

Dans cette suite d’article, nous allons aborder des concepts fondamentaux du Deep Learning: loss function, et gradient.
Pour comprendre ces concepts, il faut préalablement comprendre la notion de réseau de neurones.
Si vous ne l’avez pas encore vu, je vous propose de lire cet article sur l’explication des réseaux de neurones que nous avons rédigé.
Si vous connaissez cette notion vous pourrez rapidement comprendre les concepts que l’on va abordé dans cette premiere partie, notamment le concept de loss function.
Qu’est-ce que « optimiser un modèle de Deep Learning » ? – Loss Functuon
Nous allons reprendre la notion de fonction mathématique représentant les neurones, comme détaillé ici.
Les neurones sont des fonctions mathématiques permettant de transformer des données brutes en données interprétable par l’homme.
La donnée se transmet entre chaque couche du modèle grâce aux neurones.
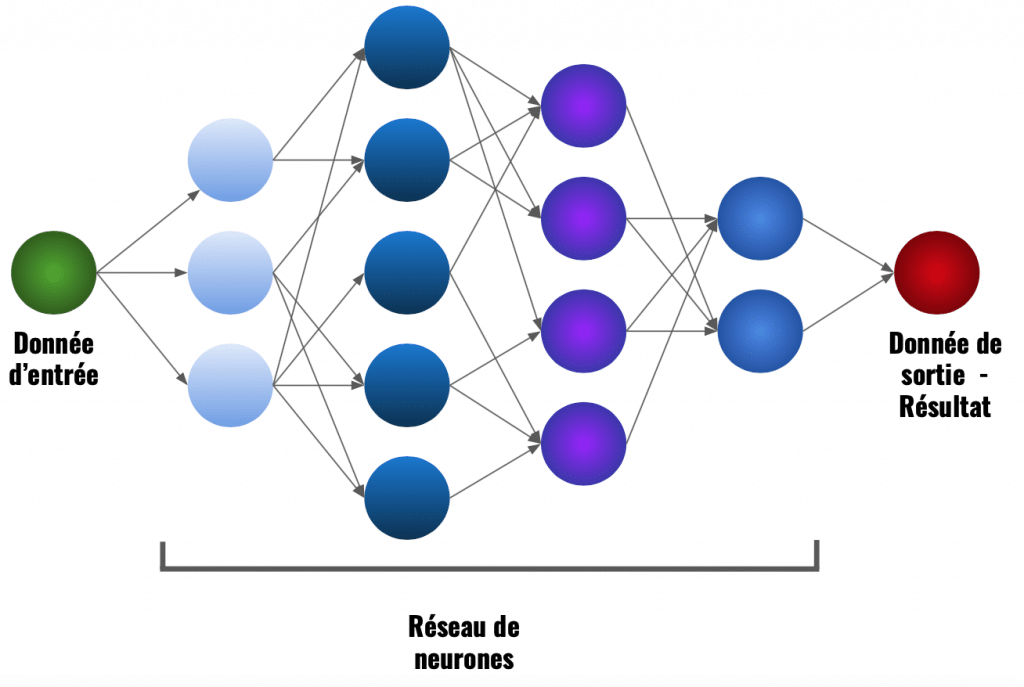
Chacun des neurones à une influence sur le résultat final. Modifier un seul neurone et le résultat en est modifié.
Optimiser un modèle de Deep Learning c’est donc optimiser chacun des résultats de ses neurones.
Il est inutile d’optimiser un modèle qui nous donne déjà le bon résultat. C’est pourquoi avant d’optimiser un modèle, il faut d’abord déterminer si ce modèle doit être optimiser.
Pour cela, on calcule la différence entre le résultat prédit et le résultat attendu.
difference(resultat_predit, resultat_attendu)En d’autres termes, on dit que l’on calcule la perte (on parle aussi de taux d’erreur)… d’où le nom de loss function ou fonction de perte !
Plus cette perte est minime plus le modèle est performant.
Le but de l’optimisation est donc de minimiser le résultat de la loss function.
Minimiser la loss function
Pour minimiser la loss function il faut modifier ses données d’entrées.
On rappelle que la loss function compare le résultat prédit et le résultat attendu (ses données d’entrées).
loss_function = difference(resultat_predit, resultat_attendu)La donnée « résultat attendu » étant un résultat fixe et immuable, c’est sur le résultat prédit que nous allons effectuer une modification.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Rappel:
resultat_predit = fonction_neurone(resultat_du_neurone_precedent, poids)Le résultat prédit est obtenu grâce à la fonction du neurone qui s’applique à la fois sur :
- le résultat du neurone précédent
- le poids associé au neurone actuel
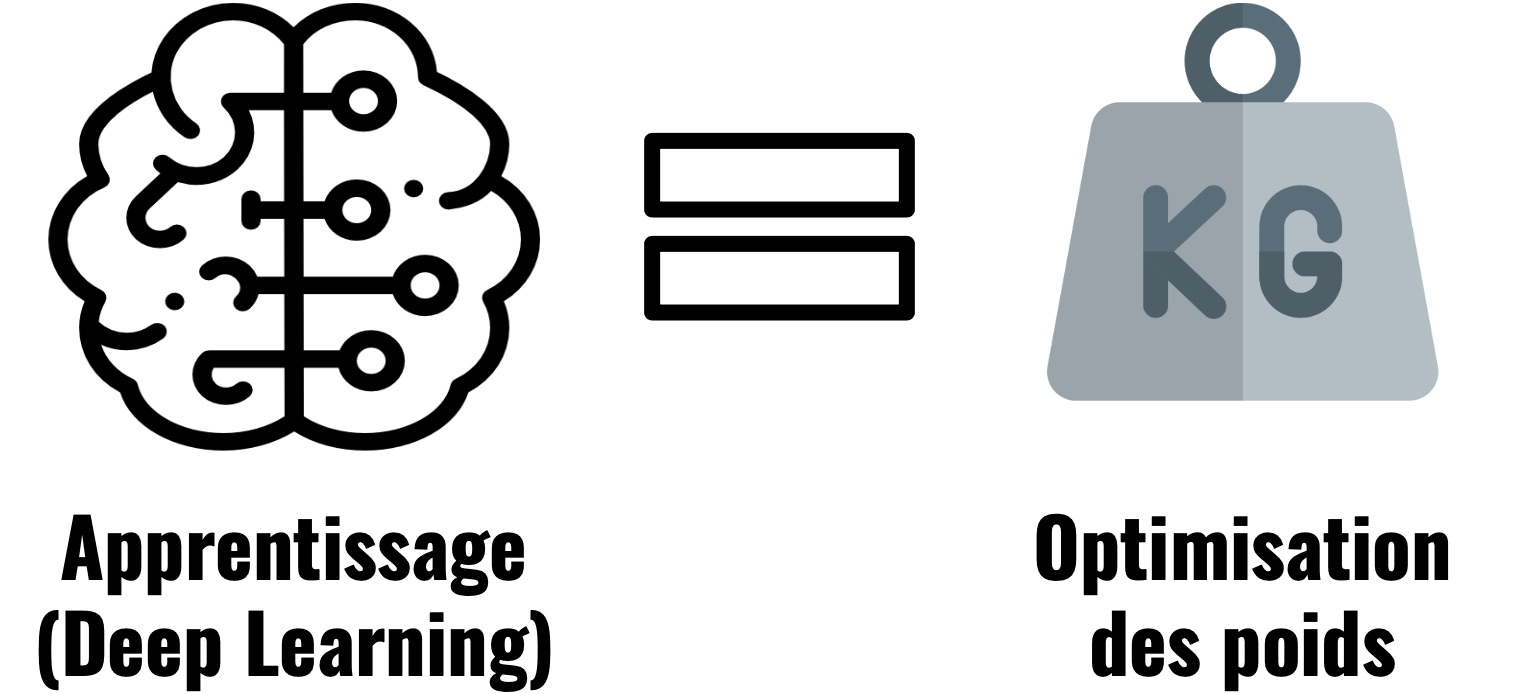
Un neurone n’a aucune influence sur le résultat du neurone précédent, pour améliorer son résultat on doit donc modifier son poids.
Conclusion: Optimiser un modèle de Deep Learning c’est optimiser les poids de ses neurones.
Pour comprendre avec une autre approche, imaginons un joueur de baseball qui doit renvoyer une balle avec sa batte :
- Le joueur de baseball représente le neurone
- La balle représente la donnée d’entrée
- Le geste du joueur avec sa batte représente le poids associé au neurone
- Le résultat de son tir représente le résultat de sa prédiction
Le joueur n’a pas d’emprise sur la balle qu’il reçoit. Pour améliorer son tir il n’a d’autre choix que d’améliorer son geste lorsqu’il frappe la balle.
Eh bien, pour le neurone, c’est la même idée ! Le neurone n’a pas d’emprise sur la donnée qu’il reçoit sa seule possibilité pour améliorer sa prédiction est d’améliorer son poids.

Arrivé ici vous devriez avoir compris comment notre modèle évalue ses capacités, ses poids !
Dans la deuxième partie de cette suite d’article, nous allons voir comment optimiser ces poids. Si tu veux y accède clique ici.
Maintenant, il est également possible que tu souhaites directement passer au niveau supérieur et apprendre le Deep Learning de manière pratique.
Si c’est le cas, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Pour y accéder, clique ici :
sources
- Photo by Anastase Maragos on Unsplash
- Photo by Engin Akyurt on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



