
Les 13 librairies Data Science essentielles à connaître pour faire de l’analyse de données et comprendre son dataset.
La Data Science est le domaine qui rassemble la manipulation, l’analyse et la compréhension des données.
Python est le langage le plus utilisé dans ce domaine. Mais quelles sont les librairies de Data Science à connaître absolument ?
C’est ce qu’on voit dans cet article !
Pandas – Librairies Data Sciences
On ne la présente plus !
La bibliothèque Pandas est la base pour tout Data Scientist.
Elle permet de manipuler facilement les données. De les extraire d’un fichier excel, csv, txt, et même d’une page web !
Mais aussi de faire des opérations entre colonnes, lignes et cellules d’un DataFrame.
C’est l’idéal pour travailler avec tout type de données : entier, float, texte, date, etc.
Pour l’utiliser :
pip install pandasimport pandas as pdNumpy – Librairies Data Sciences
Numpy permet de travailler facilement avec des Array (tableau).
Il rentre facile la réalisation d’opérations mathématiques complexes grâce à son set de fonctions.
En plus de cela, son temps de calcul est faible ce qui te permet d’exécuter rapidement ton code.
Pour l’utiliser :
pip install numpyimport numpy as npScipy – Librairies Data Sciences
Scipy est une extension de Numpy.
Il permet de pousser encore plus loin les calculs notamment pour faire :
- de l’optimisation
- des statistiques
- du traitement de signal
- de l’algèbre linéaire
Pour l’utiliser :
pip install scipyimport scipyMatplotlib – Librairies Data Sciences
Tu veux afficher des graphiques sans prise de tête ?
Matplotlib est la librairie qu’il vous faut !
Elle permet de faire des graphiques simples mais performant. Que ce soit via des DataFrame Pandas ou des Array Numpy.
Avec Matplotlib tu peux faire des :
- graphiques à intervalles continues
- graphiques à intervalles discontinues
- nuages de points
- boîtes de Tukey
- diagrammes en bâton
- diagrammes circulaire (camembert)
- volumes 3D
- heatmap
- visualisations de séries temporelles
… et bien d’autres ! Je te laisse explorer la documentation pour voir l’étendu de Matplotlib.
Pour l’utiliser :
pip install matplotlibimport matplotlib.pyplot as pltSeaborn – Librairies Data Sciences
Comme Scipy est une extension de Numpy, Seaborn est une extension de Matplotlib
Son apport majeur ?
Une utilisation plus agréable de Matlpotlib. Seaborn à des fonctions pré-implémenter permettant de tracer des graphes stylisés en une seule ligne de code.
Exemple en image :
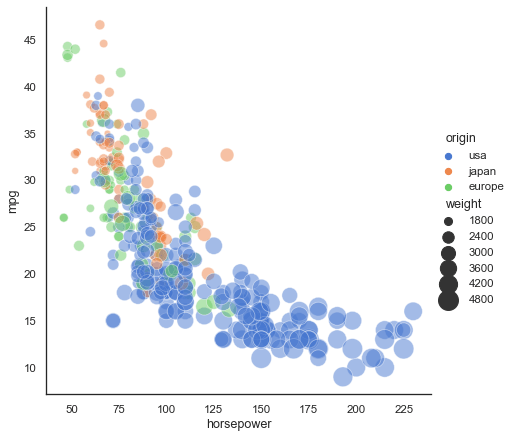
Et la ligne de code les trois lignes de code pour reproduire l’exemple:
import seaborn as sns
sns.set_theme(style="white")
# Load the example mpg dataset
mpg = sns.load_dataset("mpg")
# Plot miles per gallon against horsepower with other semantics
sns.relplot(x="horsepower", y="mpg", hue="origin", size="weight",
sizes=(40, 400), alpha=.5, palette="muted",
height=6, data=mpg)Pour l’utiliser :
pip install seabornimport seaborn as snsPlotly – Librairies Data Sciences
Plotly est une librairie plus avancée que matplotlib pour la visualisation de données.
Les développeurs de la librairie revendiquent pouvoir faire des « publication-quality graphs », des graphiques de qualité professionnelle notamment pour les publications scientifiques.
Personnellement, j’aime le fait d’avoir des graphes interactifs avec Plotly dans lesquels on peut zoomer et naviguer facilement. Mais pour des graphes simples d’analyse, tu peux rester sur Matplotlib.
Pour l’utiliser :
pip install plotlyimport plotly.express as pxStatsmodels – Librairies Data Sciences
Statsmodels est une librairie Python permettant de faire des statistiques, des estimations et de la Data Exploration.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Tu as à disposition plusieurs modèles permettant de mieux comprendre tes données. Ainsi tu peux faire de la régression linéaire, de l’analyse de séries temporelles ou encore implémenter des Modèles Additifs Généralisés (MAG).
Pour l’utiliser :
pip install statsmodelsimport statsmodels.api as smScikit-learn – Librairies Data Sciences
Scikit-learn est LA bibliothèque la plus utilisées en Data Science pour faire du Machine Learning.
Elle vous permet de faire de l’apprentissage automatique de manière simple en vous permettant d’utiliser des algorithmes ready-to-use !
Cela en fait une base essentielle pour faire de la Data Science mais aussi une bonne porte d’entrée au Machine Learning.
Pour l’utiliser :
pip install scikit-learnimport scikit-learn as sklearnNLTK – Librairies Data Sciences
NLTK est le leader pour faire du Natural Language Processing (traitement des données textes).
Cette librairie propose des fonctions pour une grande variété d’opération :
- tokenization
- lemmatization
- stemmatization
- détection des entités et des noms propres
- suppression de stopwords
- analyse de sentiments (et leur intensité)
La liste est trop longue pour être exhaustif mais tu peux voir nos autres articles de la catégorie NLP si le sujet t’intéresse !
Pour l’utiliser :
pip install nltkimport nltkGensim – Librairies Data Sciences
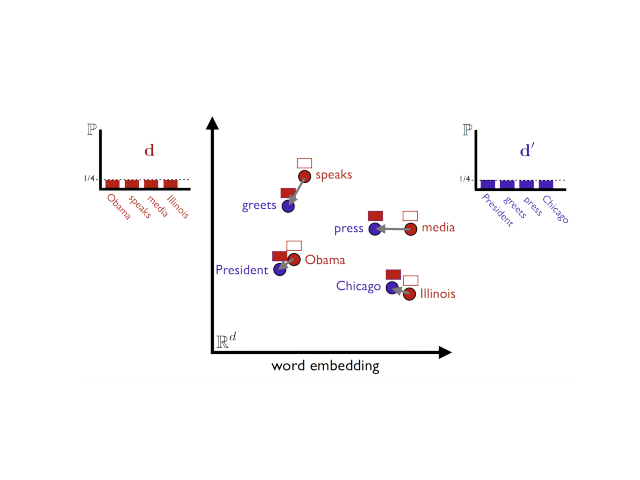
Gensim est utilisé pour faire une tâche bien précise de NLP : la représentation sous forme vectorielle.
Effectivement avec Gensim tu peux représenter du texte sous forme de vecteur. Et ça marche pour n’importe quel type de texte, que ce soit un document scientifique, un bouquin ou un article de presse !
Une fois qu’un texte est représenté sous forme vectorielle, il y a tout un tas d’analyse sympa à faire. Par exemple, tu peux calculer la similarité entre deux textes, même s’ils n’on aucun mots en commun :
Pour l’utiliser :
pip install gensimimport gensimSpacy – Librairies Data Sciences
Spacy est la dernière librairie NLP de ce top.
Elle partage la plupart des fonctionnalités de NLTK mais ici, la librairie se spécialise dans les applications en production.
On utilisera Spacy non pas pour de l’analyse pure en Python mais plutôt pour intégrer des outils d’analyse de texte dans des web app.
À noter que Spacy est particulièrement efficace dans la compréhension de texte long et détaillé.
Pour l’utiliser :
pip install spacyimport spacyBeautifulSoup – Librairies Data Sciences
BeautifulSoup est une librairie pour extraire des données de fichiers HTML.
Dis plus simplement, BeautifulSoup permet de récupérer des données d’autres sites web. Cette technique est appelé le Web Scraping.
Cette librairie propose en plus de cela un moyen simple de naviguer à travers ce fichier HTML. Par exemple pour afficher les titres, on utilisera fichier.title.
Et pour ceux ayant un peu moins de prise avec HTML, une fonction est proposé pour converter le HTML en texte. Idéal si tu veux lui appliquer du NLP !
Pour l’utiliser :
pip install beautifulsoup4from bs4 import BeautifulSoupNetworkX – Librairies Data Sciences
NetworkX est une librairie de niche. Seulement une partie des Data Scientist en auront besoin.
C’est une libraire qui offre une classe pour manipuler des Graphs et tous types de fonctions associées à ces objets.
Les Graphs sont des objets particulièrement utile pour représenter des relations entre des individus (personnes, entreprises, …).
Attention ici on ne parle pas de graphique mais bien de Graph.
Pour l’utiliser :
pip install networkximport networkx as nxLa Data Science est une base essentielle pour créer des algorithmes de Machine Learning.
Mais aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



