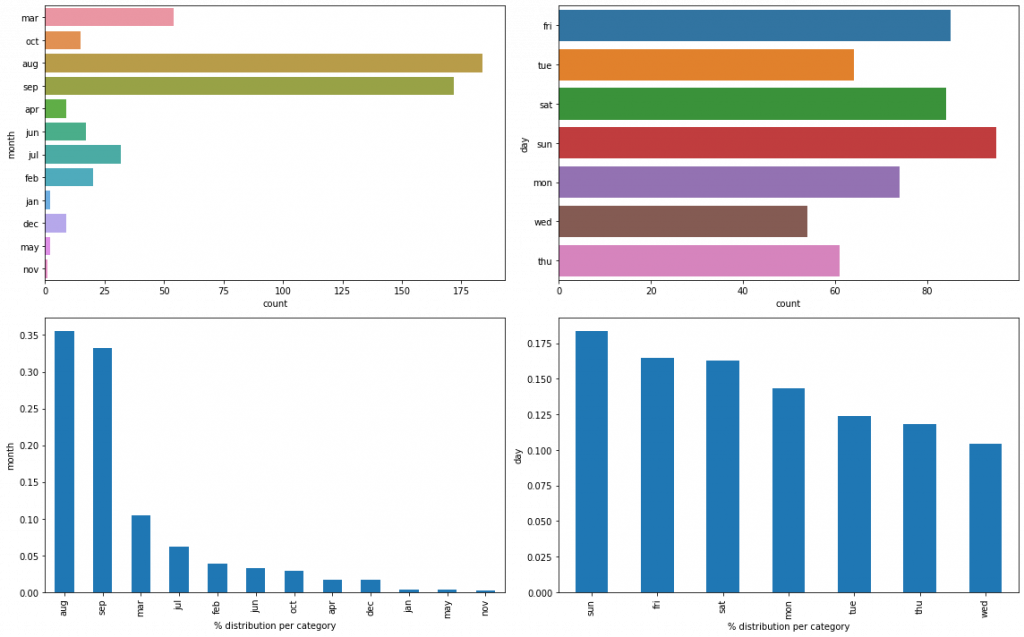
Rappel : chaque ligne de notre dataset représente un feux de forêt.
Ici, on voit que la plupart des feux de forêt ont lieu en août et septembre. Cela semble logique étant donné que ce sont les mois les plus chaud de l’année.
La distribution selon les jours de la semaine, au contraire, est plus équilibrée. Mais on voit que le dimanche, samedi, vendredi ressortent plus souvent que les autres jours.
Les jours de weekend sont donc les jours où il y a le plus souvent des feux de forêts. Cela corroborerait les informations du U.S.Department of Agriculture qui indique que 85% des feux de forêts sont la cause d’êtres humains. Avons-nous une statistique similaire au Portugal ?
Données numériques
Continuons notre analyse avec les données numériques.
Ici, l’analyse sera la même qu’avec la target :
- comprendre la distribution
- évaluer les outliers
Quand on fait ce genre d’analyse, on se pose la question : y-a-t-il un pattern se répétant dans notre graphique ?
Affichons les données concernant la pluie :
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.kdeplot(df['rain'],color='g',shade=True)
plt.subplot(1,2,2)
df['rain'].plot.box()
plt.show()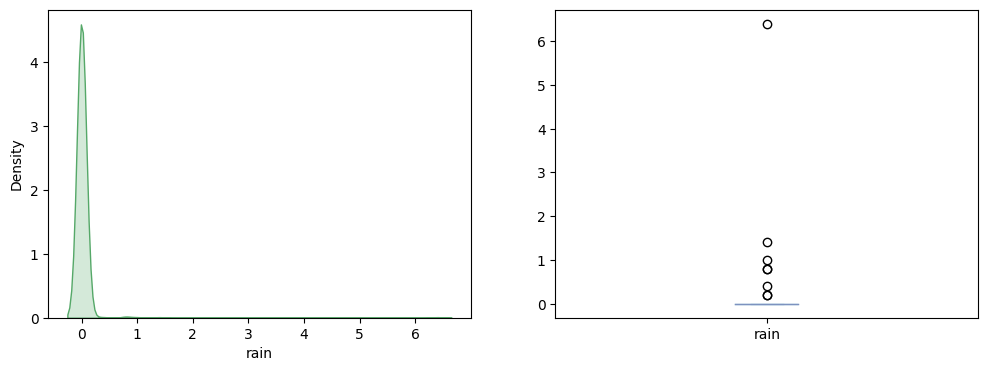
On voit que lors des jours d’incendies, la plupart du temps, il n’y a pas de pluie. Cela semble logique, l’humidité causé par la pluie n’étant pas propice au feu.
En juillet 2021, les feux de forêts en Turquie ont eu lieu alors qu’il faisait 40°C en température extérieur.
Les feux de forêts sont-ils en lien avec la température ?
Voyons cela dès maintenant :
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.kdeplot(df['temp'],color='g',shade=True)
plt.subplot(1,2,2)
df['temp'].plot.box()
plt.show()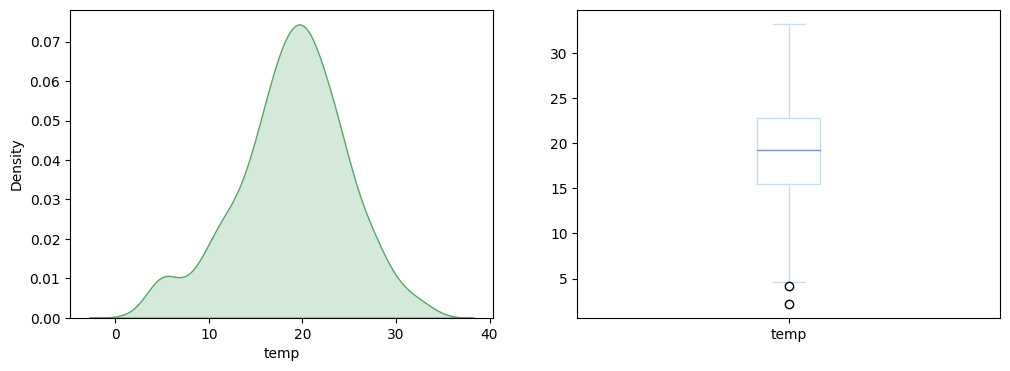
De manière surprenante, on voit que les feux de forêts au Portugal n’ont pas l’air corrélés à la température extérieur. Cela infirme notre hypothèse.
Je vous invite maintenant à essayer chez vous d’afficher les graphiques des autres données numériques.
Vous pouvez le faire en one shot avec ce bout de code :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
plt.figure(figsize=(18,40))
for i,col in enumerate(num_columns,1):
plt.subplot(8,4,i)
sns.kdeplot(df[col],color='g',shade=True)
plt.subplot(8,4,i+10)
df[col].plot.box()
plt.tight_layout()
plt.show()
num_data = df[num_columns]Le résultat n’est pas affiché ici par manque de place. Mais l’analyse sur le FFMC, DMC et DC sont particulièrement intéressantes !
C’est aussi là le travail d’un Data Scientist. Nous sommes expert dans la data mais nous devons comprendre les indicateurs qui concerne notre données.
Allez faire un tour sur Google pour comprendre ce que signifie ces indicateurs et si les résultats graphiques semblent cohérents. Donnez votre réponse en commentaire 😉
Finalement on peut utiliser à nouveau la Skewness et le Kurtosis pour détecter nos outliers:
pd.DataFrame(data=[num_data.skew(),num_data.kurtosis()],index=['skewness','kurtosis'])
FFMC, ISI et rain sont les 3 colonnes avec une valeur de Skewness et Kurtosis extrêmes et donc avec des outliers.
Analyse Bivariée
Maintenant qu’on a compris nos données grâce à l’Analyse Univariée on peut poursuivre le projet en essayant de repérer des liens entre nos features et la surface impactée par les feux de forêts.
L’Analyse Bivariée est le fait d’inspecter chacun des features en les mettant en relation avec notre target.
Cela va nous permettre d’émettre des hypothèses sur le dataset.
On est ici en phase de théorisation.
La question associée à l’Analyse Bivariée est : Y-a-t-il un lien entre nos features et la target ?
S’il y a une relation linéaire, par exemple entre FFMC et notre target, alors on pourra facilement prédire la surface impactée.
Eh oui, si plus le FFMC augmente, plus la surface impactée est grande, il sera facile de tracer une relation linéaire entre ces deux données. Et donc de prédire la target !
Mais sera-ce aussi simple ?
Voyons cela dès maintenant !
Features catégoriques
Tout d’abord je vous propose de modifier notre target. En plus d’avoir des données numériques précisant la surface impactée, il serait bien d’avoir des données catégoriques pour effectuer d’autres analyses.
Si la surface impactée est de 0 ha, on indique « Aucun dommage », si elle est inférieur à 25 « Dommage modéré », inférieur à 100, « Dommage sévère », plus de 100 « Dommage très sévère » :
def area_cat(area):
if area == 0.0:
return "No damage"
elif area <= 25:
return "moderate"
elif area <= 100:
return "high"
else:
return "very high"
df['damage_category'] = df['area'].apply(area_cat)
df.sample(frac=1).head()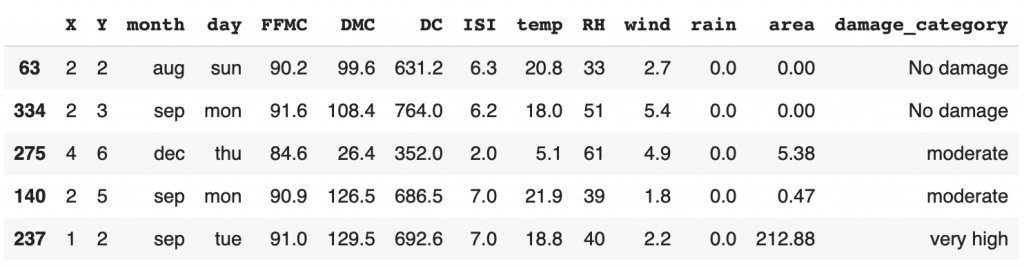
Comme vous pouvez le voir ici, nous n’avons pas supprimé la colonne « area ». Nous avons simplement ajouter une colonne qui nous permettra d’effectuer différent types d’analyses.
On peut utiliser cette nouvelle colonne en les comparants à nos données catégoriques « mois » et « jour de la semaine » :
import numpy as np
plt.figure(figsize=(15,30))
sns.set(rc={'axes.facecolor':'#DEDEDE', 'figure.facecolor':'white'})
for col in cat_columns:
cross = pd.crosstab(index=df['damage_category'],columns=df[col],normalize='index')
cross.plot.barh(stacked=True,rot=40,cmap='hot')
plt.xlabel('% distribution per category')
plt.xticks(np.arange(0,1.1,0.1))
plt.title("Forestfire damage each {}".format(col))
plt.show()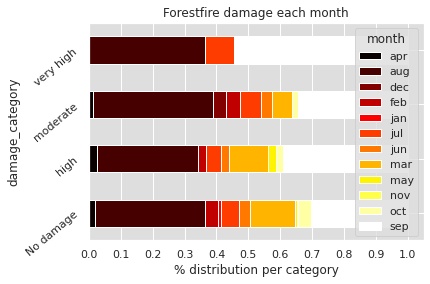
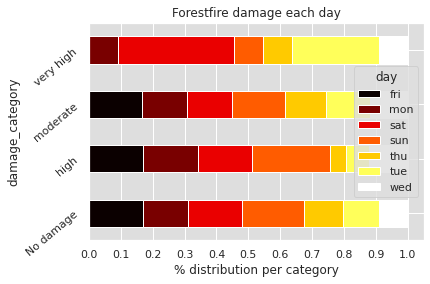
Sur le premier graphique, on peut voir à quel moment de l’année se produisent les incendies les plus dévastateurs. La plupart ont lieu en septembre, en août et une petite partie en juillet.
Dans l’Analyse Univariée, on a vu qu’il y avait une corrélation entre mois de l’année et feux de forêts. Ici on approfondit cette analyse : il semble il y avoir une corrélation entre mois de l’année et surface impactée par les feux de forêts.
Concernant les jours de l’année, on voit que la surface impactée n’a pas l’air d’en dépendre particulièrement.
Dans l’Analyse Univariée, on a vu que c’est pendant les jours de weekend que se produisent le plus souvent les feux de forêts. Néanmoins cela ne semble pas impactée la surface détruite par les feux de forêts. Cette dernière étant sûrement plus impactée par les conditions météorologiques et environnementales que par les jours de la semaine.
Features numériques
Pour afficher le graphique précédent, nous avons modifier les configurations de base de Matplotlib avec sns.set(rc={'axes.facecolor':'#DEDEDE', 'figure.facecolor':'white'}). Réinitialisons-les :
import matplotlib
matplotlib.rc_file_defaults()On peut continuer notre analyse.
Y-a-t-il un lien entre la vitesse du vent et la surface impactée par les feux de forêts ?
Le vent pouvant participer à la propagation du feu, c’est une analyse non négligeable à faire :
plt.figure(figsize=(8,4))
sns.scatterplot(data=df,x='area',y='wind')
plt.show()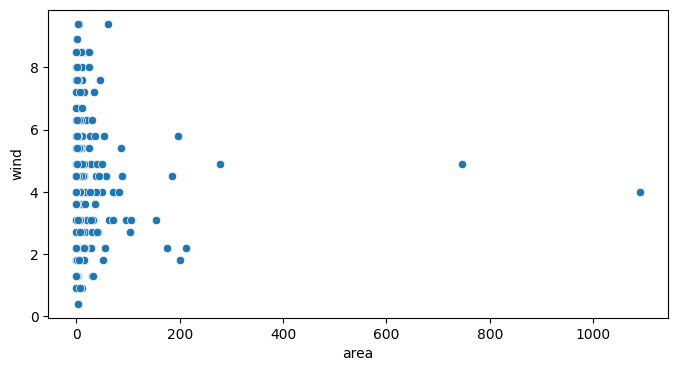
Ici nous avons repris les données target numériques. Nous les avons mis en relation avec le vitesse du vent. Néanmoins, on ne voit aucune relation entre ces deux données.
Comme pour l’Analyse Univariée, je vous invite à répéter cette analyse sur toutes nos données numériques.
Ce bout de code vous aidera à le faire en one shot :
plt.figure(figsize=(10,30))
acc = 1
for i,col in enumerate(num_columns,1):
if col not in ['X','Y']:
plt.subplot(8,1,acc)
sns.scatterplot(data=df,x='area',y=col)
acc += 1
plt.show()Affichez le résultat pour essayer de trouver une corrélation !
Formule de Pearson & Heatmap
Le résultat de l’analyse graphique est peu concluant. On ne voit aucune corrélation qui ressort entre nos features numériques et la target.
Est-ce vraiment le cas ?
On peut calculer mathématiquement une corrélation entre deux données grâce à la Formule de Pearson.
Si le sujet vous intéresse, nous avons expliqué en détails dans ce court article ce qu’est la Formule de Pearson et comment l’interpréter.
Avec Pandas et Seaborn on peut calculer facilement cette corrélation avec la fonction sns.heatmap(df.corr()):
plt.figure(figsize=(15,2))
sns.heatmap(df.corr().iloc[[-1]],
cmap='RdBu_r',
annot=True,
vmin=-1, vmax=1)
On appelle cela une heatmap et on pourrait l’afficher pour l’entièreté de notre dataset. Par exemple pour calculer la corrélation entre FFMC et DMC. Mais ce qui nous intéresse ici est de savoir s’il y a une corrélation entre nos features et notre target.
Le résultat graphique semble se vérifier grâce à la Formule de Pearson : il n’y a pas de corrélation entre les features numériques et notre target.
Ici, je vous met le bout de code qui vous affichera la heatmap pour l’entièreté de notre dataset :
sns.set(font_scale=1.15)
plt.figure(figsize=(15,15))
sns.heatmap(
df.corr(),
cmap='RdBu_r',
annot=True,
vmin=-1, vmax=1);Je vous invite à afficher vous-même le résultat. Y-a-t-il une corrélation entre chacun de nos features ? Donnez votre réponse dans les commentaires 😉
Analyse Multivariée
L’analyse Bivariée nous a permis de comprendre un peu plus nos données.
Nous avons notamment trouvé une relation entre les mois de l’année, et la surface impactée par les incendies.
Néanmoins, cela ne nous a pas permis d’émettre d’hypothèses concluantes pour prédire le nombre d’hectares brûlés par les feux de forêts.
On continue alors notre projet avec l’Analyse Multivariée.
L’Analyse Multivariée est le fait d’inspecter plusieurs features à la fois en les mettant en relation avec notre target.
Cela va nous permettre d’émettre des hypothèses sur le dataset.
On est toujours en phase de théorisation.
La question associée à l’Analyse Multivariée est : Y-a-t-il un lien entre plusieurs de nos features et la target ?
S’il y a un lien, par exemple entre la température, l’humidité relative (RH) et la target, on pourra prédire la surface impactée.
Effectivement, on peut imaginée que plus la température augmente, plus l’humidité relative (RH) diminue (relation déterminée grâce à la heatmap précédente) et donc que la surface impactée augmente elle aussi. On pourra alors utiliser un Decision Tree pour prédire la target !
Features Numériques
Analysons ces features dès maintenant :
sns.set_palette('ch:s=.25,rot=-.25')
sns.relplot(
x='temp',
y='RH',
data=df,
#palette='bright',
kind='scatter',
hue='damage_category');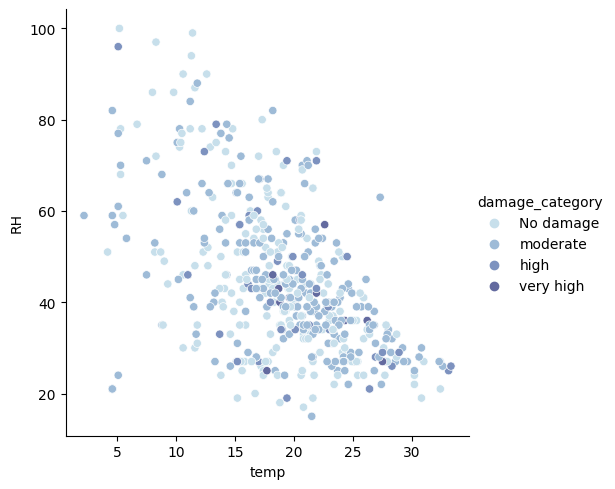
Tout d’abord, on confirme le lien visuelle entre RH et la température. Effectivement, plus la température augmente, plus l’humidité baisse. Néanmoins cela n’influence pas la surface impactée par le feux.
Effectivement, les dommages causés par les feux sont réparties aléatoirement sur le graphique.
Affichons une autre relation. Par exemple entre le FFMC et le vent :
sns.relplot(
x='FFMC',
y='wind',
data=df,
#palette='bright',
kind='scatter',
hue='damage_category');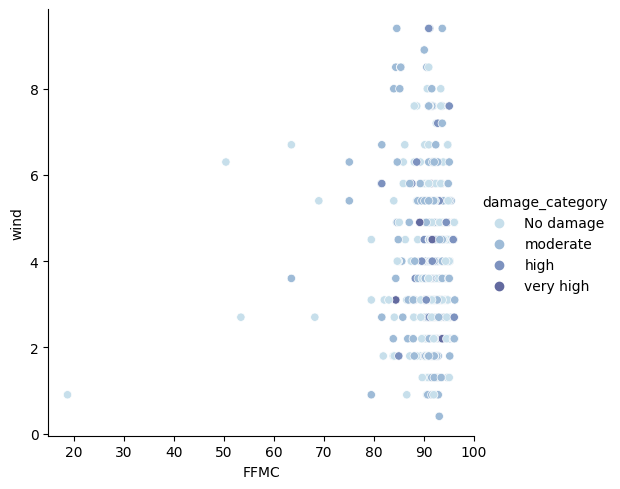
Là non plus pas de corrélation. Ni entre le vent et le FFMC. Ni entre ces deux données et la surface impactée par le feu.
Au lieu d’afficher un à un ces graphiques, on peut les afficher tous en même temps.
Pour cela, on sélectionne les features numériques :
selected_features = df.drop(columns=['damage_category','day','month','area']).columns
selected_features[‘X’, ‘Y’, ‘FFMC’, ‘DMC’, ‘DC’, ‘ISI’, ‘temp’, ‘RH’, ‘wind’, ‘rain’]
Puis on affiche la relation entre chacun de ces features et notre target :
sns.pairplot(df,hue='damage_category',vars=selected_features)
plt.show()Afficher le résultat de votre côté 🔥
Trouvez-vous des corrélations ? Que faire si c’est le cas ? Que faire sinon ?
Conclusion
Dans cet article, nous avons utilisé la Data Science pour analyser le dataset forestfires.csv.
Pour comprendre ce dataset nous avons utilisé l’Exploratory Data Analysis (EDA), notamment avec l’analyse :
- Univariée
- Bivariée
- Multivariée
Vous connaissez maintenant l’utilité de chacune de ces analyses.
Je vous invite à refaire ce projet de votre côté et de partager vos conclusions.
Les données sont-elles suffisantes pour prédire la surface impactée par les incendies ?
Ou au contraire y-a-t-il un défaut pertinence dans nos données ?
Ces deux conclusions peuvent subvenir dans tout projet de Data Science et une analyse approfondie est nécessaire pour le déterminer.
À bientôt dans un prochain article 😉
data science environnement data science environnement data science environnement data science environnement data science environnement data science environnement data science environnement data science environnement
sources :
- Kaggle – Forestfire Impact Prediction
- National Park Service – Wildfire Causes and Evaluations
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :