

La Featurization est une technique pour améliorer son modèle de Machine Learning. Elle permet d’ajouter des données à notre dataset.
À la base la Featurization est un synonyme de Feature Engineering, un concept sur lequel on a déjà fait un article détaillé.
Pour faire simple le Feature Engineering est un autre mot pour parler de Preprocessing.
Le preprocessing c’est toutes les techniques utilisées pour transformer nos données.
À la suite du preprocessing, on peut entraîner un modèle de Machine Learning.
Un exemple de preprocessing est le suivant : transformer des données textes au format numérique.
Ok donc :
Featurization = Feature Engineering = Preprocessing
Le problème : plus personne n’utilise le mot Featurization.
Il a été oublié depuis quelques années (j’ai seulement trouvé 4 articles à ce sujet sur internet).
À tel point que le mot Featurization a changé de sens.
En participant à des compétitions Kaggle, je l’ai vu employé par plusieurs experts.
Featurization fait maintenant référence à une technique bien précise.
La Featurization, c’est quoi ?
Vu qu’il n’y a pas vraiment de définition voilà celle que je propose:
La Featurization est l’ensemble des techniques misent en place pour obtenir de nouvelles informations via des données pré-existantes dans un dataset.
Un exemple simple:
- Un dataset regroupe les parties de joueur de Scrabble avec deux colonnes : le niveau de difficulté et le résultat du match (victoire ou non)
- Le but est de prédire le score du joueur
Dans ce cas, un exemple de Featurization serait d’ajouter une troisième colonnes Nombre de Victoire nous permettant de savoir si le joueur a été bon lors de ses précédentes parties :
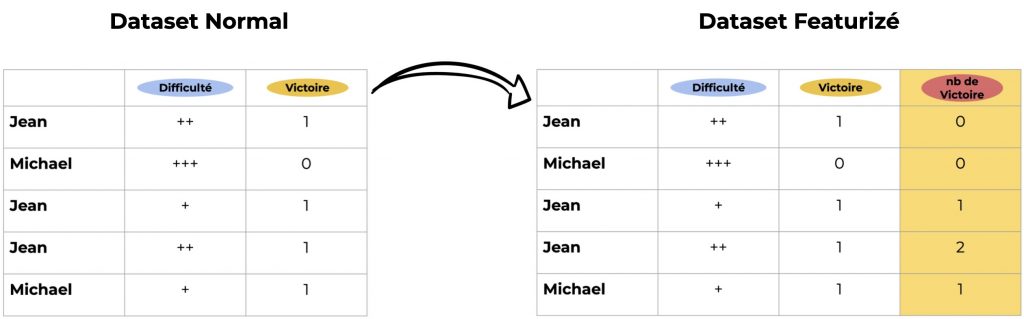
La Featurization tire parti des données pré-existantes pour ajouter de la valeur au dataset.
Ainsi, je considère la Featurization comme une sorte de Data Augmentation.
Le but final de cette technique est évidemment d’améliorer la performance du modèle de Machine Learning.
Gardons néanmoins à l’esprit que la Data Augmentation permet d’ajouter des lignes à notre dataset alors qu’ici, on ajoute des colonnes.
Assez de blabla. Passons à la pratique !
Dataset
Dans ce tutoriel on va prendre une version simplifié du dataset de la compétition Kaggle : Scrabble Player Rating
Le but est de prédire le score d’un joueur lors d’un match de scrabble.
Chaque ligne représente un match contre un robot.
On a 11 colonnes :
- nickname – le nom du joueur
- score – le score du joueur à la fin du match
- rating – note sur woogles.io AVANT que le jeu ne soit joué (la colonne à prédire)
- bot_name – le nom du bot contre qui le joueur à joué
- bot_score – le score du bot à la fin du match
- bot_rating – note du bot sur woogles.io AVANT que le jeu ne soit joué
- game_end_reason – comment le jeu s’est terminé
- winner – le gagnant, 0 si le joueur et 1 si le robot
- created_at – la date du match
- game_duration_seconds – la durée du match en seconde
On commence par importer les datasets que j’ai stocké sur github :
!git clone https://github.com/tkeldenich/datasets.gitEnsuite tu peux ouvrir le dataset qui nous intéresse avec la librairie pandas :
import pandas as pd
df = pd.read_csv('/content/datasets/simplified-scrabble-player-rating.csv', index_col='game_id')
df.head()
On va s’occuper rapidement du preprocessing étant donné que ce n’est pas le sujet principal de l’article.
Ici, on a seulement besoin de transformer nos données catégoriques texte en données catégoriques numérique.
Preprocessing
Pour ça on utilise la librairie category_encoders qui nous facilite grandement la tâche :
!pip install category_encodersAvec on peut transformer les données catégoriques comme la colonne game_end_reason.
Elle comporte 4 catégories :
df.game_end_reason.unique()Output: ‘STANDARD’, ‘RESIGNED’, ‘TIME’, ‘CONSECUTIVE_ZEROES’
À la place de ces données textuels, on aura uniquement des chiffres : 1,2,3,4. Sans quoi on ne pourrait entraîner de modèle de Machine Learning.
On utilise la fonction OrdinalEncoder qui encode toutes nos catégories en données numérique.
ATTENTION, ce n’est pas parce que tu sais qu’il y a des données catégoriques dans ton dataset que Python les a détecté. Pour voir s’il a reconnu tes données utilise df.types, les colonnes catégoriques devraient être noté « category » ou « object« .
On voit qu’il y a un problème. Nos catégories ont bien le type « object » mais la colonne created_at aussi.
Ce n’est pas bon. Si on laisse le dataset comme cela, toutes nos données created_at seront transformé en simple chiffre.
Pour contrer cela , on indique à Python que notre colonne est de type « datetime » :
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
df['created_at'] = pd.to_datetime(df['created_at'])On peut maintenant utiliser la fonction OrdinalEncoder sur l’entièreté de notre dataset.
Il va détecter les « object » et les transformer en chiffres :
import category_encoders as ce
X = df.copy()
X = ce.OrdinalEncoder().fit_transform(X).drop("rating", axis=1)
y = df["rating"]On check que tout est ok :
X.head()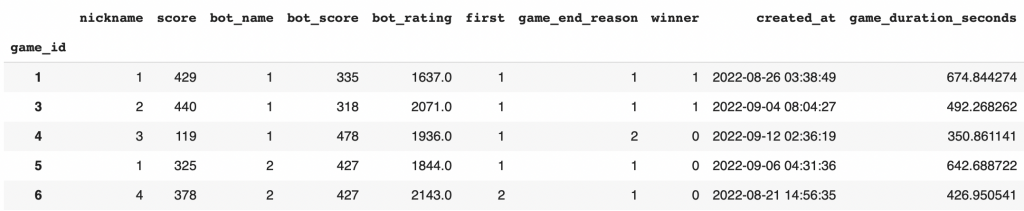
Et on peut passer à la suite !
Entraînement sans Featurization
Dans cette partie, on va entraîner un modèle de Machine Learning sans Featurization.
Cela nous permettra de voir la différence lorsqu’on utilisera la technique.
On choisis notre modèle depuis la librairie lightgbm (Light Gradient Boosting Machines):
from lightgbm import LGBMRegressor
model = LGBMRegressor(n_estimators=1000, verbose=-1, random_state=42)Ensuite, on sépare notre dataset entre données d’entraînement et données de test :
X_train = X[:int(len(X)*0.8)].drop('created_at',axis=1)
X_valid = X[int(len(X)*0.8):].drop('created_at',axis=1)
y_train = y[:int(len(X)*0.8)]
y_valid = y[int(len(X)*0.8):]Je précise que la colonne created_at ne va pas nous servir pour l’entraînement. On ne peut pas l’utiliser car cette colonne ne contient pas que des chiffres. Elle nous servira néanmoins pour la Featurization.
On entraîne le modèle:
model.fit(X_train,y_train)Puis on calcule le score final:
model.score(X_valid,y_valid)Output: 0.898
La précision est de 89% ce qui est déjà très bon!
Notre objectif maintenant est d’utiliser la Featurization pour augmenter ce score.
Note pour les mathématiciens curieux: pour calculer la précision dans une régression, on utilise le coefficient de détermination.
Featurization
On arrive à le technique tant attendue : la Featurization.
L’objectif de la Featurization est d’ajouter de l’information à notre dataset pour l’enrichir.
Ici je vous propose d’ajouter la colonne : Nombre de victoire du joueur.
Je rappelle que chaque ligne correspond au match d’un joueur contre un robot. On aura ici une nouvelle colonne correspondante au nombre de victoire du joueur en question.
La colonne created_at, nous permet d’avoir la date de chaque match et la colonne winner nous permet de savoir qui est le gagnant.
Avec la Featurization, on fusionne les informations de ces deux colonnes pour en créer une nouvelle. Cela permet de créer de l’information que l’on n’aurait pas eu auparavant.
Dans notre cas on obtient le nombre de victoire du joueur lors du match actuel.
Voilà la fonction pour créer la colonne qu’on appelle cumm_player_wins :
import numpy as np
def create_cumm_player_wins(df):
df = df[["nickname", "created_at","winner"]]
df= df.sort_values(by="created_at")
df["cumm_player_wins"] = np.zeros(len(df))
for nickname in df["nickname"].unique():
df.loc[df["nickname"]==nickname, "cumm_player_wins"]= np.append(0, df[df["nickname"]==nickname]["winner"].expanding(min_periods=1).sum().values[:-1])
df[["cumm_player_wins"]] = df[["cumm_player_wins"]].fillna(0)
df = df.sort_index()
return df[["cumm_player_wins"]]Ici on utilise la fonction avec create_cumm_player_wins(X.copy()) tout en ajoutant la colonne nouvellement créer dans X avec X.join() :
X_featurize = X.join(create_cumm_player_wins(X.copy()))On peut afficher le résultat :
X_featurize.head()
Et finalement, on reprend le même process que tout à l’heure en séparant nos données entre train et validation :
X_featurize_train = X_featurize[:int(len(X)*0.8)].drop('created_at',axis=1)
X_featurize_valid = X_featurize[int(len(X)*0.8):].drop('created_at',axis=1)
y_train = y[:int(len(X)*0.8)]
y_valid = y[int(len(X)*0.8):]On initialise le modèle :
model = LGBMRegressor(n_estimators=1000, verbose=-1, random_state=42)On l’entraîne :
model.fit(X_featurize_train,y_train)Et on calcule le score :
model.score(X_featurize_valid,y_valid)Output: 0.923
On obtient une précision de 92.3% !
C’est une augmentation de 3% par rapport au dernier modèle, c’est énorme !
À vous d’utiliser la Featurization dans vos propres projets maintenant.
Et si vous voulez ENCORE augmenter votre précision, d’autres techniques existent!
Voilà nos articles qui les présentent :
- Normaliser nos données
- La Cross-Validation
- Changer les hyperparamètres des modèles
- Les méthodes d’ensemble
À bientôt sur Inside Machine Learning 😉
sources :
- Full Walkthrough (EDA + FE + Model Tuning) – Iain Cruickshank
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



