

Aujourd’hui, je vous propose de faire de l’EDA NLP: de l’Exploratory Data Analysis sur un dataset textuel : feedback-prize-effectiveness.
Dans un article précédent on voyait comment faire de l’EDA pour prévenir les catastrophes environnementales. Grâce à des données météorologiques chiffrées, nous avons analysé les causes des feux de forêts.
Ici je vous propose d’appliquer la même analyse sur des données textes grâce au dataset feedback-prize-effectiveness.
Ce dataset est tiré de la compétition Kaggle du même nom : Feedback Prize – Predicting Effective Arguments.
L’objectif principale de cette compétition est de créer un algorithme de Machine Learning capable de prédire l’efficacité d’un discours. Ici nous allons voir en détail l’Exploratory Data Analysis (EDA) qui nous permettra de comprendre notre dataset.
Data – EDA NLP
Première chose à faire, télécharger le dataset. Soit en vous inscrivant au concours Kaggle, soit en le téléchargeant sur ce Github.
Ensuite on peut l’ouvrir avec Pandas et afficher ses dimensions:
import pandas as pd
df = pd.read_csv("train.csv")
df.shapeSortie: (36765, 5)
Nous avons 36.765 lignes donc 36.765 discours pour 5 colonnes.
Voyons maintenant ce que ces colonnes représentent en affichant leur types:
df.dtypesJ’affiche ici le type des colonnes et leur description:
discourse_id– object – ID du discoursessay_id– object – ID de l’essai (un essai peut-être composé de plusieurs discours)discourse_text– object – Texte du discoursdiscourse_type– object – Type de discoursdiscourse_effectiveness– object – Effectivité du discours
2 colonnes ID, une colonne représentant le texte et 2 colonnes pour des Labels. Celui nous intéressant le plus étant discourse_effectiveness car c’est la cible à prédire.
Ensuite on peut afficher nos données :
df.head()
Maintenant qu’on a un bon aperçu du dataset, on peut commencer l’EDA.
Pour ça, on va reprendre les étapes classiques du processus:
- Comprendre notre Dataset avec l’Analyse Univariée
- Tracer des hypothèses avec l’Analyse Multivariée
Analyse Univariée – EDA NLP
L’Analyse Univariée est le fait d’inspecter chaque feature séparément.
Cela va nous permettre d’approfondir notre connaissance sur le dataset.
On est ici en phase de compréhension.
La question associée à l’Analyse Univariée est : Quelles sont les données qui composent notre dataset ?
Target
Comme on le remarquait plus haut, la colonne la plus intéressante pour nous est la target discourse_effectiveness. Cette colonne indique l’efficacité d’un discours.
Chaque ligne, chaque discours, peut avoir une efficacité différente. On les classes selon 3 niveaux:
- Inefficace –
Ineffective - Adéquat –
Adequate - Efficace –
Effective
Voyons comment sont distribuées ces 3 classes dans notre dataset:
import seaborn as sns
import matplotlib.pyplot as plt
stats_target = df['discourse_effectiveness'].value_counts(normalize=True)
print(stats_target)
plt.figure(figsize=(14,5))
plt.subplot(1,2,1)
sns.countplot(data=df,y='discourse_effectiveness')
plt.subplot(1,2,2)
stats_target.plot.bar(rot=25)
plt.ylabel('discourse_effectiveness')
plt.xlabel('% distribution per category')
plt.tight_layout()
plt.show()Sortie:
Adequate: 0.57
Effective: 0.25
Ineffective: 0.17

Ici vous pouvez voir la distribution numérique, mais aussi la distribution statistique qui est plus facile à analyser.
57% des discours sont Adequate, le reste est soit Effective soit Ineffictive.
Dans l’idéal, il nous aurait fallait plus de discours Ineffictive pour avoir un dataset plus équilibré et donc généralisable. Vu que nous n’avons pas d’influence sur les données, continuons avec ce qu’on a!
Données Catégoriques
Maintenant je vous propose d’analyser les types de discours.
Il en existe sept:
- Lead – une introduction qui commence par une statistique, une citation, une description ou tout autre moyen d’attirer l’attention du lecteur et de l’orienter vers la thèse
- Position – une opinion ou une conclusion sur la question principale
- Claim – une affirmation qui soutient la position
- Counterclaim – une affirmation qui réfute une autre affirmation ou qui donne une raison opposée à la position
- Rebuttal – une affirmation qui réfute une contre-affirmation
- Evidence – idées ou exemples qui appuient les affirmations, les contre-affirmations ou les réfutations
- Concluding Statement – une déclaration finale qui réaffirme les affirmations
Au vue des différents types, il semblerait logique qu’on ait moins de Counterclaim et de Rebuttal que d’autres types.
Par ailleurs, je tiens à rappeler ici que plusieurs discours, plusieurs lignes, peuvent faire partie d’un même essai (essay_id). C’est à dire que plusieurs discours peuvent être écrit par un même auteur, dans un même contexte. Et donc un essay peut contenir plusieurs discourse ayant des types différents ainsi que des degrés d’efficacités différents.
Analysons maintenant la distribution de ce discourse_type:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(14,5))
plt.subplot(1,2,1)
sns.countplot(data=df,y='discourse_type')
plt.subplot(1,2,2)
df['discourse_type'].value_counts(normalize=True).plot.bar(rot=25)
plt.ylabel('discourse_type')
plt.xlabel('% distribution per category')
plt.tight_layout()
plt.show()
On peut voir ici que la répartition n’est pas également répartie. Notre hypothèse est vérifiée pour Counterclaim et de Rebuttal. Néanmoins, la distribution est extrêmement déséquilibrée en faveur de Claim et Evidence. À garder en mémoire pour la suite de l’analyse.
NLP Data
Longueur du discours
Maintenant que nous avons analysé les données catégoriques. Nous pouvons passer à l’analyse des données NLP.
Tout d’abord analysons la longueur de nos phrases.
Pour ça, on crée une nouvelle colonne discourse_length contenant la taille de chacun des discours:
def length_disc(discourse_text):
return len(discourse_text.split())
df['discourse_length'] = df['discourse_text'].apply(length_disc)Affichons le résultat:
df.head()
Maintenant nous pouvons analyse la colonne discourse_length comme n’importe quel données numériques:
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.kdeplot(df['discourse_length'],color='g',shade=True)
plt.subplot(1,2,2)
sns.boxplot(df['discourse_length'])
plt.show()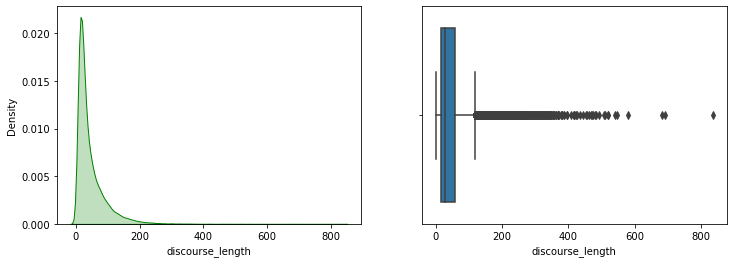
Ils sembleraient qu’il y ait beaucoup de valeurs extrêmement éloignées de la moyenne. On appelle cela des outliers et ils impactent notre analyse. On ne peut pas bien détailler la boîte de Tukey sur la droite.
Zoomons sur le graph:
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.kdeplot(df['discourse_length'],color='g',shade=True)
plt.subplot(1,2,2)
sns.boxplot(df['discourse_length'])
plt.show()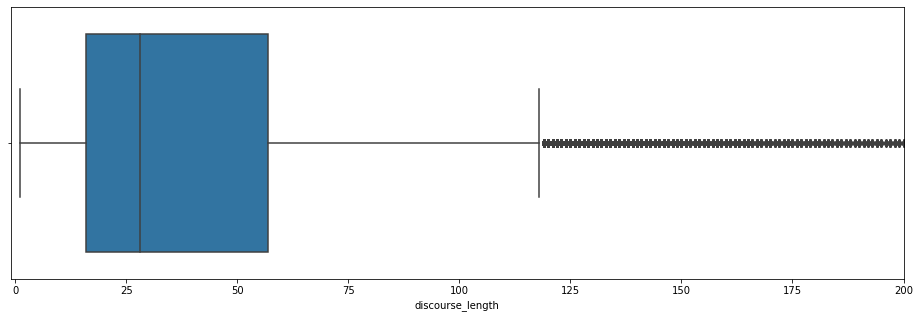
Voilà qui est mieux ! La plupart des discours ont une longueur inférieur à 120 mots, la moyenne étant environ à 30 mots.
Malgré cela, il semblerait qu’il y ait beaucoup de discours au dessus de 120 mots. Analysons ces outliers.
Tout d’abord en calculant la Skewness et le Kurtosis. Deux mesures, détaillées dans cet article, qui nous permettent de comprendre nos outliers et leur distribution:
print("Skew: {}".format(df['discourse_length'].skew()))
print("Kurtosis: {}".format(df['discourse_length'].kurtosis()))Sortie:
Skew: 2.92
Kurtosis: 15.61
Les outliers sont beaucoup espacées de la moyenne avec un Kurtosis très haut.
Outliers
Dans la plupart des distributions, il est normal d’avoir des valeurs extrêmes.
Mais les outliers, eux, sont peu fréquent, voire anormaux. Il peut s’agir d’une erreur dans le dataset.
Alors affichons ces outliers pour déterminer s’il s’agit d’une erreur.
Pour déterminer les outliers, on utilise le z-score.
Le z-score calcule la distance d’un point avec la moyenne.
Si le z-score est inférieur à -3 ou supérieur à 3, il est considéré comme un outlier.
Voyons ça en affichant tous les points inférieur à -3 et supérieur à 3 :
from scipy.stats import zscore
y_outliers = df[abs(zscore(df['discourse_length'])) >= 3 ]
y_outliers
719 lignes sont des outliers. Il ne semble pas qu’elles représentent des erreurs. On peut considérer ces lignes comme des discours qui n’ont pas été séparé en plusieurs essais(à vérifier).
Affichons la distribution de l’efficacité de ces outliers:
stats_long_text = y_outliers['discourse_effectiveness'].value_counts(normalize=True)
print(stats_long_text)
stats_long_text.plot.bar(rot=25)Sortie:
Effective: 0.53
Ineffective: 0.34
Adequate: 0.12
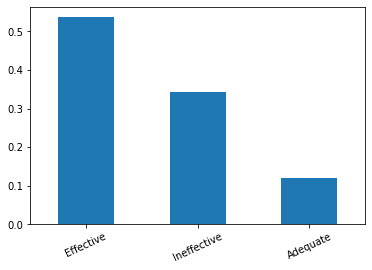
Ici, un premier indice émerge. La plupart des longs discours semblent être Effective
Nous pouvons donc formuler une première hypothèse : plus un discours est long, plus il semble Effective.
Mais nous pouvons aussi voir qu’il peut être plus fréquemment Ineffective (34%) qu’un discours de longueur normale (17%).
Affichons la distribution des types pour ces outliers:
stats_long_text = y_outliers['discourse_type'].value_counts(normalize=True)
print(stats_long_text)
stats_long_text.plot.bar(rot=25)Sortie:
Evidence: 0.93
Concluding Statement: 0.03
Lead: 0.02
Counterclaim: 0.001
Rebuttal: 0.001
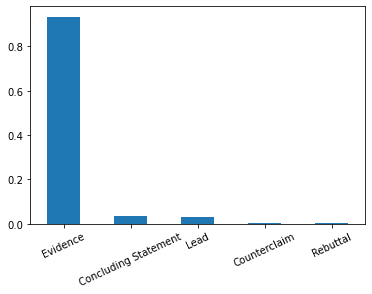
Sur ce point, la statistique est très claire. La plupart des discours longs sont de type Evidence.
Mais est-ce que les discours de type Evidence sont pour la plupart Effective ?
Nous verrons cela dans l’Analyse Multivariée.
Pour l’instant, continuons avec l’analyse des mots qui composent les discours !
Preprocessing
Pour analyser les mots qui composent les discours, nous allons d’abord effectuer un preprocessing en enlevant les:
- numéros
- stopwords
- caractères spéciaux
Ici je copie-colle le code du tutoriel Preprocessing NLP – Tutorial pour nettoyer rapidement un texte en y appliquant quelques changements:
import nltk
import string
from nltk.stem import WordNetLemmatizer
import re
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('words')
nltk.download('wordnet')
stopwords = nltk.corpus.stopwords.words('english')
words = set(nltk.corpus.words.words())
lemmatizer = WordNetLemmatizer()
def preprocessSentence(sentence):
sentence_w_punct = "".join([i.lower() for i in sentence if i not in string.punctuation])
sentence_w_num = ''.join(i for i in sentence_w_punct if not i.isdigit())
tokenize_sentence = nltk.tokenize.word_tokenize(sentence_w_num)
words_w_stopwords = [i for i in tokenize_sentence if i not in stopwords]
words_lemmatize = (lemmatizer.lemmatize(w) for w in words_w_stopwords)
words_lemmatize = (re.sub(r"[^a-zA-Z0-9]","",w) for w in words_lemmatize)
sentence_clean = ' '.join(w for w in words_lemmatize if w.lower() in words or not w.isalpha())
return sentence_clean.split()On affiche la phrase de base et la phrase preprocessé:
print(df.iloc[1]['discourse_text'])
print('\n')
print(preprocessSentence(df.iloc[1]['discourse_text']))Sortie:
On my perspective, I think that the face is a natural landform because I dont think that there is any life on Mars. In these next few paragraphs, I’ll be talking about how I think that is is a natural landform
[‘perspective’, ‘think’, ‘face’, ‘natural’, ‘dont’, ‘think’, ‘life’, ‘mar’, ‘next’, ‘paragraph’, ‘ill’, ‘talking’, ‘think’, ‘natural’]
Maintenant on applique le preprocessing à l’entièreté de notre DataFrame:
df_words = df['discourse_text'].apply(preprocessSentence)On récupère le résultat dans df_words.
Analyse des mots
On a maintenant un DataFrame contenant nos discours preprocessé. Chaque ligne représente une liste contenant les mots du discours.
J’aimerais effectuer un one hot encoding, là encore le processus est expliqué dans notre article sur le Preprocessing NLP.
L’idée du one-hot encoding est d’avoir des colonnes représentant tous les mots du dataset, et des lignes indiquant 1 si le mot est présent dans le discours, 0 sinon.
Si vous avez de l’espace mémoire utilisez cette ligne pour faire le one-hot encoding:
#dfa = pd.get_dummies(df_words.apply(pd.Series).stack()).sum(level=0)Sinon utilisez l’option avec concat en séparant votre dataset en deux(ou plus) et en one hot encodant les parties séparément.
Finissez en les concaténant:
dfa1 = pd.get_dummies(df_words.iloc[:20000].apply(pd.Series).stack()).sum(level=0)
dfa2 = pd.get_dummies(df_words.iloc[20000:].apply(pd.Series).stack()).sum(level=0)
dfb = pd.concat([dfa1,dfa2], axis=0, ignore_index=True)Si vous avez utilisez l’option concat, il faut maintenant que vous remplaciez les NaN par 0:
dfb = dfb.fillna(0).astype(int)On affiche le résultat:
dfb.head()
Le dataset est bien one hot encodé !
Cela va nous permettre de compter plus facilement le nombre d’occurence de chaque mot:
words_sum = dfb.sum(axis = 0).TLe DataFrame words_sum contient le nombre de fois qu’apparaît chacun des mots.
Il est maintenant rangé par ordre alphabétiques du A au Z mais j’aimerais analyser les mots qui apparaissent le plus souvent.
Trions alors words_sum par ordre d’occurence décroissant:
words_sum = words_sum.sort_values(ascending=False)Affichons maintenant les mots qui apparaissent le plus souvent dans notre dataset:
words_sum_max = words_sum.head(20)
plt.figure(figsize=(16,5))
words_sum_max.plot.bar(rot=25)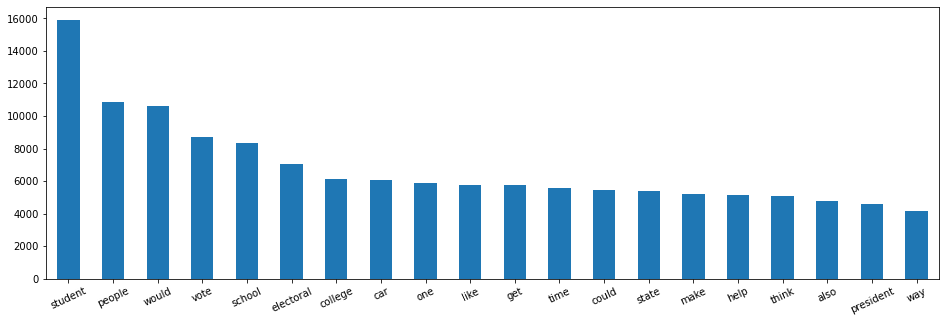
‘student’, ‘people’, ‘would’, ‘vote’, ‘school’, …
Ces mots font référence à l’école et aux élections. Pour l’instant, on ne peut pas dire beaucoup de ces mots.
Il est intéressant de les afficher dès maintenant pour les mettre en relation plus tard lors de l’analyse Multivariée.
Effectivement, les mots les plus fréquents dans le dataset global ne seront peut-être pas les mêmes que dans des discours Effective.
Analyse Multivariée – EDA NLP
Nous avons maintenant une vision beaucoup plus précise sur notre dataset grâce notre analyse de:
- L’efficacité (target)
- Les types de discours
- La longueur des discours
- Les mots qui composent les discours
Je vous propose maintenant de passer à l’Analyse Multivariée.
L’Analyse Multivariée est le fait d’inspecter nos features en les mettant en relation avec notre target.
Cela va nous permettre d’émettre des hypothèses sur le dataset.
On est ici en phase de théorisation.
La question associée à l’Analyse Multivariée est : Y-a-t-il un lien entre nos features et la target ?
Données Catégoriques
Commençons avec les données catégoriques.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Y-a-t-il un lien entre les types de discours (discourse_type) et leur efficacité (discourse_effectiveness) ?
Affichons le nombre d’occurrences de chacun de ces types en fonction de l’efficacité:
import numpy as np
plt.figure(figsize=(8,8))
cross = pd.crosstab(index=df['discourse_effectiveness'],columns=df['discourse_type'],normalize='index')
cross.plot.barh(stacked=True,rot=40,cmap='plasma').legend(bbox_to_anchor=(1.0, 1.0))
plt.xlabel('% distribution per category')
plt.xticks(np.arange(0,1.1,0.2))
plt.title("Forestfire damage each {}".format('discourse_type'))
plt.show()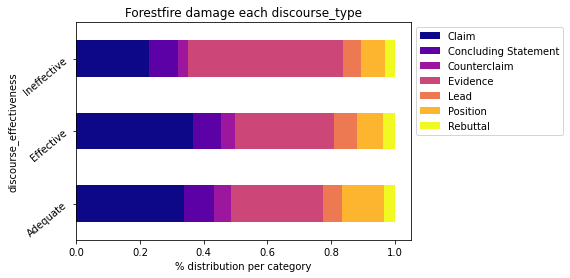
Impressionnant ! À première vu on peut voir que plus un discours est de type Claim, plus il est Effective.
Mais est-ce vraiment le cas ?
En revenant sur notre Analyse Univariée, on peut voir que Claim et Evidence sont des types surreprésentées dans notre dataset. Il est donc logique de les voir en surreprésentation dans cette analyse.
En fait, il serait plus logique d’évaluer cette distribution de manière statistique. Ainsi tous les discourse_type auraient le même poids dans le dataset et l’analyse ne serait pas biaisée.
Par exemple nous n’avons que 2.291 Lead contre 12.105 Evidence. Il y aura donc forcément plus de Evidence dans notre analyse. Cela crée un déséquilibre. Pour Effective, on a 2.885 Evidence et 683 Lead. Est-ce que pour autant cela veut dire qu’un discours de type Evidence est plus efficace qu’un discours Lead ?
Pour tirer tout cela au clair, il nous faut faire une analyse normalisée.
Normalisation
Pour donner le même poids à chacun des discourse_type dans le dataset, il faut normaliser leurs occurrences.
On commence par prendre le nombre d’occurences de chaque discourse_type selon le discourse_effectiveness:
cross_norm = pd.crosstab(index=df['discourse_effectiveness'],columns=df['discourse_type'])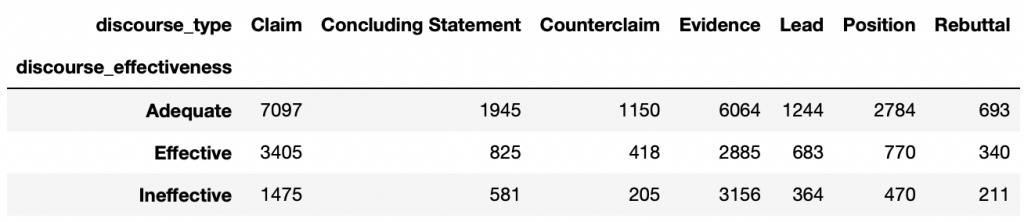
Ensuite on compte le nombre total d’occurrences de chacun des discourse_type:
count_type = df['discourse_type'].value_counts()Et on peut finalement normaliser chacune des occurrences selon l’efficacité. On divise par le nombre total d’occurences du type et multiple par le même chiffre (1000):
cross_norm['Claim'] = (cross_norm['Claim']/count_type['Claim'])*1000
cross_norm['Concluding Statement'] = (cross_norm['Concluding Statement']/count_type['Concluding Statement'])*1000
cross_norm['Counterclaim'] = (cross_norm['Counterclaim']/count_type['Counterclaim'])*1000
cross_norm['Evidence'] = (cross_norm['Evidence']/count_type['Evidence'])*1000
cross_norm['Lead'] = (cross_norm['Lead']/count_type['Lead'])*1000
cross_norm['Position'] = (cross_norm['Position']/count_type['Position'])*1000
cross_norm['Rebuttal'] = (cross_norm['Rebuttal']/count_type['Rebuttal'])*1000
On a maintenant des occurrences normalisées. Il ne nous manque plus qu’à créer des statistiques.
Pour chaque efficacité, on somme le nombre total d’occurrences normalisées:
cross_normSum = cross_norm.sum(axis=1)
print(cross_normSum)Puis on utilise cette somme pour créer nos statistiques:
cross_norm.loc['Adequate'] = cross_norm.loc['Adequate']/cross_normSum['Adequate']
cross_norm.loc['Effective'] = cross_norm.loc['Effective']/cross_normSum['Effective']
cross_norm.loc['Ineffective'] = cross_norm.loc['Ineffective']/cross_normSum['Ineffective']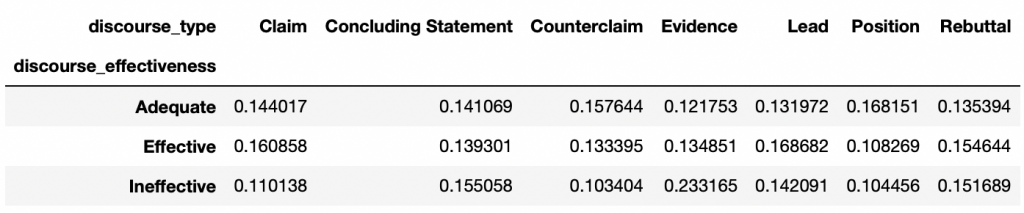
Cela fait, on affiche la distribution normalisée de chacun des types en fonction de l’efficacité:
cross_norm.plot.barh(stacked=True,rot=40,cmap='inferno').legend(bbox_to_anchor=(1.0, 1.0))
plt.xlabel('% distribution per category')
plt.xticks(np.arange(0,1.1,0.2))
plt.title("Forestfire damage each {}".format('discourse_type'))
plt.show()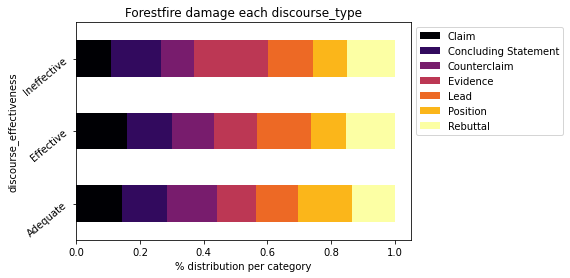
Voilà qui est bien mieux et plus logique !
La plupart des types ne semblent pas affecter l’efficacité du discours.
La plupart ?
Il semble que certains se distinguent plus que d’autres.
Affichons les valeurs max pour chacun des discourse_effectiveness:
Pour Ineffective:
cross_norm.columns[(cross_norm == cross_norm.loc['Ineffective'].max()).any()].tolist()Sortie: Evidence
Pour Adequat:
cross_norm.columns[(cross_norm == cross_norm.loc['Adequate'].max()).any()].tolist()Sortie: Position
Pour Effective:
cross_norm.columns[(cross_norm == cross_norm.loc['Effective'].max()).any()].tolist()Sortie: Lead
Lors de l’Analyse Univariée, nous avons vu que la plupart des discours longs sont Effective et de type Evidence.
Nous aurions pu établir un lien entre un discours de type Evidence et un discours de type Effective. Mais comme nous le voyons ici, les deux ne sont pas corrélés.
En effet, la plupart des discours de type Evidence sont Ineffective, quand les types Position sont Adequate et les Lead sont Effective.
La normalisation est obligatoire ici pour bien comprendre les données. Si nous ne l’avions pas fait, nous serions arrivés à la conclusion que le discours de type Claim est le plus utile pour les discours Adequate et Effective. Ce n’est pas vrai. Ce biais est dû au manque de données dans notre dataset (au manque de généralisation).
La plupart de nos données sont de type Evidence(12.105) et Claim(11.977) alors que seulement 2.291 lignes sont dénombrées pour le type Lead.
Par ailleurs, un autre biais peut subsister. Avons-nous assez de données sur le Lead pour tirer une conclusion sur ce label ?
Pour l’instant, le concours n’a qu’un seul dataset, donc partons du principe que oui 😉
NLP Data
Longueur du discours
Continuons sur l’analyse de la longueur du discours en fonction de l’efficacité:
plt.figure(figsize=(8,4))
sns.boxplot(data=df, x='discourse_length', y='discourse_effectiveness').set_xlim(-1, 220)
plt.show()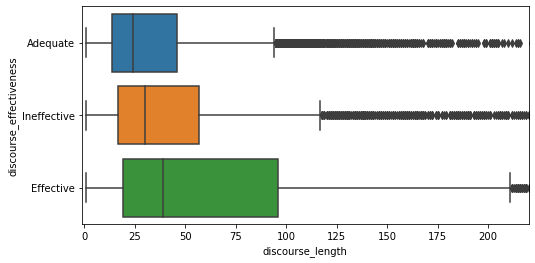
Plus un discours est long, plus il a de chance d’être Effective. On peut aussi afficher la moyenne de mots dans chacune des catégories.
df.groupby(['discourse_effectiveness'])['discourse_length'].median()Sortie:
Adequate: 24
Effective: 39
Ineffective: 30
Analyse des mots
Finalement l’analyse des mots.
Est-ce que les mots choisis ont impactent sur l’efficacité d’un discours ? Si oui on devrait trouver des disparités selon l’efficacité.
On commence par extraire la colonne discourse_effectiveness du dataset et l’ajouter à dfb, les discours one-hot encodé:
dfb['discourse_effectiveness'] = df['discourse_effectiveness']
Nous allons séparer ce dataset selon 3 DataFrame:
EffectiveAdequatIneffective
Et analyser les mots contenu dans chacun d’entre eux:
dfb_ineffective = dfb.loc[dfb['discourse_effectiveness'] == 'Ineffective'].drop('discourse_effectiveness', axis=1)
dfb_adequate = dfb.loc[dfb['discourse_effectiveness'] == 'Adequate'].drop('discourse_effectiveness', axis=1)
dfb_effective = dfb.loc[dfb['discourse_effectiveness'] == 'Effective'].drop('discourse_effectiveness', axis=1)Comme pour l’Analyse Univariée, on somme l’occurence de chacun des mots:
words_sum_ineffective = dfb_ineffective.sum(axis = 0).T
words_sum_adequate = dfb_adequate.sum(axis = 0).T
words_sum_effective = dfb_effective.sum(axis = 0).TOn les tries par ordres décroissant, le plus grand nombre d’occurrences en premier:
words_sum_ineffective = words_sum_ineffective.sort_values(ascending=False)
words_sum_adequate = words_sum_adequate.sort_values(ascending=False)
words_sum_effective = words_sum_effective.sort_values(ascending=False)Et on prend les 20 premières occurrences:
words_sum_ineffective_max = words_sum_ineffective.head(20)
words_sum_adequate_max = words_sum_adequate.head(20)
words_sum_effective_max = words_sum_effective.head(20)On peut afficher le graphique pour chacun des DataFrameq-s mais ici je préfère les regrouper dans un seul DataFrame et afficher le head.
Cela nous permettra de comparer plus simplement l’occurrence des mots selon les trois types d’efficacité.
pd.DataFrame(list(zip(list(words_sum_effective_max.index),
list(words_sum_adequate_max.index),
list(words_sum_ineffective_max.index))),
columns =['Effective', 'Adequate', 'Ineffective']).head(10)
Il ne semble pas y avoir de différence remarquable. Ni entre les Labels, ni entre les Labels et le dataset global.
En fait, habituellement, la différence se voit sur les lignes suivantes. Les premières étant toujours partagées sur l’entièreté du dataset.
Je vous invite donc à afficher chez vous les 100 ou 500 mots les plus fréquent selon le discourse_effectiveness et de nous dire en commentaire votre analyse 🔥
D’après mes études personnelles, je sais que les verbes apparaissent davantage dans les discours efficaces. Est-ce le cas dans notre dataset ? Si oui, cela peut être un indice utile pour nous.
Analyses des Tags
Pour étudier l’occurence des verbes, on utilise les tag NLTK.
NLTK est une librairie de NLP permettant d’analyser des phrases et d’en retirer des tags.
Par exemple elle peut repérer les noms, les verbes, les adjectifs, etc.
Parfait pour nous !
Reprenons nos mots et leurs occurences. Créons un nouvelle colonne word grâce aux indexes :
words_sum_ineffective = words_sum_ineffective.to_frame()
words_sum_ineffective['word'] = words_sum_ineffective.index
words_sum_adequate = words_sum_adequate.to_frame()
words_sum_adequate['word'] = words_sum_adequate.index
words_sum_effective = words_sum_effective.to_frame()
words_sum_effective['word'] = words_sum_effective.indexOn a maintenant une colonne représentant le nombre d’occurence et une colonne représentant le mot.
Ajoutons une dernière colonne représentant le tag grâce à la fonction pos_tag de nltk.tag:
from nltk import tag
nltk.download('averaged_perceptron_tagger')
words_sum_ineffective['tag'] = [x[1] for x in tag.pos_tag(words_sum_ineffective['word'])]
words_sum_adequate['tag'] = [x[1] for x in tag.pos_tag(words_sum_adequate['word'])]
words_sum_effective['tag'] = [x[1] for x in tag.pos_tag(words_sum_effective['word'])]Les tags sont beaucoup détaillées. Par exemple il y a 4 types de verbes (passé, présent, etc) qui ont tous un tag différent. Ce détails ne nous intéresse pas. On nettoie alors ces tags pour ne garder que l’essentiel (un tag par verbe, un tag par adjectif etc):
def easyTag(x):
if x.startswith('VB'):
x = 'VB'
elif x.startswith('JJ'):
x = 'JJ'
elif x.startswith('RB'):
x = 'RB'
elif x.startswith('NN'):
x = 'NN'
return x
words_sum_ineffective['tag'] = words_sum_ineffective['tag'].apply(lambda x: easyTag(x))
words_sum_adequate['tag'] = words_sum_adequate['tag'].apply(lambda x: easyTag(x))
words_sum_effective['tag'] = words_sum_effective['tag'].apply(lambda x: easyTag(x))
words_sum_ineffective.head(10)
On a maintenant un DataFrame avec notre colonne tag:
- NN pour les noms
- VB pour les verbes
- JJ pour les adjectifs
- RB pour les adverbes
- … (vous pouvez consulter le reste des Tags sur notre article dédié au sujet)
Finalement, on compte le nombre d’occurence par Tag:
def count_tag(words_sum):
tag_count = []
for x in words_sum['tag'].unique():
tmp = []
tmp.append(x)
tmp.append(words_sum[words_sum['tag'] == x][0].sum())
tag_count.append(tmp)
return pd.DataFrame(tag_count, columns= ['tag','count'])
tag_ineffective = count_tag(words_sum_ineffective).sort_values(by=['count'], ascending=False)
tag_adequate = count_tag(words_sum_adequate).sort_values(by=['count'], ascending=False)
tag_effective = count_tag(words_sum_effective).sort_values(by=['count'], ascending=False)Et on peut afficher le résultat:
plt.figure(figsize=(6,8))
plt.subplot(3,1,1)
sns.barplot(x="tag", y="count", data=tag_ineffective.iloc[:6])
plt.title('Tag for Ineffective')
plt.subplot(3,1,2)
sns.barplot(x="tag", y="count", data=tag_adequate.iloc[:6])
plt.title('Tag for Adequate')
plt.subplot(3,1,3)
sns.barplot(x="tag", y="count", data=tag_effective.iloc[:6])
plt.title('Tag for Effective')
plt.tight_layout()
plt.show()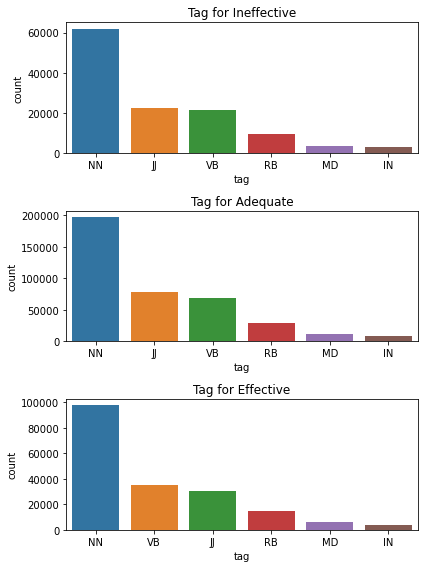
Les noms apparaissent le plus souvent quelque soit le type de discours. Cela semble logique car ils composent en majorité les phrases. Cependant cela ne nous donne que peu d’informations.
Analysons le reste des tags en omettant les noms:
plt.figure(figsize=(6,8))
plt.subplot(3,1,1)
sns.barplot(x="tag", y="count", data=tag_ineffective.iloc[1:6], color="#066b8b")
plt.title('Tag for Ineffective')
plt.subplot(3,1,2)
sns.barplot(x="tag", y="count", data=tag_adequate.iloc[1:6], color="#066b8b")
plt.title('Tag for Adequate')
plt.subplot(3,1,3)
sns.barplot(x="tag", y="count", data=tag_effective.iloc[1:6], color="#066b8b")
plt.title('Tag for Effective')
plt.tight_layout()
plt.show()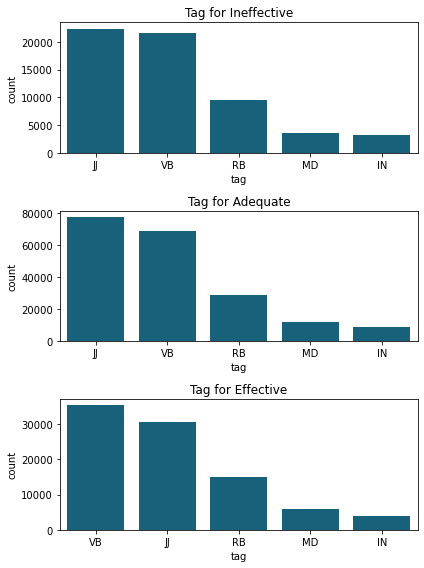
Ici, le nombre d’occurrences n’est pas important. Comme le discours Adequate a beaucoup plus de mots, il y aura évidemment plus de mots dans chaque tag de cette section.
Il faut ici regarde le classement des tags.
Ce que nous pouvons constater, c’est que les discours Effective contiennent plus de verbes (VB) que les autres types.
Notre hypothèse semble se vérifiée !
Allons plus loin en analysant le nombre de verbe par discours selon l’efficacité.
Nombre moyen de verbes selon l’efficacité
Cette fois on applique pos_tag sur l’ensemble de nos mots préprocessés dans df_words.
Pour rappelle ce DataFrame contient un discours par ligne avec uniquement les mots importants(sans stopwords, caractère spéciaux, etc). Utiliser ce DataFrame facilitera le décompte des tags:
list_tags = []
for i in range(len(df_words)):
list_tags.append([easyTag(x[1]) for x in tag.pos_tag(df_words[i])])Ensuite on compte le nombre de verbe dans chacune des lignes:
df_tag = pd.DataFrame(columns=['VB'])
for i in range(len(list_tags)):
df_tag = df_tag.append({'VB': list_tags[i].count('VB')}, ignore_index=True)On extrait la colonne discourse_effectiveness et l’ajoute à df_tag:
df_tag['discourse_effectiveness'] = df['discourse_effectiveness']
df_tag.head()
Finalement on affiche le nombre de verbe moyen par efficacité.
Pour Ineffective:
VB_ineffective = df_tag.loc[df_tag['discourse_effectiveness'] == 'Ineffective']
VB_ineffective['tag_VB'].sum() / len(VB_ineffective)Sortie: 3.8
Pour Adequate:
VB_adequate = df_tag.loc[df_tag['discourse_effectiveness'] == 'Adequate']
VB_adequate['tag_VB'].sum() / len(VB_adequate)Sortie: 2.8
Pour Effective:
VB_effective = df_tag.loc[df_tag['discourse_effectiveness'] == 'Effective']
VB_effective['tag_VB'].sum() / len(VB_effective)Sortie: 5.1
Dans un discours Effective on décompte 5 verbe moyens utilisés. C’est 2 de plus que dans un discours Adequate et 1 de plus que dans un discours Ineffective.
Conclusion – EDA NLP
Pour améliorer un discours :
- Utiliser environ 39 mots
- 5 verbes (mais aussi des adjectifs)
- Ayez un élément directeur
Lead(une statistique, une citation, une description) dans votre discours pour attirer l’attention du lecteur et l’orienter vers la thèse. - Evitez de partager des idées qui soutiennent des affirmations, des contre-affirmations ou des réfutations (la plupart des discours de type
Evidencesont inefficaces).
Pour aller plus loin, de nombreuses analyses peuvent être faites. Il y a des questions auxquelles nous n’avons pas répondu. Nous pourrions par exemple étudier quels sont les mots qui composent un discours de type Lead vs. Evidence.
Des biais subsiste encore, par exemple le nombre de verbe moyen est plus haut dans les discours Effective mais le nombre de mots moyen est plus haut aussi. Est-ce un prérequis pour avoir un discours Effective ou est-ce simplement un biais du dataset ?
On pourrait analyser des jours ce dataset et répertorier tous les biais. Mais maintenant qu’on a une première analyse conforme et détaillée, le plus important est de passer à l’action et d’utiliser un modèle de Deep Learning pour atteindre l’objectif principal: classer les discours des élèves comme étant « efficaces », « adéquats » ou » inefficaces » !
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes sur des tâches de NLP.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



