

Le Machine Learning est un domaine majeur de l’intelligence artificielle. Les Data Scientist et les ingénieurs l’utilisent pour résoudre des problèmes, analyser des images ou encore prédire des événements.
Aujourd’hui le Machine Learning est présent dans quasiment tous les domaines qui touchent au numériques, aussi bien dans les logiciels de spécialistes en IA que dans vos téléphones.
Il permet notamment de faire de la reconnaissance faciale, des recommandation de films ou séries Netflix, de rendre des voitures autonome et bien d’autres…

Entraîner son modèle de Machine Learning
Pour commencer, nous allons voir de quoi nous avons besoin pour faire du Machine Learning. Il nous faut plusieurs choses:
- Un logiciel de programmation
- Un modèle à entraîner
- Des données à exploiter
Le logiciel de programmation, la base. Il va nous permettre d’importer nos données, de programmer notre algorithme, de l’entraîner et de l’utiliser. C’est donc sur le logiciel que tout se passe.
Ensuite, il nous faut un modèle à entraîner. Mais.. avant ça.. c’est quoi un modèle ?
Un modèle c’est un algorithme qui a plusieurs fonctions, plusieurs rôles. Il a pour objectif principal d’apprendre puis de résoudre des problèmes.
On peut le voir comme le coeur du Machine Learning. Ça peut faire peur dit comme ça, mais rassurez-vous, la majorité des modèles que l’on utilise pour faire du Machine Learning sont déjà codés et prêt à être utilisés.
Pour les plus aventureux il est tout de même possible de coder des modèles de Machine Learning. Pour les débutants, mon conseil est de commencer avec des modèles pré-faits et de développer un modèle plus tard, lorsque les bases sont comprises.
Enfin, il nous faut des données à exploiter.
Avant de résoudre des problèmes, la machine a besoin d’apprendre, de s’entraîner. C’est avec des données que la Machine va apprendre (d’où Machine Learning). Ces données sont d’ailleurs appelés « données d’entraînement » ou encore train set, on verra plus loin quels sont les autres types de données.
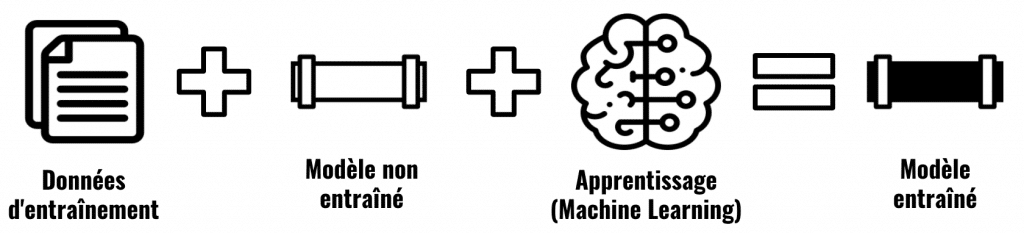
Résoudre des problèmes, faire des prédiction
Une fois que tout cela est réunis, on peut enfin passer à la pratique et voir ce que vaut notre modèle.
Là encore, il nous faut des données. Cette fois ces données (différentes des précédentes) seront appelées des données de test, test set. Comme vous l’aurez compris, ces données servent à tester notre modèle, elles permettent de mesurer sa fiabilité.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Une fois que notre modèle nous convient on peut l’utiliser ! On prend cette fois nos données à prédire, prediction set, et on exécute l’algorithme.
Selon la fiabilité du modèle, sa probabilité d’avoir un bon résultat sera plus ou moins élevée.
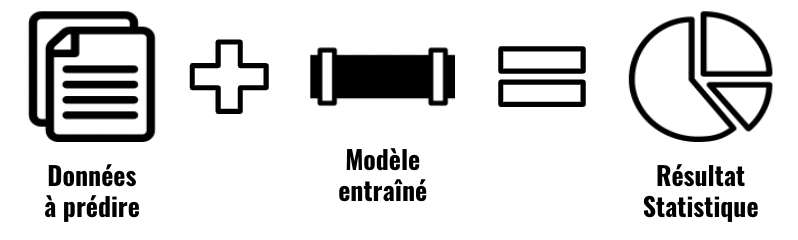
Un exemple pour mieux comprendre
Prenons un exemple pour être plus concret !
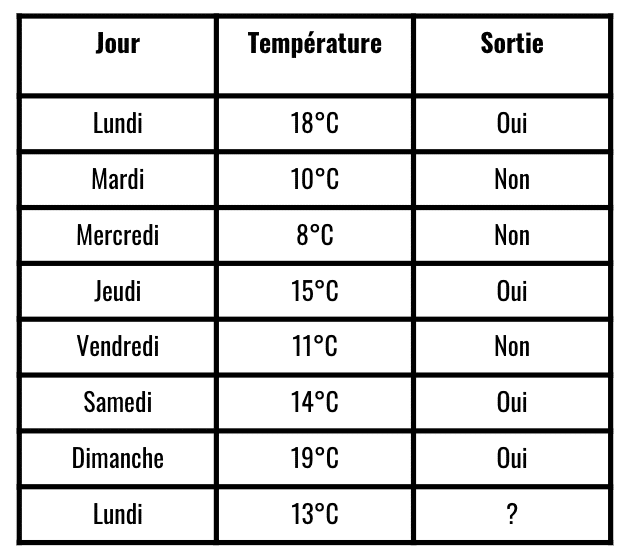
Mr Dupont sort de chez lui selon la température extérieur.
Notre jeu de données est composé de:
- La température de chaque jour de la semaine
- Si Mr Dupont est sortie ce jour là
Notre objectif est de prédire si Mr Dupont sortira lundi prochain
On entraîne donc notre modèle sur le premier jeu de données.
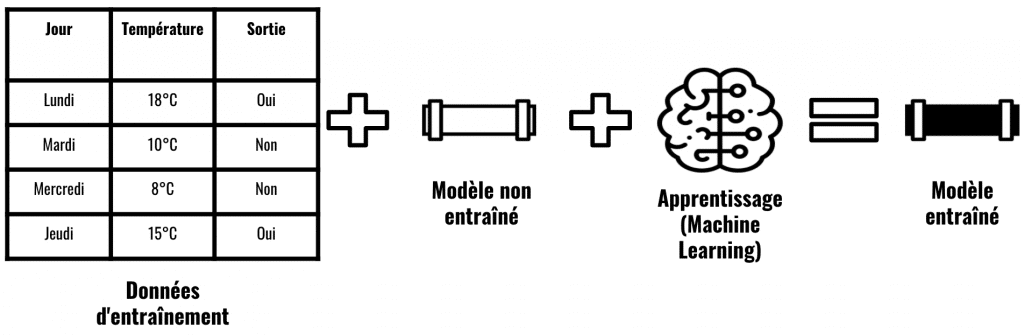
Ensuite on teste sa fiabilité sur le deuxième jeu de données.
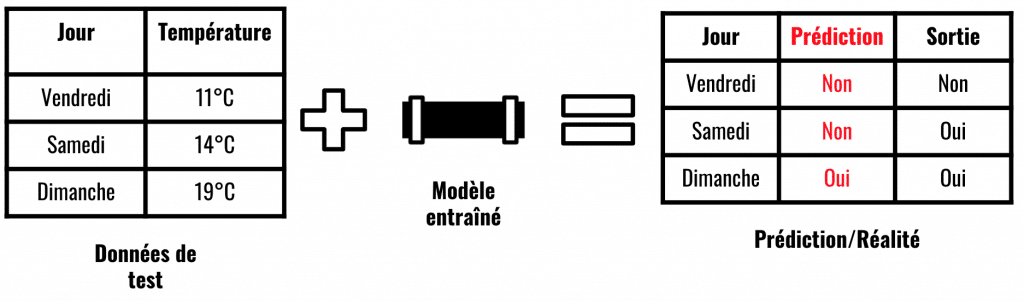
On voit ici que le test de nos données n’est pas fiable à 100%. Cette erreur pourtant ne signifie pas que notre modèle est bon pour la poubelle, au contraire !
Dans le domaine du Machine Learning il est impossible d’avoir un modèle fiable à 100%.. à moins d’une erreur. Car oui vous imaginez bien que, appliqué à des problèmes de la vie réelle il serait fou de pouvoir prédire le futur avec une fiabilité totale.
Dans cet optique, on mesure la précision de notre modèle.
Ici, on a prédit deux bon résultat(vendredi et dimanche). La fiabilité est donc de 2/3, 66%, c’est peu mais assez pour notre exemple.
On prend donc la partie du jeu de données que l’on veut prédire et on exécute notre modèle.

Vous avez remarqué ? Le modèle ne nous a pas retourné une seule réponse mais une statistique.
C’est parce que les modèles de Machine Learning ne prédisent pas l’avenir ! Ils font des calcul statistiques pour savoir qu’elle est l’évènement le plus probable. Car oui, le machine Learning c’est avant tout des probabilités.
Selon notre algorithme il y aurait 78% de chance que Mr Dupont ne sorte pas ce lundi. Ajoutons à cela que notre algorithme a une fiabilité de 66%(selon nos données de test). Alors ? Pensez-vous que Mr Dupont sortira de chez lui ce lundi ?
Et voilà ! Vous avez pu voir comment s’articule un algorithme de Machine Learning, comment il s’utilise et quel résultat il retourne.
Si vous avez des questions, n’hésitez pas à utiliser la section commentaire !
À bientôt sur Inside machine Learning !
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



