
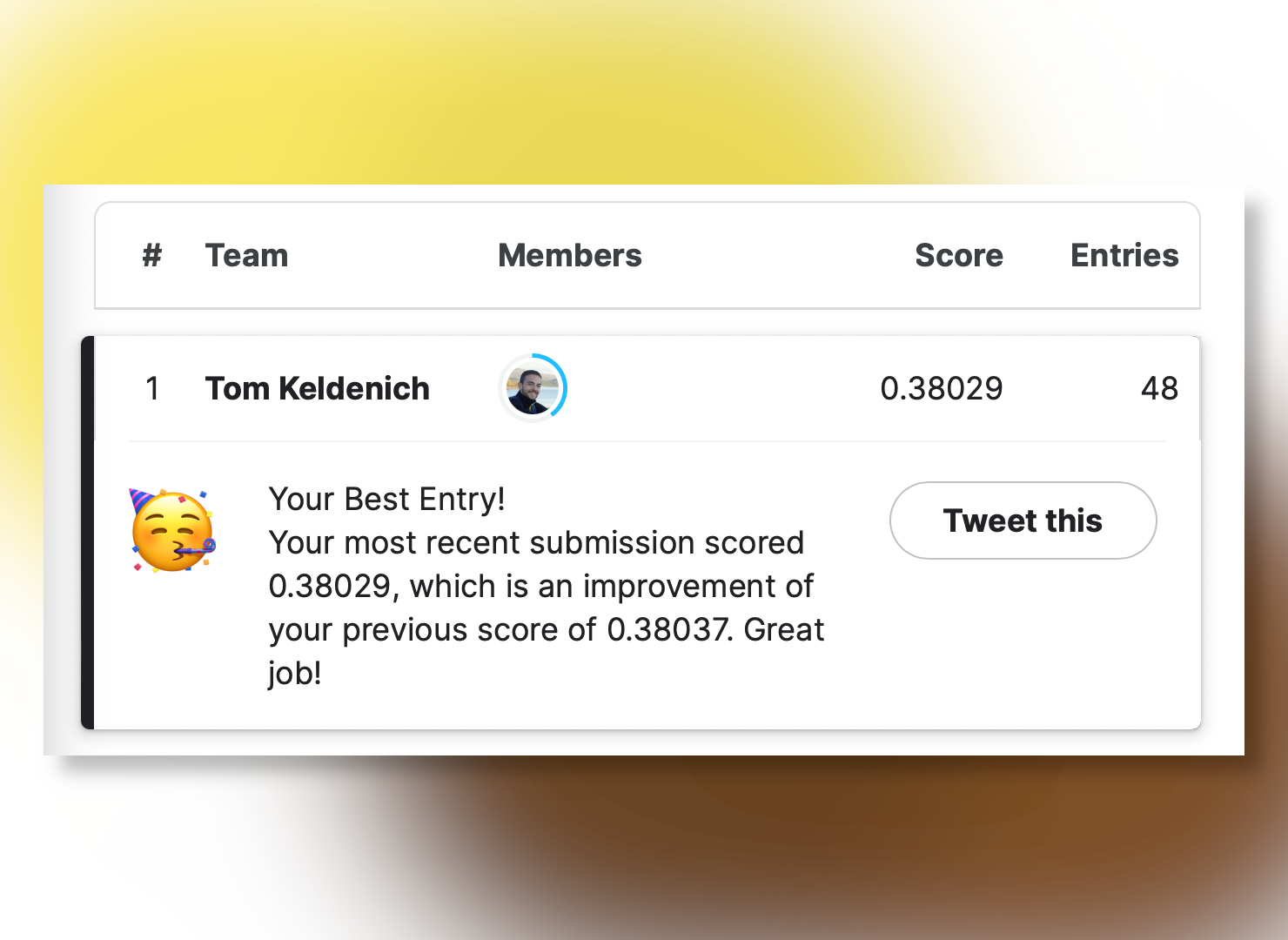
Le 04 avril 2023, je me suis hissé TOP 1 dans le classement d’une compétition Kaggle. Je t’explique comment dans cet article !
Kaggle est un site web qui permet à toute personne de participer à des compétitions de Machine Learning.
Le but est simple : construire le meilleur modèle de Machine Learning pour résoudre un problème donné.
Kaggle réunit les débutants en Intelligence Artificielle mais aussi les personnes les plus avancées dans le domaine.
C’est ainsi qu’on peut voir se challenger entre eux des experts de grandes entreprises IA comme Nvidia, Google, Facebook… et de simples étudiants d’université !
Dans cet article, je vais te guider à travers le code qui m’a permis d’atteindre la première position dans la compétition Store Sales – Time Series Forecasting.
En parcourant ce code, tu pourras le copier et toi aussi atteindre les sommets du classement… voir même l’améliorer pour me battre !
Mais alors pourquoi je te partage ce code si je risque de perdre ma place ?
Tout d’abord parce que j’aime l’open source ! L’idée que tout le monde puisse accéder à l’information me plaît.
Ensuite parce que de toute manière, cette compétition est dans la catégorie Getting Started. Cela implique que le classement se renouvelle tous les 3 mois. Mais surtout qu’il n’y a pas de date limite pour participer à ce challenge.
Les progrès en IA étant ce qu’ils sont, il est évident que mon record sera battu dans les mois ou années qui viennent. Alors, au lieu de contraindre ce progrès, pourquoi ne pas l’encourager en partageant mon code ?
Bref, cela étant dit, pour l’histoire (et surtout pour mon égo) j’ai enregistré le classement du 04 avril 2023 :
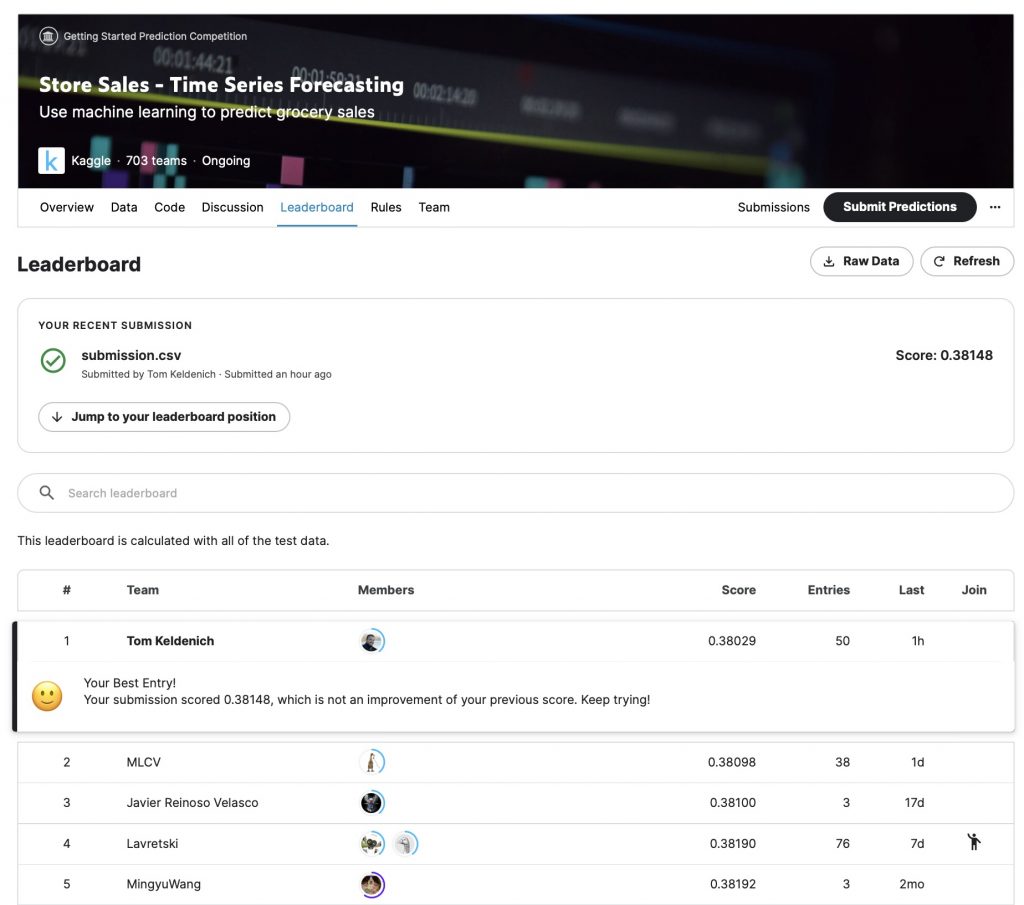
Comment j’ai fait Top 1 sur Kaggle
Pour atteindre la première place je me suis basé sur le code de Ferdinand Berr, en ajoutant quelques changements.
Tout d’abord j’ai modifié les hyperparamètres du modèle qu’il utilise. Puis j’ai utilisé une technique d’amélioration basique mais qui semble avoir être délaissé dans cette compétition : la Méthode d’Ensemble.
L’idée est de combiner les prédictions de plusieurs modèles et d’en faire la moyenne pour obtenir un résultat optimal. Je détaille plus longuement la méthode dans cet article.
L’objectif de cette compétition est de prédire le nombre de ventes que feront différents magasins situés en Équateur.
Pour effectuer ces prédictions, on devra se baser sur les ventes passées du magasins.
Ce type de variable est appelé des séries temporelles.
Une série temporelle est une séquence de données mesurées à intervalles réguliers dans le temps.
Dans notre cas, les données ont été enregistrées tous les jours.
Dans ce qui suit je vais te détailler le code que j’ai utilisé. J’ai supprimé le surplus d’informations qui n’aidait pas à la compréhension pour ne garder que l’essentiel. Tu pourras ainsi voir que le code est plus aéré que dans la solution dont je me suis inspiré.
Ce tutoriel s’adresse à des personnes de niveau plutôt intermédiaire en IA, même s’il peut aussi être aborder par des débutants.
On va combiner plusieurs données entre elles et utiliser une bibliothèque de Machine Learning peu connue mais performante pour notre tâche : darts.
Darts permet de manipuler et de prédire les valeurs d’une série temporelle aisément.
Allez ! Sans plus d’introduction, mettons-nous au boulot !
Données
Tout d’abord je te propose d’explorer le dataset.
Notre objectif est de prédire les ventes futures de magasins localisés en Équateur, pour les dates du 16 août 2017 au 31 août 2017 (16 jours).
Dans notre dataset, il y a 54 magasins pour 33 familles de produits.
Il faut prédire les ventes pour chacune de ces familles de produits de chaque magasin. Donc 33 * 54 * 16 = 28 512 valeurs à prédire.
Si tu utilise un notebook pour travailler, tu peux charger le dataset grâce à cette ligne de code :
!git clone https://github.com/tkeldenich/datasets.git
!unzip /content/datasets/store-sales-time-series-forecasting.zip -d /content/datasets/Pour nous aider à réaliser ces prédictions, ce n’est pas moins de 8 fichiers CSV qui nous sont fournis.
Affichons-les pour mieux les comprendre.
train.csv
Tout d’abord le fichier principal : train.csv. Il contient quelques features et le label à prédire sales, le nombre de ventes par jour :
import pandas as pd
df_train = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/train.csv')
display(df_train.head())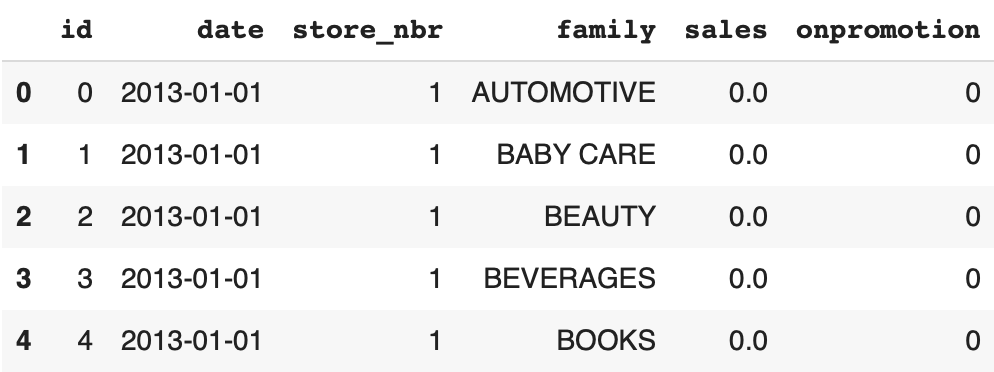
Voici les colonnes du DataFrame :
id– l’index de la lignedate– la date du jourstore_nbr– le magasinfamily– la famille de produitssales– le nombre de ventes dans cette familleonpromotion– le nombre de produits en promotion dans cette famille
holidays_events.csv
Le holidays_events.csv regroupe les jours de fêtes nationales. Ces informations sont indépendantes du magasin mais peuvent avoir un impact sur les ventes.
Par exemple lors d’un jour de fête, il pourrait y avoir plus de monde dans la ville et donc plus de clients dans les magasins. Ou à l’inverse, plus de gens peuvent partir en vacances et donc il y aurait moins de clients dans les magasins.
df_holidays_events = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/holidays_events.csv')
display(df_holidays_events.head())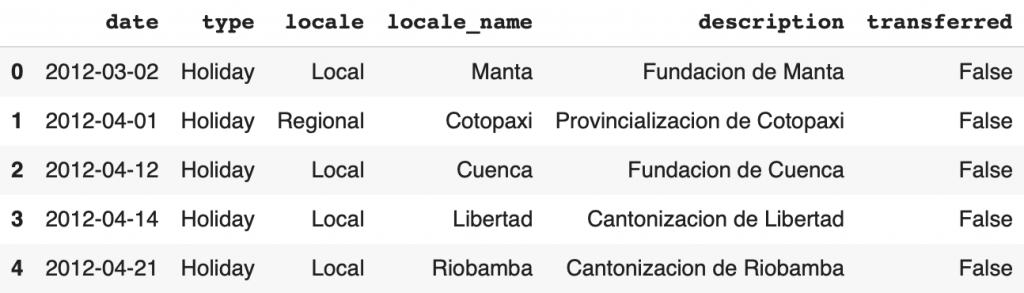
Voici les colonnes du DataFrame :
date– la date de la fêtetype– le type de fête (Holiday– Vacances,Event– Événement,Transfer– Transféré (voir colonne transféré),Additional– Additionnelle,Bridge– Pont,Work Day– Jour de travail)locale– la portée de l’événement (Local, Regional, National)locale_name– la ville où l’événement à lieudescription– nom de l’événementtransferred– si l’événement à été transféré (reporté à un autre jour) ou non
oil.csv
Ensuite un fichier CSV regroupe le prix de l’essence journalier du 01 janvier 2013 au 31 août 2017 :
df_oil = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/oil.csv')
display(df_oil.head())
store.csv
Le fichier store.csv regroupe des informations sur les magasins. Il y a un magasin par ligne donc 54 lignes :
df_stores = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/stores.csv')
display(df_stores.head())
Les colonnes du DataFrame :
store_nbr– le magasincity– la ville où se situe le magasinstate– l’état où se situe le magasintype– le type du magasincluster– le nombre de magasins similaires dans les environs
transactions.csv
Le fichier transactions.csv regroupe les transactions quotidiennes par magasins :
df_transactions = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/transactions.csv')
display(df_transactions.head())Précision : une transaction est un reçu créé après l’achat d’un client
test.csv
Finalement, on a le test.csv qui nous permettra de prédire la colonne sales. Le fichier débute le 16 août 2017 et s’arrête le 31 août 2017. On a aussi le sample_submission.csv a remplir avec le nombre de ventes par jour et par famille :
df_test = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/test.csv')
df_sample_submission = pd.read_csv('/content/datasets/store-sales-time-series-forecasting/sample_submission.csv')
display(df_test.head())
display(df_sample_submission.head())
Le test.csv contient 5 colonnes :
id– l’index de la ligne (qui permettra de remplir le fichier sample_submission.csv)date– la date du jourstore_nbr– le magasinfamily– la famille de produitssales– le nombre de ventes dans cette familleonpromotion– le nombre de produits en promotion dans cette famille
Maintenant qu’on connaît mieux notre dataset, on va pouvoir passer à l’étape de preprocessing qui va nous permettre de formater nos données pour entraîner notre modèle de Machine Learning.
Preprocessing
Pour commencer le preprocessing, je te propose de regrouper le nom de chaque famille de produits ainsi que le numéro de chaque magasin :
family_list = df_train['family'].unique()
store_list = df_stores['store_nbr'].unique()
display(family_list)
display(store_list)Sortie :
array(['AUTOMOTIVE', 'BABY CARE', 'BEAUTY', 'BEVERAGES', 'BOOKS', 'BREAD/BAKERY', 'CELEBRATION', 'CLEANING', 'DAIRY', 'DELI', 'EGGS', 'FROZEN FOODS', 'GROCERY I', 'GROCERY II', 'HARDWARE', 'HOME AND KITCHEN I', 'HOME AND KITCHEN II', 'HOME APPLIANCES', 'HOME CARE', 'LADIESWEAR', 'LAWN AND GARDEN', 'LINGERIE', 'LIQUOR,WINE,BEER', 'MAGAZINES', 'MEATS', 'PERSONAL CARE', 'PET SUPPLIES', 'PLAYERS AND ELECTRONICS', 'POULTRY', 'PREPARED FOODS', 'PRODUCE', 'SCHOOL AND OFFICE SUPPLIES', 'SEAFOOD'], dtype=object)array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54])Ensuite, on assemble les dataset df_train et df_stores. En regroupant ces informations dans un seul dataset, cela nous permettra d’accéder aux informations plus facilement. En plus de cela, on trie les ventes du DataFrame par date, par famille et par magasins :
train_merged = pd.merge(df_train, df_stores, on ='store_nbr')
train_merged = train_merged.sort_values(["store_nbr","family","date"])
train_merged = train_merged.astype({"store_nbr":'str', "family":'str', "city":'str',
"state":'str', "type":'str', "cluster":'str'})
display(train_merged.head())
Une série temporelle étant le nombre de ventes réalisées par jour pour une famille d’un magasin, ce trie nous permettra de les extraire plus facilement.
Même chose pour le DataFrame de test, on trie les ventes par date, par famille et par magasins :
df_test_dropped = df_test.drop(['onpromotion'], axis=1)
df_test_sorted = df_test_dropped.sort_values(by=['store_nbr','family'])
display(df_test_sorted.head())
Maintenant on va pouvoir concrètement créer des séries temporelles!
Série Temporelle Principale
Je te l’ai dit précédemment, nous allons utiliser une bibliothèque spécifique au traitement de séries temporelles en Python : Darts.
Darts nous permet de manipuler facilement des Séries Temporelles.
Je t’invite à installer la librairie darts :
!pip install darts==0.23.1Comme Pandas avec ses DataFrame, la librairie Darts nous offre sa classe permettant de manipuler les séries temporelles : les TimeSeries.
On va utiliser ces TimeSeries pour extraire nos séries temporelles.
Mais avant ça, il faut que je te parle de notre stratégie.
Stratégie
Rappel : Notre objectif est de prédire pour chaque famille de chaque magasin le nombres de ventes futures. Il y a 33 familles pour 54 magasins.
À partir de là, plusieurs routes peuvent être empruntés.
La plus évidente est d’entraîner un modèle de Machine Learning sur l’ensemble de nos données. Donc sur les 1782 séries temporelles.
C’est évident car cela nous permet d’utiliser un maximum de données pour entraîner notre modèle. Il sera ainsi capable de généraliser sa connaissance à chacune des familles de produits. Avec une telle stratégie, notre modèle aura une bonne prédiction globale.
Une stratégie moins évidente, mais assez logique, est d’entraîner un modèle de Machine Learning pour chaque série temporelle.
Effectivement, en attribuant un modèle par série, on s’assure que chacun des modèles est spécialisé dans sa tâche et donc performant dans sa prédiction, et cela pour chaque famille de produit de chaque magasin.
Le problème de la première méthode, c’est que le modèle, n’ayant qu’une connaissance générale de nos données, n’aura pas une prédiction optimale pour chacune des séries temporelles spécifiques.
Le problème de la deuxième méthode, c’est que le modèle sera spécialisé sur chaque série temporelle, mais manquera de données pour parfaire son entraînement.
On ne va donc prendre aucune des stratégies décrites ci-dessus.
Notre stratégie est de se positionner à l’intervalle de ces deux méthodes.
Après plusieurs tests et analyses de nos données (que je ne détaillerai pas ici), on comprend que les ventes par familles semblent corrélées à travers les différents magasins.
On va entraîner un modèle de Machine Learning par famille de produits.
On aura donc 33 modèles, chacun entrainés sur 54 séries temporelles.
C’est un bon compromis, car cela nous permet d’une part d’avoir beaucoup de données pour entraîner un modèle. Mais aussi d’obtenir, en fin d’entraînement, un modèle spécialisé dans sa tâche (car entraîné sur une seule et même famille de produits).
Maintenant que tu connais la stratégie, implémentons-là !
sales
Extraire les séries temporelles
Pour chaque famille de produits, on va rassembler l’ensemble des séries temporelles la concernant.
On va donc avoir 33 sous-datasets. Ces datasets seront contenus dans le dictionnaire family_TS_dict.
Dans les lignes de code qui suivent, on va extraire les TimeSeries des 54 magasins pour chaque famille.
Ces TimeSeries regrouperont les ventes par famille, la date de chaque vente, mais aussi les covariables dépendantes (indiquer avec group_cols et static_cols) de ces ventes : store_nbr, family, city, state, type, cluster :
import numpy as np
import darts
from darts import TimeSeries
family_TS_dict = {}
for family in family_list:
df_family = train_merged.loc[train_merged['family'] == family]
list_of_TS_family = TimeSeries.from_group_dataframe(
df_family,
time_col="date",
group_cols=["store_nbr","family"],
static_cols=["city","state","type","cluster"],
value_cols="sales",
fill_missing_dates=True,
freq='D')
for ts in list_of_TS_family:
ts = ts.astype(np.float32)
list_of_TS_family = sorted(list_of_TS_family, key=lambda ts: int(ts.static_covariates_values()[0,0]))
family_TS_dict[family] = list_of_TS_familyTu peux aussi voir qu’on indique fill_missing_dates=True car dans le dataset, les ventes de chaque 25 décembre sont manquantes.
On indique aussi freq='D', pour indiquer que l’intervalle pour les valeurs de la série temporelles se comptent en jour (D pour day).
Finalement, on indique que les valeurs de la TimeSeries doivent être interprétées en float32 et qu’il faut trier les séries temporelles par magasins.
On peut afficher la première série temporelle de la première famille :
display(family_TS_dict['AUTOMOTIVE'][0])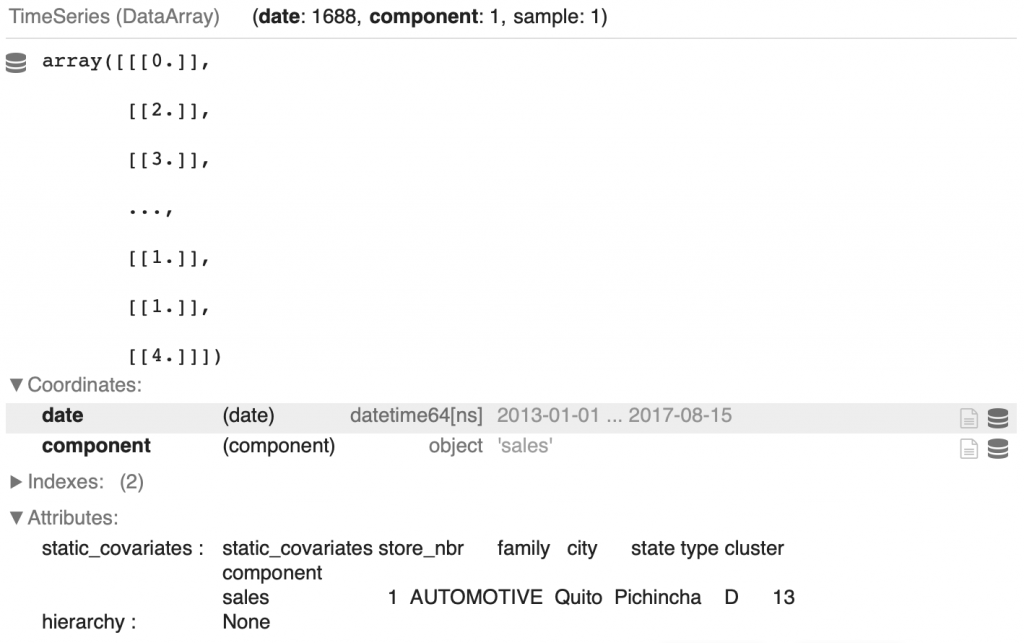
On retrouve l’ensemble des valeurs indiquées plus haut : le nombre de ventes, la date de chaque vente dans Coordinates > date, et les covariables dépendantes dans Attributes > static_covariates.
Tu peux aussi voir que la longeur de la série temporelle est de 1688. Originellement elle est de 1684 mais on a ajouté les valeurs des quatre 25 décembre absents du dataset.
Ensuite, on applique une normalisation à nos TimeSeries.
Normaliser les séries temporelles
La normalisation est une technique permettant d’améliorer les performances d’un modèle de Machine Learning en facilitant son entraînement. Je te laisse te référer à notre article sur le sujet si tu veux en savoir plus.
On peut normaliser facilement une TimeSeries avec la fonction Scaler de darts.
De plus, on va encore optimiser l’entraînement du modèle en one hot encodant nos covariables. On implémente le one hot encoding via la fonction StaticCovariatesTransformer.
from darts.dataprocessing import Pipeline
from darts.dataprocessing.transformers import Scaler, StaticCovariatesTransformer, MissingValuesFiller, InvertibleMapper
import sklearn
family_pipeline_dict = {}
family_TS_transformed_dict = {}
for key in family_TS_dict:
train_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs")
static_cov_transformer = StaticCovariatesTransformer(verbose=False, transformer_cat = sklearn.preprocessing.OneHotEncoder(), name="Encoder")
log_transformer = InvertibleMapper(np.log1p, np.expm1, verbose=False, n_jobs=-1, name="Log-Transform")
train_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaling")
train_pipeline = Pipeline([train_filler,
static_cov_transformer,
log_transformer,
train_scaler])
training_transformed = train_pipeline.fit_transform(family_TS_dict[key])
family_pipeline_dict[key] = train_pipeline
family_TS_transformed_dict[key] = training_transformedOn peut afficher la première TimeSeries transformée de la première famille :
display(family_TS_transformed_dict['AUTOMOTIVE'][0])Tu peux voir que les ventes ont été normalisées et que les static_covariates ont été one hot encodées.
On a maintenant nos séries temporelles principales qui vont nous permettre d’entraîner notre modèle.
Pourquoi ne pas étoffer notre dataset avec d’autres covariables ?
Covariables
Une covariable est une variable qui permet d’aider à la prédiction d’une variable cible.
Cette covariable peut être dépendante de la variable cible. Par exemple, le type de magasin, type, où sont réalisés les ventes. Mais elle peut aussi être indépendante. Par exemple, le prix de l’essence le jour de la vente d’un produit.
Cette covariable peut être connue à l’avance, par exemple dans notre dataset on a le prix de l’essence pour les dates du 1er janvier 2013 au 31 août 2017. Dans ce cas, on parle de covariable future.
Il y a aussi les covariables passées. Ce sont des covariables qui ne sont pas connues à l’avance. Par exemple dans notre dataset, les transactions sont connues pour les dates du 1er janvier 2013 au 15 août 2017.
Date
La première covariable qui nous intéresse est la date.
La date est une covariable future car on connaît la date des jours à venir.
Elle a, dans bien des cas, un impact sur le traffic d’un magasin. Par exemple, on peut s’attendre au fait que, le samedi, il y ait plus de clients dans le magasin que le lundi.
Mais on peut aussi s’attendre que pendant les vacances d’été le magasin soit moins fréquenté qu’en temps normal.
Ainsi chaque petits détails comptent.
Pour ne rien rater, on va extraire le plus d’informations possibles de cette date. Ici, 7 colonnes :
year– annéemonth– moisday– jourdayofyear– jour de l’année (par exemple le 1 février est le 32ème jour de l’année)weekday– le jour de la semaine (il y a 7 jours dans une semaine)weekofyear– la semaine de l’année (il y a 52 semaines dans une année)linear_increase– l’index de l’intervalle
from darts.utils.timeseries_generation import datetime_attribute_timeseries
full_time_period = pd.date_range(start='2013-01-01', end='2017-08-31', freq='D')
year = datetime_attribute_timeseries(time_index = full_time_period, attribute="year")
month = datetime_attribute_timeseries(time_index = full_time_period, attribute="month")
day = datetime_attribute_timeseries(time_index = full_time_period, attribute="day")
dayofyear = datetime_attribute_timeseries(time_index = full_time_period, attribute="dayofyear")
weekday = datetime_attribute_timeseries(time_index = full_time_period, attribute="dayofweek")
weekofyear = datetime_attribute_timeseries(time_index = full_time_period, attribute="weekofyear")
timesteps = TimeSeries.from_times_and_values(times=full_time_period,
values=np.arange(len(full_time_period)),
columns=["linear_increase"])
time_cov = year.stack(month).stack(day).stack(dayofyear).stack(weekday).stack(weekofyear).stack(timesteps)
time_cov = time_cov.astype(np.float32)Voilà ce que cela nous donne pour la date à l’index 100 :
display(print(time_cov.components.values))
display(time_cov[100])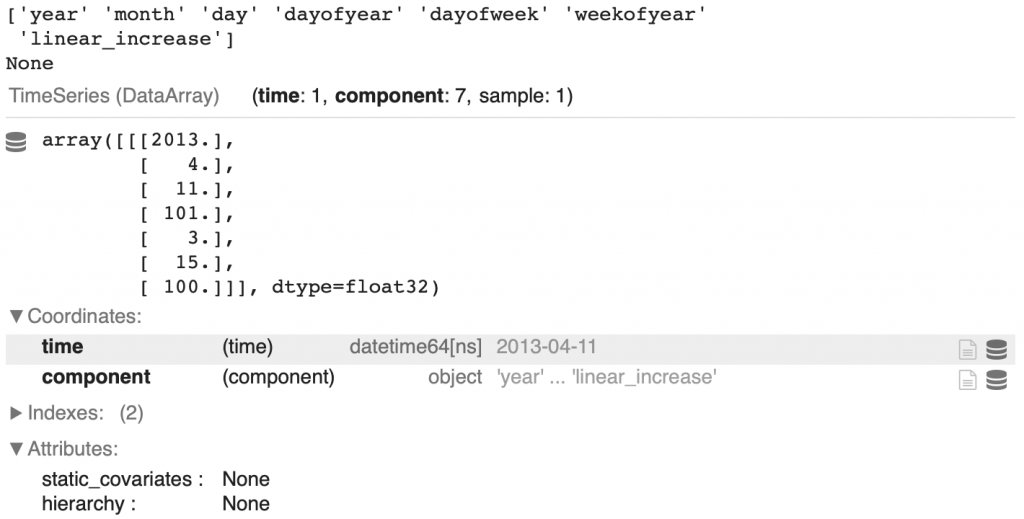
Et bien sûr, on va normaliser ces données :
time_cov_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler")
time_cov_train, time_cov_val = time_cov.split_before(pd.Timestamp('20170816'))
time_cov_scaler.fit(time_cov_train)
time_cov_transformed = time_cov_scaler.transform(time_cov)Tu peux aussi voir qu’on effectue un split entre les dates avant le 15 août 2017 et après (dates qui seront utilisées lors de la prédiction).
Oil – Prix de l’essence
Comme dit précédemment, le prix de l’essence est une covariable future car elle est connue en avance.
Ici, on ne va pas simplement extraire le prix de l’essence journalier mais on va calculer la moyenne mobile (moving average).
La moyenne mobile en X, est une moyenne de la valeur actuelle et des X-1 valeurs précédentes d’une série temporelle.
Par exemple la moyenne mobile en 7 est la moyenne de (t + t-1 + ... + t-6) / 7. Elle est calculée à chaque t, c’est pour cela qu’elle est dit « mobile ».
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Le fait de calculer la moyenne mobile permet de supprimer les fluctuations momentanées d’une valeur et permet ainsi d’accentuer les tendances à long termes.
La moyenne mobile est notamment utilisée dans le trading, mais plus généralement dans l’Analyse de Séries Temporelles.
Dans le code suivant, on calcule la moyenne mobile en 7 et en 28 du prix de l’essence. Et bien évidemment, on applique une normalisation :
from darts.models import MovingAverage
# Oil Price
oil = TimeSeries.from_dataframe(df_oil,
time_col = 'date',
value_cols = ['dcoilwtico'],
freq = 'D')
oil = oil.astype(np.float32)
# Transform
oil_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Filler")
oil_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler")
oil_pipeline = Pipeline([oil_filler, oil_scaler])
oil_transformed = oil_pipeline.fit_transform(oil)
# Moving Averages for Oil Price
oil_moving_average_7 = MovingAverage(window=7)
oil_moving_average_28 = MovingAverage(window=28)
oil_moving_averages = []
ma_7 = oil_moving_average_7.filter(oil_transformed).astype(np.float32)
ma_7 = ma_7.with_columns_renamed(col_names=ma_7.components, col_names_new="oil_ma_7")
ma_28 = oil_moving_average_28.filter(oil_transformed).astype(np.float32)
ma_28 = ma_28.with_columns_renamed(col_names=ma_28.components, col_names_new="oil_ma_28")
oil_moving_averages = ma_7.stack(ma_28)Voilà le résultat obtenu à l’index 100 :
display(oil_moving_averages[100])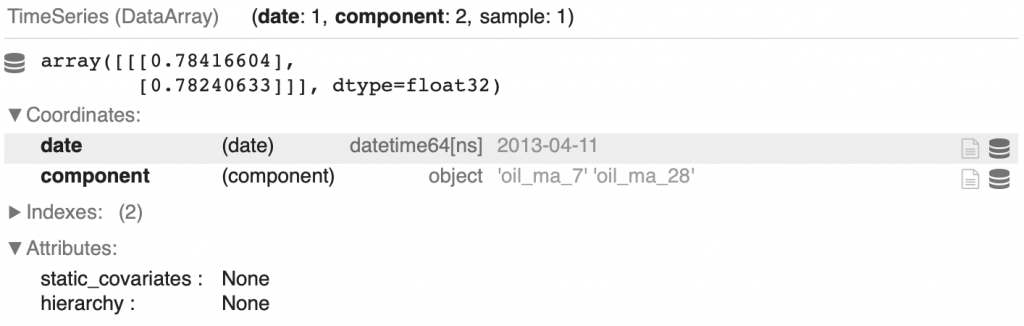
Holidays – Jours de fêtes
Attardons-nous maintenant sur les jours de fêtes.
Ici, Ferdinand Berr à implémenté des fonctions permettant de détailler ces fêtes. Notamment, il ajoute les informations qui permettent de savoir si le jour de fête est le jour de noël, si c’est un jour d’un match de football, etc :
def holiday_list(df_stores):
listofseries = []
for i in range(0,len(df_stores)):
df_holiday_dummies = pd.DataFrame(columns=['date'])
df_holiday_dummies["date"] = df_holidays_events["date"]
df_holiday_dummies["national_holiday"] = np.where(((df_holidays_events["type"] == "Holiday") & (df_holidays_events["locale"] == "National")), 1, 0)
df_holiday_dummies["earthquake_relief"] = np.where(df_holidays_events['description'].str.contains('Terremoto Manabi'), 1, 0)
df_holiday_dummies["christmas"] = np.where(df_holidays_events['description'].str.contains('Navidad'), 1, 0)
df_holiday_dummies["football_event"] = np.where(df_holidays_events['description'].str.contains('futbol'), 1, 0)
df_holiday_dummies["national_event"] = np.where(((df_holidays_events["type"] == "Event") & (df_holidays_events["locale"] == "National") & (~df_holidays_events['description'].str.contains('Terremoto Manabi')) & (~df_holidays_events['description'].str.contains('futbol'))), 1, 0)
df_holiday_dummies["work_day"] = np.where((df_holidays_events["type"] == "Work Day"), 1, 0)
df_holiday_dummies["local_holiday"] = np.where(((df_holidays_events["type"] == "Holiday") & ((df_holidays_events["locale_name"] == df_stores['state'][i]) | (df_holidays_events["locale_name"] == df_stores['city'][i]))), 1, 0)
listofseries.append(df_holiday_dummies)
return listofseriesEnsuite, on a une fonction pour supprimer les jours égale à 0 et les doublons :
def remove_0_and_duplicates(holiday_list):
listofseries = []
for i in range(0,len(holiday_list)):
df_holiday_per_store = list_of_holidays_per_store[i].set_index('date')
df_holiday_per_store = df_holiday_per_store.loc[~(df_holiday_per_store==0).all(axis=1)]
df_holiday_per_store = df_holiday_per_store.groupby('date').agg({'national_holiday':'max', 'earthquake_relief':'max',
'christmas':'max', 'football_event':'max',
'national_event':'max', 'work_day':'max',
'local_holiday':'max'}).reset_index()
listofseries.append(df_holiday_per_store)
return listofseriesEt finalement une fonction qui nous permet d’avoir les jours de fête associés à chacun des 54 magasins :
def holiday_TS_list_54(holiday_list):
listofseries = []
for i in range(0,54):
holidays_TS = TimeSeries.from_dataframe(list_of_holidays_per_store[i],
time_col = 'date',
fill_missing_dates=True,
fillna_value=0,
freq='D')
holidays_TS = holidays_TS.slice(pd.Timestamp('20130101'),pd.Timestamp('20170831'))
holidays_TS = holidays_TS.astype(np.float32)
listofseries.append(holidays_TS)
return listofseriesIl ne nous reste plus qu’à appliquer ces fonctions :
list_of_holidays_per_store = holiday_list(df_stores)
list_of_holidays_per_store = remove_0_and_duplicates(list_of_holidays_per_store)
list_of_holidays_store = holiday_TS_list_54(list_of_holidays_per_store)
holidays_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Filler")
holidays_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler")
holidays_pipeline = Pipeline([holidays_filler, holidays_scaler])
holidays_transformed = holidays_pipeline.fit_transform(list_of_holidays_store)On obtient 54 TimeSeries avec 7 colonnes :
national_holiday– fête nationaleearthquake_relief– tremblement de terrechristmas– jour de noëlfootball_event– match de footballnational_event– événement nationalwork_day– jour de travaillocal_holiday– fête locale
Voilà l’index 100 de la TimeSeries pour le premier magasin :
display(len(holidays_transformed))
display(holidays_transformed[0].components.values)
display(holidays_transformed[0][100])Promotion
La dernière covariable future à traiter et la colonne onpromotion.
Elle permet de connaître le nombre d’objet en promotion dans une famille de produits.
Ici le code est similaire à celui utilisé pour la colonne sales. Il permet d’extraire pour chaque famille, les séries temporelles des 54 magasins :
df_promotion = pd.concat([df_train, df_test], axis=0)
df_promotion = df_promotion.sort_values(["store_nbr","family","date"])
df_promotion.tail()
family_promotion_dict = {}
for family in family_list:
df_family = df_promotion.loc[df_promotion['family'] == family]
list_of_TS_promo = TimeSeries.from_group_dataframe(
df_family,
time_col="date",
group_cols=["store_nbr","family"],
value_cols="onpromotion",
fill_missing_dates=True,
freq='D')
for ts in list_of_TS_promo:
ts = ts.astype(np.float32)
family_promotion_dict[family] = list_of_TS_promoOn peut afficher la première TimeSeries de la première famille :
display(family_promotion_dict['AUTOMOTIVE'][0])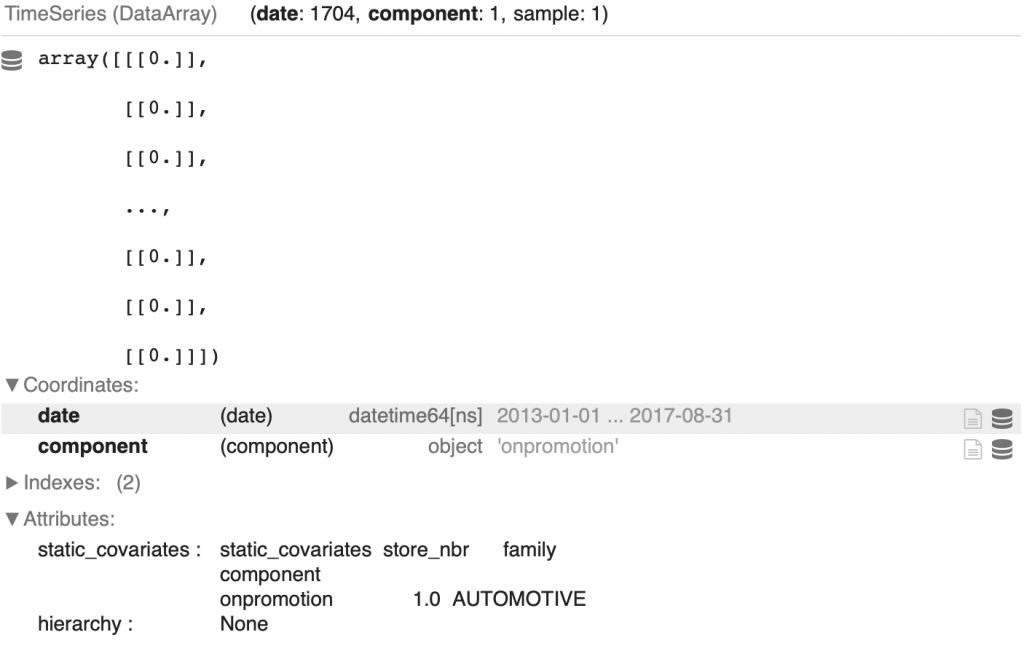
Allons plus loin en calculant aussi la moyenne mobile en 7 et en 28, comme pour le prix de l’essence :
from tqdm import tqdm
promotion_transformed_dict = {}
for key in tqdm(family_promotion_dict):
promo_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs")
promo_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaling")
promo_pipeline = Pipeline([promo_filler,
promo_scaler])
promotion_transformed = promo_pipeline.fit_transform(family_promotion_dict[key])
# Moving Averages for Promotion Family Dictionaries
promo_moving_average_7 = MovingAverage(window=7)
promo_moving_average_28 = MovingAverage(window=28)
promotion_covs = []
for ts in promotion_transformed:
ma_7 = promo_moving_average_7.filter(ts)
ma_7 = TimeSeries.from_series(ma_7.pd_series())
ma_7 = ma_7.astype(np.float32)
ma_7 = ma_7.with_columns_renamed(col_names=ma_7.components, col_names_new="promotion_ma_7")
ma_28 = promo_moving_average_28.filter(ts)
ma_28 = TimeSeries.from_series(ma_28.pd_series())
ma_28 = ma_28.astype(np.float32)
ma_28 = ma_28.with_columns_renamed(col_names=ma_28.components, col_names_new="promotion_ma_28")
promo_and_mas = ts.stack(ma_7).stack(ma_28)
promotion_covs.append(promo_and_mas)
promotion_transformed_dict[key] = promotion_covsOn obtient une série temporelle normalisée avec 3 colonnes.
On peut afficher l’index 1 de la première TimeSeries de la première famille :
display(promotion_transformed_dict['AUTOMOTIVE'][0].components.values)
display(promotion_transformed_dict['AUTOMOTIVE'][0][1])Regrouper les covariables
Pour finir avec les covariables futures, on va les rassembler dans une même TimeSeries.
On commence avec les séries temporelles des dates, du prix de l’essence et des moyennes mobiles du prix de l’essence qu’on regroupe dans la variable general_covariates :
general_covariates = time_cov_transformed.stack(oil_transformed).stack(oil_moving_averages)Puis pour chaque magasin, on assemble les TimeSeries des jours de fêtes avec la general_covariates :
store_covariates_future = []
for store in range(0,len(store_list)):
stacked_covariates = holidays_transformed[store].stack(general_covariates)
store_covariates_future.append(stacked_covariates)Finalement pour chaque famille, on assemble les covariables précédemment créées aux covariables de promotion :
future_covariates_dict = {}
for key in tqdm(promotion_transformed_dict):
promotion_family = promotion_transformed_dict[key]
covariates_future = [promotion_family[i].stack(store_covariates_future[i]) for i in range(0,len(promotion_family))]
future_covariates_dict[key] = covariates_futureVoilà les différentes colonnes obtenues pour chaque TimeSeries de chaque famille de chaque magasin :
display(future_covariates_dict['AUTOMOTIVE'][0].components)Sortie : ['onpromotion', 'promotion_ma_7', 'promotion_ma_28', 'national_holiday', 'earthquake_relief', 'christmas', 'football_event', 'national_event', 'work_day', 'local_holiday', 'year', 'month', 'day', 'dayofyear', 'dayofweek', 'weekofyear', 'linear_increase', 'dcoilwtico', 'oil_ma_7', 'oil_ma_28']
Transactions – Covariables Passées
Avant de lancer l’entraînement du modèle, je te propose d’extraire les covariables passées : les transactions.
Tu l’auras compris, après avoir prélever les transactions pour chaque magasin, on va les normaliser :
df_transactions.sort_values(["store_nbr","date"], inplace=True)
TS_transactions_list = TimeSeries.from_group_dataframe(
df_transactions,
time_col="date",
group_cols=["store_nbr"],
value_cols="transactions",
fill_missing_dates=True,
freq='D')
transactions_list = []
for ts in TS_transactions_list:
series = TimeSeries.from_series(ts.pd_series())
series = series.astype(np.float32)
transactions_list.append(series)
transactions_list[24] = transactions_list[24].slice(start_ts=pd.Timestamp('20130102'), end_ts=pd.Timestamp('20170815'))
from datetime import datetime, timedelta
transactions_list_full = []
for ts in transactions_list:
if ts.start_time() > pd.Timestamp('20130101'):
end_time = (ts.start_time() - timedelta(days=1))
delta = end_time - pd.Timestamp('20130101')
zero_series = TimeSeries.from_times_and_values(
times=pd.date_range(start=pd.Timestamp('20130101'),
end=end_time, freq="D"),
values=np.zeros(delta.days+1))
ts = zero_series.append(ts)
ts = ts.with_columns_renamed(col_names=ts.components, col_names_new="transactions")
transactions_list_full.append(ts)
transactions_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Filler")
transactions_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler")
transactions_pipeline = Pipeline([transactions_filler, transactions_scaler])
transactions_transformed = transactions_pipeline.fit_transform(transactions_list_full)Voilà la TimeSeries pour le premier magasin :
display(transactions_transformed[0])On est fin prêt à créer notre modèle de Machine Learning.
Modèle de Machine Learning
À présent, nous allons entraîner un premier modèle de Machine Learning avec la librairie darts pour confirmer que nos données sont conformes et que les prédictions obtenues sont convaincantes.
Ensuite nous utiliserons les méthodes d’ensembles pour améliorer notre résultat final.
Un seul modèle
La librairie Darts nous offrent de nombreux modèle de Machine Learning à utiliser sur les TimeSeries.
Dans la solution de Ferdinand Berr, on peut voir qu’il utilise différents modèles :
NHiTSModel– score : 0.43265RNNModel(avec couches LSTM) – score : 0.55443TFTModel– score : 0.43226ExponentialSmoothing– score : 0.37411
Ces scores sont obtenues sur des données de validation, artificiellement générées à partir des données d’entraînement.
Personnellement, j’ai décidé d’utiliser le modèle LightGBMModel, une implémentation du modèle de la libraire éponyme sur laquelle tu retrouveras un article ici.
Pourquoi utiliser ce modèle ? Non pas après des heures de pratiques et d’expériences, mais simplement en l’utilisant et en constant que, seul, il me donne de meilleurs résultat que le ExponentialSmoothing.
Comme expliqué dans la partie Stratégie, on va entraîner un modèle de Machine Learning par famille de produits.
Il faut donc pour chaque famille, prendre les TimeSeries correspondantes et les envoyer à notre modèle de Machine Learning.
Tout d’abord, on prépare les données :
TCN_covariatesreprésente les covariables futures associées à la famille de produits cibletrain_slicedreprésente le nombre de ventes associés à la famille de produits cible. La fonctionslice_intersectque tu peux voir utilisée nous assure simplement que lescomponentss’étendent sur le même intervalle de temps. Dans le cas d’intervalles de temps différents un message d’erreur apparaîtra si nous essayons de les combiner.transactions_transformed, les covariables passées n’ont pas besoin d’être indéxées sur la famille cible car il n’y a qu’une seuleTimeSeriesglobale par magasin
Ensuite, on initialise des hyperparamètres pour notre modèle.
C’est là que tout se joue.
En modifiant ces hyperparamètres tu pourras améliorer les performances du modèle de Machine Learning.
Entraîner
Voilà les hyperparamètres importants :
lags– les nombre de valeurs passées sur lequel on se base pour effectuer nos prédictionslags_future_covariates– le nombre de valeurs des covariables futures sur lequel on se base pour effectuer nos prédictions. Si on donne un tuple, la valeur de gauche représente le nombre de covariables dans le passé et la valeur de droite, le nombre de covariables dans le futurlags_past_covariates– le nombre de valeurs des covariables passées sur lequel on se base pour effectuer nos prédictions
Pour ces trois hyperparamètres, si une liste est passées, on prend les index associées aux chiffres de cette liste. Par exemple si on passe : [-3, -4, -5], on prendre les index t-3, t-4, t-5. Mais si on passe un entier par exemple 10, on prend les 10 valeurs précédentes (ou les 10 valeurs futures selon le cas).
Les hyperparamètres output_chunk_length contrôle le nombre de valeurs prédites dans le futur, random_state permet d’assurer la reproductibilité des résultats et gpu_use_dp indique si l’on souhaite utiliser un GPU.
Ensuite on lance l’entraînement. Puis, à sa fin, on enregistre le modèle entraîné dans un dictionnaire.
from darts.models import LightGBMModel
LGBM_Models_Submission = {}
display("Training...")
for family in tqdm(family_list):
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
TCN_covariates = future_covariates_dict[family]
train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]
LGBM_Model_Submission = LightGBMModel(lags = 63,
lags_future_covariates = (14,1),
lags_past_covariates = [-16,-17,-18,-19,-20,-21,-22],
output_chunk_length=1,
random_state=2022,
gpu_use_dp= "false",
)
LGBM_Model_Submission.fit(series=train_sliced,
future_covariates=TCN_covariates,
past_covariates=transactions_transformed)
LGBM_Models_Submission[family] = LGBM_Model_SubmissionDans le code ci-dessus, on se base uniquement sur lags_past_covariates = [-16,-17,-18,-19,-20,-21,-22], pourquoi ? Car lors de la 16ème prédiction (celle du 31 août 2017), les valeurs des covariables passées de -1 à -15 ne sont pas connue.
Après l’entraînement, on obtient 33 modèles de Machine Learning stockées dans LGBM_Models_Submission.
Prédire
On peux maintenant effectuer les prédictions :
display("Predictions...")
LGBM_Forecasts_Families_Submission = {}
for family in tqdm(family_list):
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
LGBM_covariates = future_covariates_dict[family]
train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]
forecast_LGBM = LGBM_Models_Submission[family].predict(n=16,
series=train_sliced,
future_covariates=LGBM_covariates,
past_covariates=transactions_transformed)
LGBM_Forecasts_Families_Submission[family] = forecast_LGBMRemarque : même si le modèle à un output_chunk_length de 1, on peut directement lui indiquer de prédire 16 valeurs dans le futur.
On a maintenant nos prédictions. Si tu suis bien, tu connais l’étape suivante.
Précédemment, on a normaliser nos données avec la fonction Scaler. Ainsi les données prédites sont elles aussi normaliser.
Pour les dé-normaliser on utilise la fonction inverse_transform sur chaque TimeSeries :
LGBM_Forecasts_Families_back_Submission = {}
for family in tqdm(family_list):
LGBM_Forecasts_Families_back_Submission[family] = family_pipeline_dict[family].inverse_transform(LGBM_Forecasts_Families_Submission[family], partial=True)Finalement voilà le code qui permet de passer de l’amas de série temporelle prédites au DataFrame de prédiction :
for family in tqdm(LGBM_Forecasts_Families_back_Submission):
for n in range(0,len(LGBM_Forecasts_Families_back_Submission[family])):
if (family_TS_dict[family][n].univariate_values()[-21:] == 0).all():
LGBM_Forecasts_Families_back_Submission[family][n] = LGBM_Forecasts_Families_back_Submission[family][n].map(lambda x: x * 0)
listofseries = []
for store in tqdm(range(0,54)):
for family in family_list:
oneforecast = LGBM_Forecasts_Families_back_Submission[family][store].pd_dataframe()
oneforecast.columns = ['fcast']
listofseries.append(oneforecast)
df_forecasts = pd.concat(listofseries)
df_forecasts.reset_index(drop=True, inplace=True)
# No Negative Forecasts
df_forecasts[df_forecasts < 0] = 0
forecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)
forecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=['id'])
forecasts_kaggle_sorted = forecasts_kaggle_sorted.drop(['date','store_nbr','family'], axis=1)
forecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})
forecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)
# Submission
submission_kaggle = forecasts_kaggle_sortedOn peut afficher les prédictions :
submission_kaggle.head()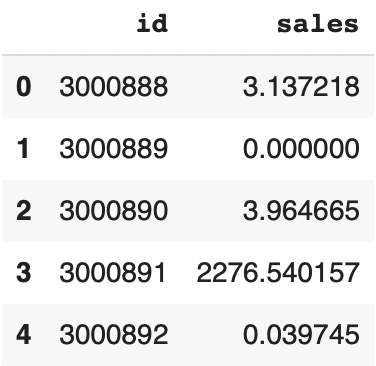
Mais ce n’est pas fini ! ☝🏻
Il nous faut maintenant entraîner plusieurs modèles et appliquer la méthode d’Ensemble.
Plusieurs modèles
Comme expliqué précédemment, l’important dans ce code, ce sont les hyperparamètres. On va entraîner 3 modèles en prenant les hyperparamètres suivants :
model_params = [
{"lags" : 7, "lags_future_covariates" : (16,1), "lags_past_covariates" : [-16,-17,-18,-19,-20,-21,-22]},
{"lags" : 365, "lags_future_covariates" : (14,1), "lags_past_covariates" : [-16,-17,-18,-19,-20,-21,-22]},
{"lags" : 730, "lags_future_covariates" : (14,1), "lags_past_covariates" : [-16,-17,-18,-19,-20,-21,-22]}
]Pour chacun de ces paramètres, on va entraîner 33 modèles, lancer les prédictions et remplir le DataFrame final. Les 3 DataFrames obtenues seront stockés dans la liste submission_kaggle_list :
from sklearn.metrics import mean_squared_log_error as msle, mean_squared_error as mse
from lightgbm import early_stopping
submission_kaggle_list = []
for params in model_params:
LGBM_Models_Submission = {}
display("Training...")
for family in tqdm(family_list):
# Define Data for family
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
TCN_covariates = future_covariates_dict[family]
train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]
LGBM_Model_Submission = LightGBMModel(lags = params["lags"],
lags_future_covariates = params["lags_future_covariates"],
lags_past_covariates = params["lags_past_covariates"],
output_chunk_length=1,
random_state=2022,
gpu_use_dp= "false")
LGBM_Model_Submission.fit(series=train_sliced,
future_covariates=TCN_covariates,
past_covariates=transactions_transformed)
LGBM_Models_Submission[family] = LGBM_Model_Submission
display("Predictions...")
LGBM_Forecasts_Families_Submission = {}
for family in tqdm(family_list):
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
LGBM_covariates = future_covariates_dict[family]
train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]
forecast_LGBM = LGBM_Models_Submission[family].predict(n=16,
series=train_sliced,
future_covariates=LGBM_covariates,
past_covariates=transactions_transformed)
LGBM_Forecasts_Families_Submission[family] = forecast_LGBM
# Transform Back
LGBM_Forecasts_Families_back_Submission = {}
for family in tqdm(family_list):
LGBM_Forecasts_Families_back_Submission[family] = family_pipeline_dict[family].inverse_transform(LGBM_Forecasts_Families_Submission[family], partial=True)
# Prepare Submission in Correct Format
for family in tqdm(LGBM_Forecasts_Families_back_Submission):
for n in range(0,len(LGBM_Forecasts_Families_back_Submission[family])):
if (family_TS_dict[family][n].univariate_values()[-21:] == 0).all():
LGBM_Forecasts_Families_back_Submission[family][n] = LGBM_Forecasts_Families_back_Submission[family][n].map(lambda x: x * 0)
listofseries = []
for store in tqdm(range(0,54)):
for family in family_list:
oneforecast = LGBM_Forecasts_Families_back_Submission[family][store].pd_dataframe()
oneforecast.columns = ['fcast']
listofseries.append(oneforecast)
df_forecasts = pd.concat(listofseries)
df_forecasts.reset_index(drop=True, inplace=True)
# No Negative Forecasts
df_forecasts[df_forecasts < 0] = 0
forecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)
forecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=['id'])
forecasts_kaggle_sorted = forecasts_kaggle_sorted.drop(['date','store_nbr','family'], axis=1)
forecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})
forecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)
# Submission
submission_kaggle_list.append(forecasts_kaggle_sorted)On se retrouve avec quatre DataFrame de prédiction qu’on va additionner et moyenner (c’est la fameuse méthode d’ensemble) :
df_sample_submission['sales'] = (submission_kaggle[['sales']]+submission_kaggle_list[0][['sales']]+submission_kaggle_list[1][['sales']]+submission_kaggle_list[2][['sales']])/4Voilà le résultat obtenu :
df_sample_submission.head()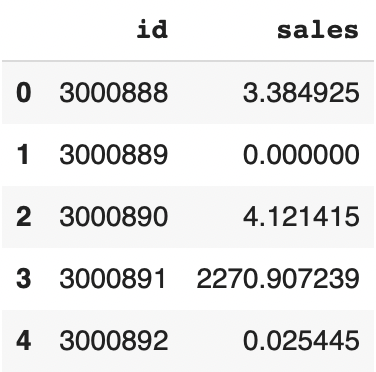
Tu peux maintenant sauvegarder les prédictions dans un fichier CSV et le soumettre à Kaggle :
df_sample_submission.to_csv('submission.csv', index=False)N’hésite pas à tweaker les hyperparamètres pour améliorer le modèle.
Si ce tutoriel t’as plu, tu peux mettre un like sur mon notebook Kaggle, cela m’aidera grandement !
À bientôt sur Inside Machine Learning ! 😉
top 1 kaggle top 1 kaggle top 1 kaggle top 1 kaggle top 1 kaggle top 1 kaggle top 1 kaggle top 1 kaggle top 1 kaggle
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



