

Dans cet article, nous allons explorer une des tâches que l’on peut accomplir en Machine Learning : la classification multi-classes.
Lors d’un projet de Machine Learning, le praticien doit entraîner un algorithme à résoudre une tâche à partir d’un ensemble de données.
Cet ensemble peut contenir des données sous de multiples formes : numériques, textuelles, visuelles, etc. Néanmoins, l’ensemble appartiendra exclusivement à l’une de ces deux catégories :
- ensemble de données étiquetées
- ensemble de données non-étiquetées
Dans les lignes qui suivent, tu va explorer le concept de données étiquetées ainsi que celui de classes. Grâce à ces connaissances, nous pourrons aborder la classification multi-classes.
Remarque : Ici, j’utiliserai le terme « Machine Learning » pour mentionner à la fois le Machine Learning traditionnel et le Deep Learning. Ainsi, ce que tu apprendras dans cet article s’applique aux deux domaines.
Données Étiquetées
Label
Un ensemble de données étiquetées est un ensemble de données dans lequel chaque élément possède un label.
Un label est une valeur spécifique associée à un élément d’un ensemble de données.
Dit autrement, les éléments d’un ensemble de données étiquetées possèdent tous des étiquettes, appelées « labels ».
Les labels ne doivent pas être confondus avec les caractéristiques des éléments (en anglais « features »). En effet, même si dans certains cas, le label peut-être un attribut d’un élément, sa fonction est différente d’une caractéristique.
Le label a pour fonction de guider l’algorithme de Machine Learning durant son entraînement. Ce label indique la réponse ou la sortie attendue pour un élément dans le cadre d’une tâche.
À l’inverse, une caractéristique a pour but de définir un élément. Grâce aux caractéristiques d’un élément, l’algorithme de Machine Learning peut prédire un label correspondant.
Ainsi, dans un ensemble de données non-étiquetées, les éléments peuvent posséder une ou plusieurs caractéristiques mais n’auront pas de label. Tandis que dans un ensemble de données étiquetées, les éléments posséderont à la fois des caractéristiques et un ou plusieurs labels.
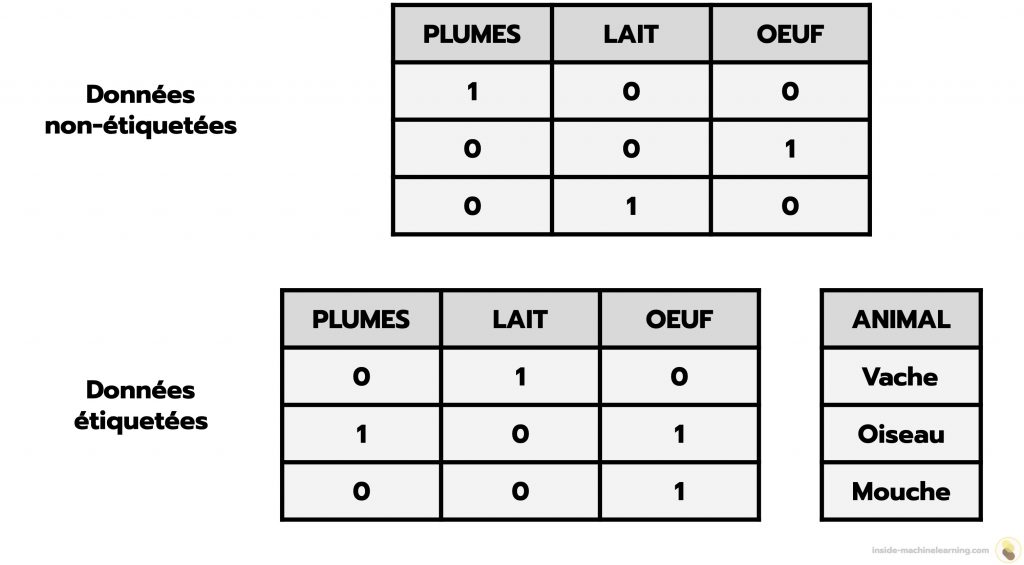
1 pour « possède la caractéristique », 0 sinonRemarque : Les données étiquetées peuvent également être appelées « données annotées » ou « données labellisées ».
Le label est donc une valeur associée à un élément. Le but dans un projet de Machine Learning avec des données étiquetées est d’entraîner un algorithme capable de prédire correctement ce label.
Deux types de labels existent :
- les labels discrets
- les labels continus
Classe
Un label discret est une variable catégorique : le nombre de valeurs possibles pour ce label est dénombrable.
Ainsi, lorsqu’un algorithme de Machine Learning doit prédire un label discret, il n’a qu’un nombre limité de possibilités.
Par exemple, supposons que nous ayons un ensemble de données contenant des animaux, et que nous souhaitions prédire leur type d’alimentation : carnivore, herbivore, ou omnivore. Ici, le type d’alimentation est un label discret car il n’y a que trois valeurs possibles : carnivore, herbivore, et omnivore.
Cela contraste avec les labels continus qui ont un nombre infini de valeurs possibles.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Par exemple, imaginons que nous ayons un ensemble de données contenant les caractéristiques météorologiques de différentes villes, et que notre objectif soit de prédire la température future. Dans ce contexte, la température est considérée comme une variable continue, car elle peut prendre n’importe quelle valeur réelle, telle que 25,3°C ou 30,7°C.
Les labels discrets mettent donc a disposition un nombre limité d’options à attribuer à nos données. Ces options sont appelées des « classes ».
Une classe est un label discret attribué à un élément dans un ensemble de données étiquetées.
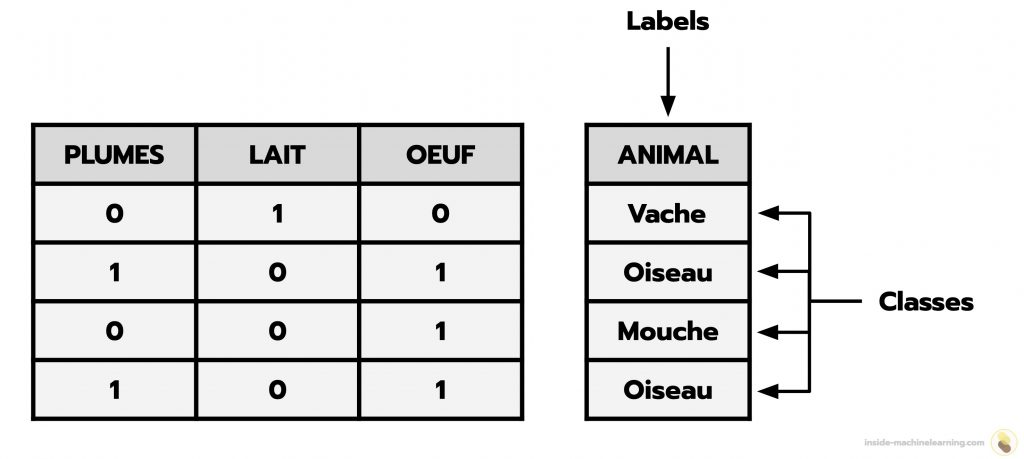
Lorsque des données sont étiquetées avec des classes, on dit qu’elles sont « classifiées ».
Ainsi les tâches de Machine Learning ayant pour but d’entraîner un algorithme à étiqueter de nouvelles données avec des classes sont appelées des tâches de classification.
En Machine Learning, il existe deux types de classification :
- la classification binaire – sur laquelle tu trouveras un article ici
- la classification multi-classes
Classification Multi-Classes
La classification multi-classes est une tâche de Machine Learning dans laquelle le praticien doit classifier des données d’entrées entre plus de deux classes.
Ainsi, dans une classification multi-classes, le nombre de classes possible pour un label est supérieur à deux.
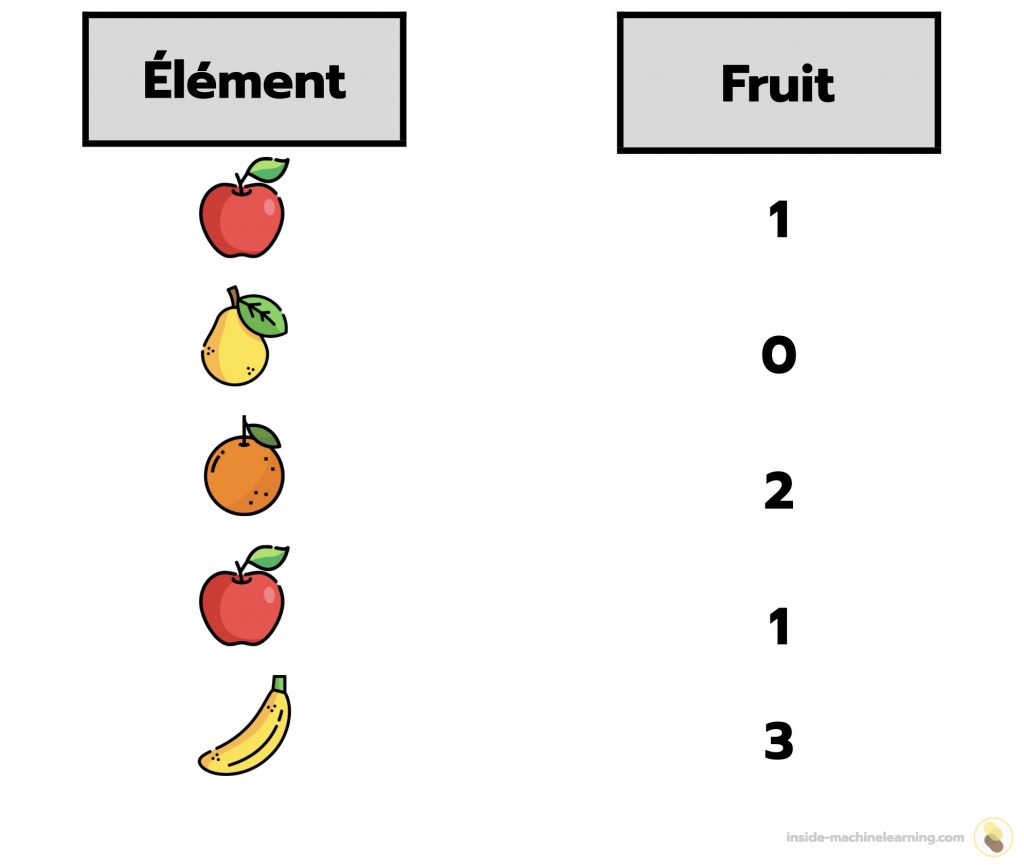
Par exemple, considérons un système de reconnaissance de fruits à partir d’images. Les classes possibles pour le label seraient les différents types de fruits tels que pomme, orange, banane et poire. Il y a plus de deux classes dans cette tâche, la classification est donc multi-classes.
Dans une classification multi-classes, les classes sont généralement encodées sous forme de chiffres en commençant par zéro.
Même si la classification binaire et la classification multi-classes ont toutes deux pour objet la classification d’éléments entre plusieurs classes, il est important de faire la distinction entre ces deux tâches. En effet, le type de classification auquel fait face le praticien affectera les paramètres de construction et d’évaluation utilisés pour entraîner un algorithme.
Ainsi, lors d’une classification multi-classes, le praticien emploiera une approche différente de résolution que pour une classification binaire.
Si un ensemble de données est étiqueté avec plus de deux classes, alors on parle d’une classification multi-classes.
Cette tâche appartient à une approche de Machine Learning : l’apprentissage supervisé. L’apprentissage est dit « supervisé » car le label guide l’algorithme de Machine Learning dans son apprentissage.
Il permet à l’algorithme de connaître le résultat attendu pour un élément spécifique.
D’autres tâches d’apprentissage supervisé existent. Tu pourras les étudier en naviguant sur mon blog.
Mais tu peux également accéder à mes bonus privés dans lesquels, je résume l’ensemble de mes articles sur le sujet de l’apprentissage supervisé.
Tu trouveras la totalité des points clés et schémas pour maitriser les concepts du domaine :
- classification binaire
- classification multi-classes
- régression
Pour y accéder clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



