

Dans cet article, je vais te présenter ma vision du Deep Learning pour t’aider à comprendre ce domaine bien particulier.
Précédemment, je t’expliquais ce qu’était le Machine Learning. Aujourd’hui, nous allons approfondir une des branches de ce domaine: le Deep Learning.
Le Deep Learning, ou apprentissage profond, est une technique de Machine Learning permettant la résolution de tâches complexes, nécessitant une énorme quantité de données (big data).
Le Deep Learning utilise notamment ce qu’on appelle des réseau de neurones qui représentent la structure du modèle.
Là où, avec les algorithmes classiques de Machine Learning, on faisait seulement varier les paramètres de base du modèle, avec le Deep Learning, on peut modifier directement la structure du modèle.

Le modèle – Comprendre le Deep Learning
Dans cet article, nous allons étudier la structure d’un modèle de Deep Learning par différentes approches. Chacune de ces approches correspond à une vision du Deep Learning, de la plus simple à la plus compliqué.
Pour bien comprendre ces approches il faut comprendre seulement une notion: celle de fonction mathématique.
Une fonction mathématique permet d’appliquer une suite de calcul sur une variable pour obtenir un résultat.
Exemple: f est une fonction, f(x) = 3 + x quand x = 3, f(x) = 6.
Oui, c’est une notion basique en mathématique, mais elle suffit pour comprendre le Deep Learning.
Je vous propose donc une première vision, la plus basique, qui consiste à voir un modèle comme une fonction. On injecte une donnée d’entrée (x) à notre modèle (f) et on obtient un résultat.

C’est une première approche utile pour expliquer ce qu’est le Deep Learning en surface. Mais si vous êtes ici, c’est que vous voulez en savoir plus j’en suis sûr 😉
Les Couches Cachées – Comprendre le Deep Learning
Il y a une raison pour laquelle le Deep Learning, apprentissage profond, porte son nom. Le Deep Learning fait plus qu’appliquer une simple fonction mathématique.
Mais ce processus qu’il applique n’est pas visible par l’utilisateur. Il est « caché » à l’intérieur du modèle, en profondeur.
Ce processus, cette apprentissage est dit « profond ».
Ceci étant dit, regardons ce qui se passe à l’intérieur du modèle.
Un modèle est constitué de plusieurs couches à travers lesquels va passer notre donnée d’entrée.
Nous allons garder notre exemple avec la fonction f.
Dans cette approche, chaque couche correspond à une fonction.
Lorsque le modèle sera appliquer à notre donnée, cette donnée va passer à travers chacune des couches qui composent le modèle.
Chacune des couches étant une fonction, la donnée va changer de valeur après être passée dans une couche. Et c’est sur cette nouvelle valeur que la couche suivante va appliquer son calcul
Un exemple: On commence avec x = 3
- Premiere couche: f(x) = 3 + x donc f(x) = 6
- Deuxième couche: f(x) = 3 + x donc f(x) = 9
- Troisième couche: f(x) = 3 + x donc f(x) = 12
- Quatrième couche: f(x) = 3 + x donc f(x) = 15
Pour finalement obtenir un résultat final qui sera la sortie de notre modèle. Dans notre exemple, le résultat final est 15.
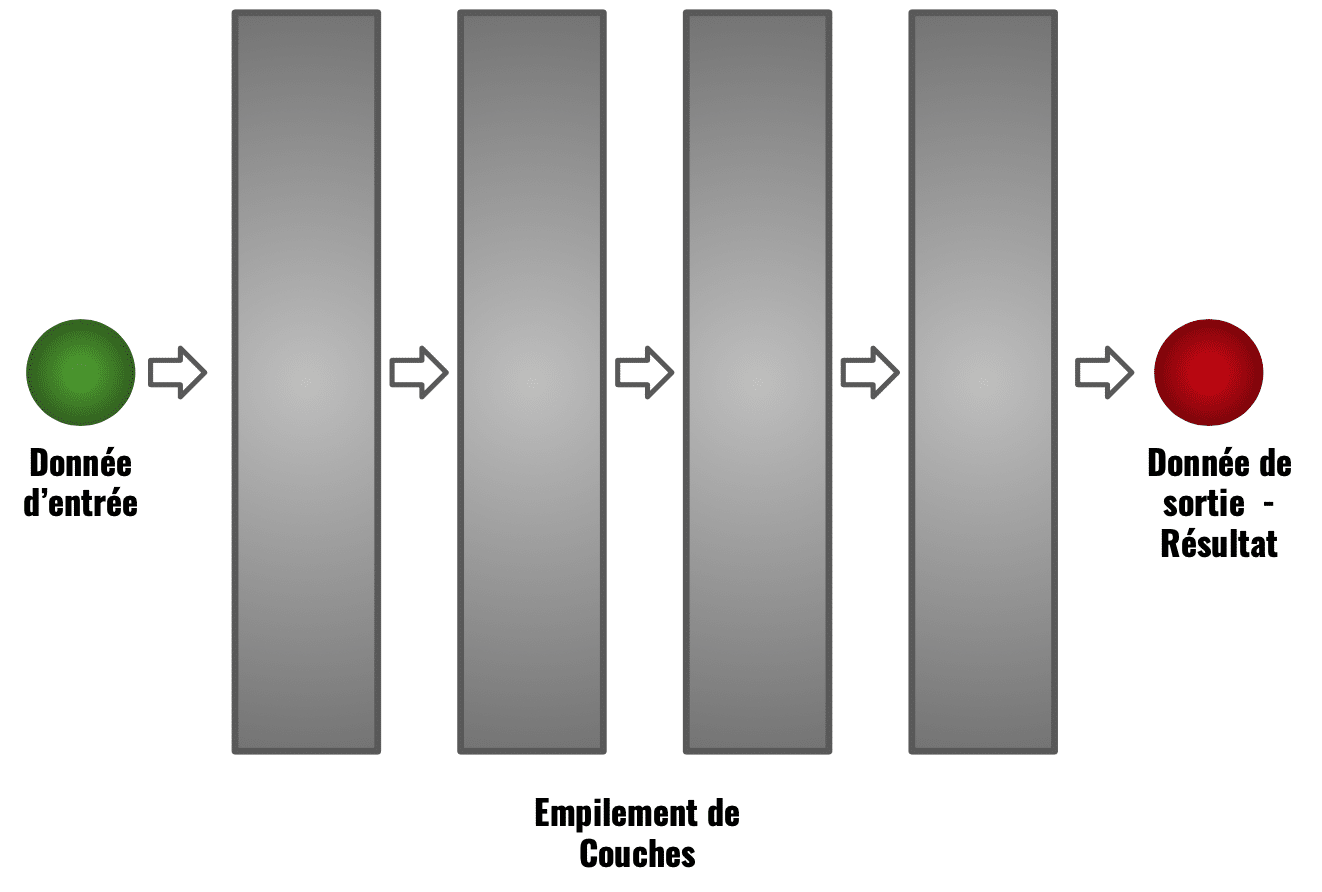
En fait, dans un modèle de Deep Learning, chacune des couches représentent une fonction différente.
Dans notre exemple, on n’aurait donc non pas quatre fois l’application de la fonction f(x) = 3 + x mais plutôt l’application de quatre fonction différentes f1, f2 , f3, f4. Mais je pense que l’idée est assez claire.
Si chaque couleur représente une fonction alors schématiquement, cela donnerai:
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.

Avec ces explications, vous devriez avoir compris les bases du Deep Learning mais.. encore une fois, cette vision est une approche schématique du processus de Deep Learning.
En réalité les modèles sont plus complexes… mais si vous avez bien compris les bases vous devriez pouvoir suivre le reste ! 🙂
Les Réseaux de Neurones – Comprendre le Deep Learning
Maintenant que vous avez compris le principe de couches, nous allons pouvoir aborder le principe de neurones.
On a vu que les modèles de Deep Learning étaient composés de « couches cachés » qui peuvent être assimilées à des fonctions.
Eh bien.. ces même couches sont composés de ce qu’on appelle des neurones ou neurones artificielles.
On peut donc schématiser cela comme suit:
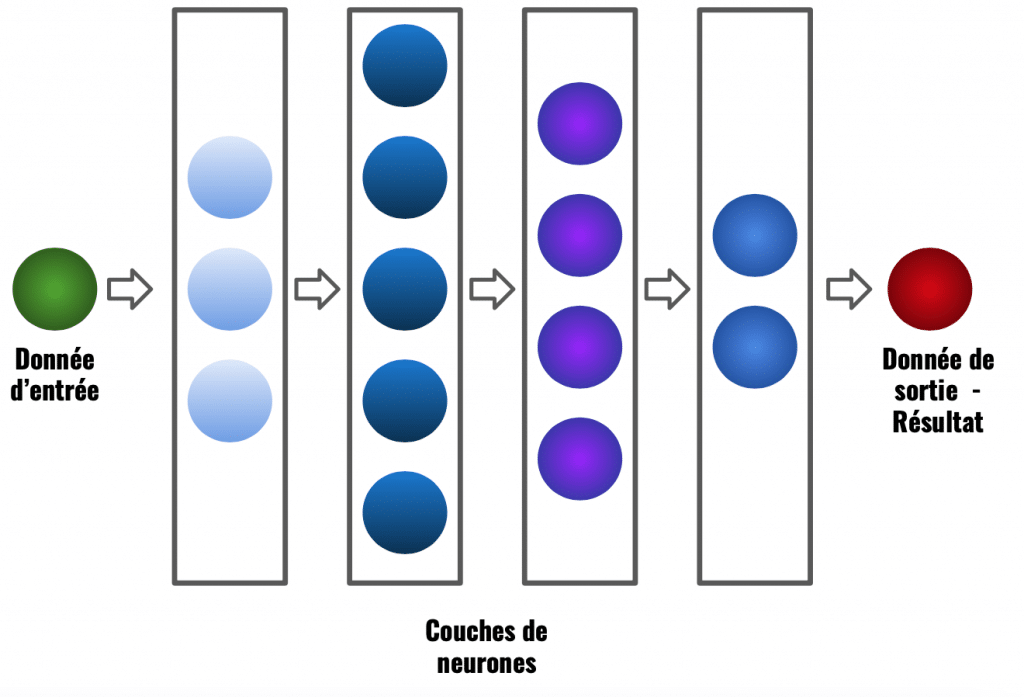
Chaque couches possèdent donc plusieurs neurones mais à quoi servent ces neurones ?
Allez ! Encore un dernier de niveau de complexité.
Devinez quoi… Ces neurones sont en fait… des fonctions !
Comme les couches, les neurones sont connectés aux neurones précédents, la différence c’est que sur une même couche, il peut y avoir plusieurs neurones. Plusieurs neurones donc plusieurs connections.
Ces connections sont choisis par le développeur, il peut choisir de le relier à un seul neurone précédent ou a une multitude.
Voyez plutôt ce schéma et regarder les connections. Certains neurones sont connecté à tous les précédentes et d’autres non.
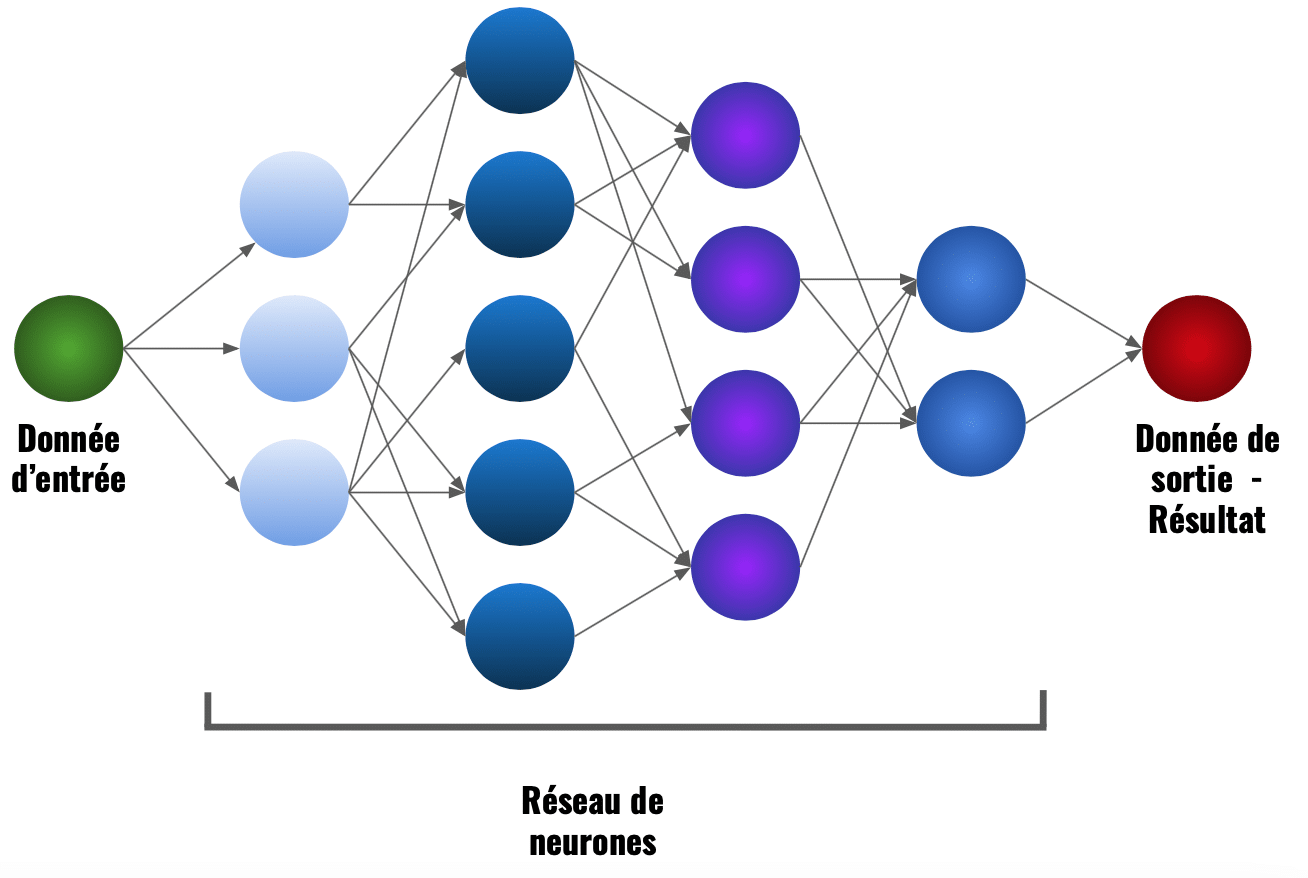
Pour simplifier: si l’on regarde la donnée d’entrée comme un point de départ et la donnée de sortie comme un point d’arrivée, on peut voir le réseau de neurone comme une combinaison des chemins que la donnée d’entrée emprunte pour arriver au résultat.
Cette fois le schéma représente exactement ce qui se passe dans un modèle. Si vous avez compris ça, vous avez compris le principe du Deep Learning !
Pour aller plus loin – Les poids
Pour aller plus loin dans la notion de structure d’un modèle de Deep Learning il me semble intéressant d’étudier ce qu’il se passe au niveau d’un neurone.
On a bien sûr dit que le neurone est une fonction mathématique mais nous ne sommes pas rentré dans les détails.
On a vu que chaque neurone prend le résultat des neurones précédents en entrée de sa fonction.
En plus, il y associe un poids propre à lui-même lors de l’application de la fonction.
Pour reprendre notre exemple… avec:
- Un neurone connecté à un seul autre neurone précédent
- Le résultat du neurone précédent: x
- Le poids associé: p
- La fonction du neurone actuel: f
On applique la fonction du neurone actuel ainsi: f(x*p)
À quoi servent ces poids ? Avant de répondre, il faut comprendre la notion d’apprentissage.
Les poids changent en fonction de l’apprentissage de notre modèle. Plus le modèle sera optimal plus les poids seront eux aussi optimaux.
Les poids contrôlent le signal (ou la force de la connexion) entre deux neurones. En d’autres termes, le poids décide de l’influence que l’entrée aura sur la sortie.
Si le modèle a appris qu’un neurone a plus d’importance qu’un autre, le poids associé à ce neurone sera plus important.
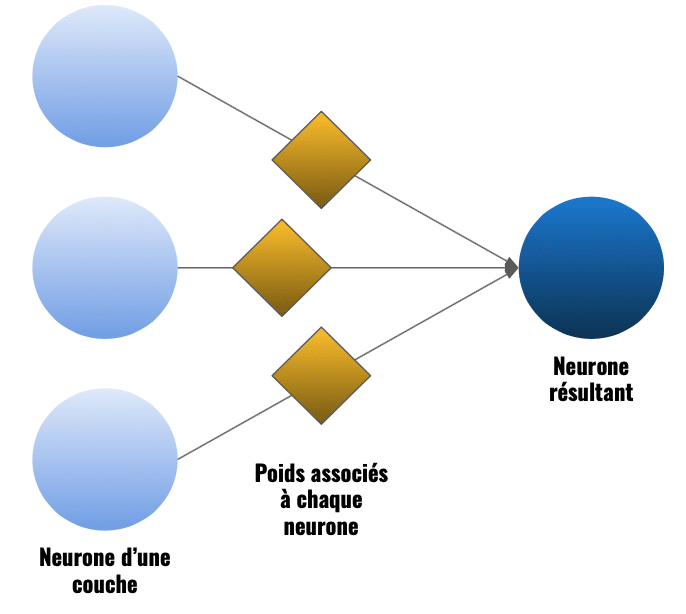
Ensuite, le neurone applique sa fonction, qu’on appelle fonction d’activation, et le résultat est obtenue.
La structure d’un modèle de Deep Learning n’est évidemment pas la seule chose à savoir dans ce domaine.
Il y a des notions plus complexes à étudier comme:
- Le choix de la disposition des neurones
- Leur fonction associée
- Le nombre de couches choisies
Si tu veux approfondir tes connaissances sur le sujet, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



