

Dans cet article nous allons voir une des techniques de Regularization les plus puissantes en Deep Learning : la Batch Normalization.
Cette méthode de Regularization a été théorisé dans le papier de recherche Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift datant de 2015.
Il existe de nombreuses méthodes de Regularization comme la L2 Regularization présenté dans cet article.
Ici, nous allons nous concentrer sur la Batch Normalization qui est une technique essentielle à connaître quand on fait du Deep Learning !
La Batch Normalization
Qu’est-ce que c’est ?
Ou plutôt qu’est-ce que la normalisation ?
La normalisation c’est le fait de modifier les données d’entrée d’un réseau de neurones de telle sorte que la moyenne soit nulle et l’écart-type égale à un, comme détaillé ici.
En fait cela permet d’avoir des données plus stables car appartenant à une même échelle. Par conséquent le réseau de neurones a plus de facilité à s’entraîner.
La normalisation c’est donc le fait de formater ses données d’entrée pour faciliter le processus de Machine Learning.
La Batch Normalization, elle, survient dans le contexte du Deep Learning où l’on a un empilement successif de couches et de fonctions d’activation.
En fait, dans le Deep Learning, chaque résultat d’une couche est l’entrée de la couche suivante.
Vous me voyez venir…
De même que la normalisation en entrée facilite l’apprentissage, la normalisation après chaque couche (donc à l’entrée de chaque nouvelle couche) permet, elle aussi, un meilleur apprentissage.
Normaliser la sortie d’une couche, c’est ce qu’on appelle la Batch Normalization !
L’idée est faire de la normalisation une partie de la structure du modèle, comme afficher dans le schéma de Réseau de Neurones ci-dessous :
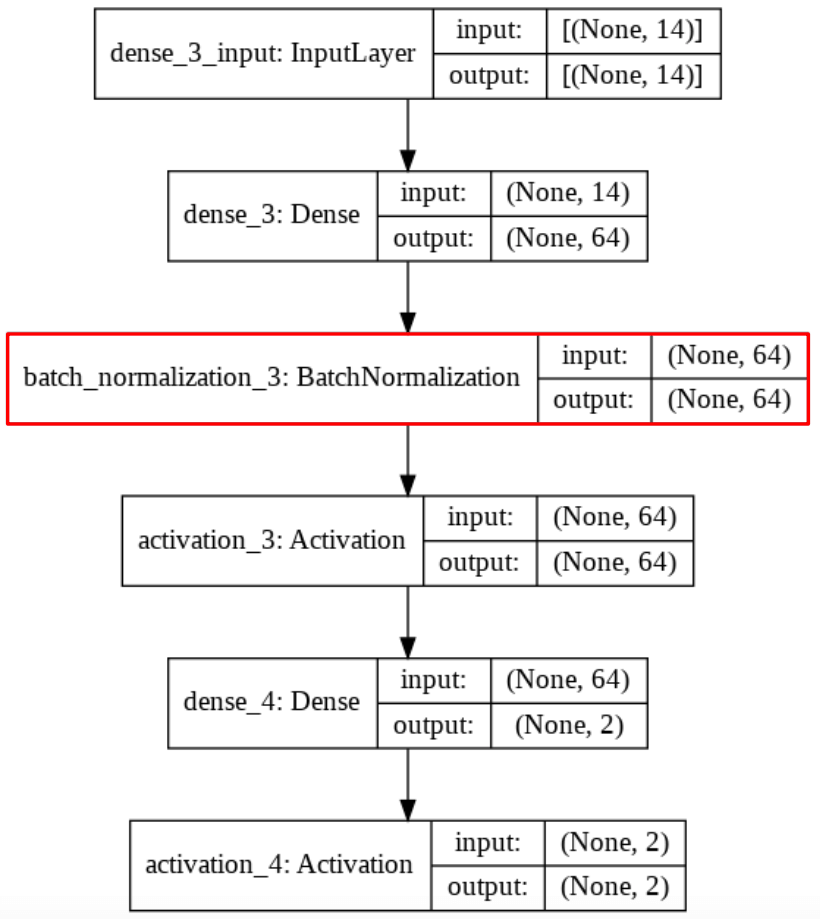
Pourquoi appelle-t-on cela « Batch » Normalization ?
La normalisation dont on parle actuellement ne s’effectue pas sur l’ensemble du jeux de données.
Effectivement lors de l’apprentissage, le jeu de données d’apprentissage est séparé en plusieurs lots (batch) de données.
C’est donc sur ces batch qu’est effectuée la normalisation à l’intérieur du modèle.
On retient donc le concept de Batch Normalization
Pourquoi l’utiliser ?
La Batch Normalization a plusieurs bénéfices important.
Le premier est la stabilisation du réseau de neurones. Effectivement pour chaque batch, le réseau doit s’adapter à une seule plage de données normalisées. La variance (standard deviation) étant égale à 1, on évite ce qu’on appelle le décalage de covariance (covariate shift).
Lorsque la variance entre des données à l’intérieur du modèle est stable, on dit que le réseau de neurones est stabilisé.
Cela nous permet d’utiliser un taux d’apprentissage (learning rate) plus élevé et donc d’accélérer la durée d’entraînement du modèle.
Pour rentrer un peu plus dans le détail, le taux d’apprentissage élevé implique habituellement l’explosion ou la disparition du gradient durant la backpropagation, ce qu’on veut absolument éviter !
Ici, avec la stabilisation du réseau de neurones, cette explosion/disparition est évitée et donc on peut utiliser un fort taux d’apprentissage.
Le deuxième bénéfice est que la Batch Normalization agit comme un Regularizer.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Effectivement lors de l’entraînement, toutes les données d’un batch partagent une même échelle de valeur. Les données du batch sont alors vue comme ayant un lien entre elles.
Cela permet au modèle d’avoir une vision d’ensemble du problème à résoudre et des données à traiter. En fait, cela permet au modèle de mieux généraliser et donc de réduire l’overfitting.
Dans certain cas, cela réduit voir anéantit le besoin d’utiliser le Dropout (une autre méthode de Regularization expliquée ici).
Apprentissage plus rapide, meilleur généralisation et en plus de ça, des résultats qui dépassent les précédents algorithmes les plus performants !
C’est ce qui fait de la Batch Normalization une technique de base à connaître en Deep Learning !
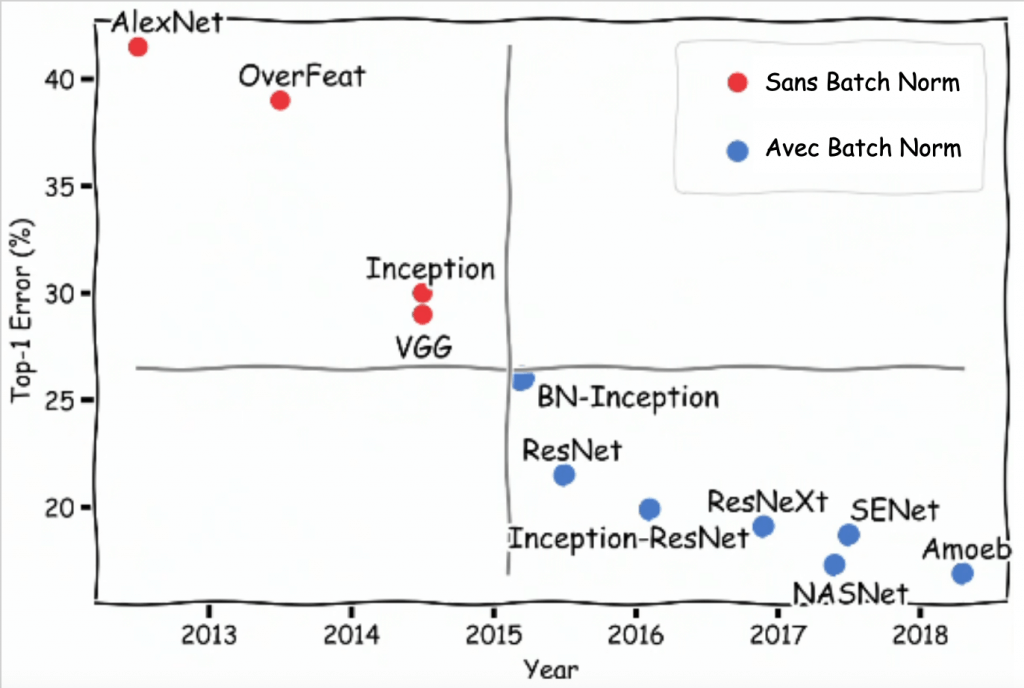
Effectivement, comme affiché sur le schéma ci-dessus, la Batch Normalization est utilisé partout dans les algorithmes actuels à la pointe de la performance.

Comment utiliser la Batch Normalization ?
Sur Keras & Tensorflow
Alors en pratique, comment utiliser la BatchNormalization ?
Sur Keras & Tensorflow, c’est bien simple :
tf.keras.layers.BatchNormalization()D’après les auteurs du papier de recherche de la Batch Norm, elle s’utilise entre la sortie d’une couche et l’utilisation de la fonction d’activation, comme ci-après :
model = Sequential()
model.add(Dense(64, input_dim=14))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(BatchNormalization())
model.add(Activation('softmax'))C’est donc une sorte d’amélioration de la couche de base avant l’application de la fonction d’activation.
Sur PyTorch
Avec la librairie PyTorch, il faut préciser la taille de la matrice à normaliser, ici num_features :
torch.nn.BatchNorm2d(num_features)Concrètement, voici un exemple de réseau de neurones en Pytorch utilisant la Batch Normalization :
class NetBatchNorm(nn.Module):
def __init__(self, n_chans1=32):
super().__init__()
self.n_chans1 = n_chans1
self.conv1 = nn.Conv2d(3, n_chans1, kernel_size=3, padding=1)
self.conv1_batchnorm = nn.BatchNorm2d(num_features=n_chans1)
self.conv2 = nn.Conv2d(n_chans1, n_chans1 // 2, kernel_size=3, padding=1)
self.conv2_batchnorm = nn.BatchNorm2d(num_features=n_chans1 // 2)
self.fc1 = nn.Linear(8 * 8 * n_chans1 // 2, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = self.conv1_batchnorm(self.conv1(x))
out = F.max_pool2d(torch.tanh(out), 2)
out = self.conv2_batchnorm(self.conv2(out))
out = F.max_pool2d(torch.tanh(out), 2)
out = out.view(-1, 8 * 8 * self.n_chans1 // 2)
out = torch.tanh(self.fc1(out))
out = self.fc2(out) À savoir : il y a actuellement un débat sur le fait d’appliquer la Batch Norm avant la fonction d’activation, après, voire même avant ET après. Il semblerait qu’il n’y ait pas vraiment de bonne pratique. Je reviendrai donc sur l’adage du Deep Learning : testez !
Testez et vous saurez quand utiliser la Batch Norm. Certains modèles nécessiteront l’utilisation avant la fonction d’activation, d’autre après et encore d’autres seront plus performant avec une Batch Norm avant et après.
C’est tout pour cet article ! Gardez en tête que la Batch Normalization est souvent utilisée en association avec la L2 Regularization et le Dropout, d’autres méthodes de Regularization !
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



