

Dans cet article, nous allons voir comment utiliser Hugging Face et la bibliothèque 🤗 Transformers, et notamment les pipelines.
Avec plus de 1 million de modèles hébergés, Hugging Face est LA plateforme réunissant les praticiens de l’Intelligence Artificielle.
Sa librairie 🤗 Transformers donne accès de manière simplifiée à des modèles de type transformer – entrainé par des experts.
Ainsi, débutants, professionnels et chercheurs peuvent aisément utiliser des modèles de pointe dans leur projet.
Dans un précédent article, tu as pu en savoir plus sur Hugging Face ainsi que sa bibliothèque 🤗 Transformers. Nous avons ainsi exploré le but de l’entreprise et la plus-value qu’elle apporte dans le domaine de l’IA.
Aujourd’hui, tu va découvrir comment utiliser concrètement la bibliothèque 🤗 Transformers grâce aux pipelines.
Les Pipelines – Comment utiliser Hugging Face 🤗 Transformers
Définition
Un pipeline dans 🤗 Transformers désigne un processus où plusieurs étapes sont suivies dans un ordre précis pour obtenir une prédiction à partir d’un modèle.
Glossaire
Ces étapes peuvent inclure la préparation des données, l’extraction de features et la normalisation.
Tu peux le considérer comme une boîte à outils 🛠️ qui automatise les tâches complexes pour toi.
Le principal avantage du pipeline est sa simplicité d’utilisation. Il ne nécessite qu’une ligne de code pour être chargé et une autre ligne de code pour être utilisé.
🤗 Transformers offre une API claire et intuitive. Ainsi, même si tu n’es pas un expert en Machine Learning, tu peux utiliser ces modèles de pointe.
Tu pourras ainsi résoudre des tâches variées comme la reconnaissance d’entités nommées (NER), l’analyse de sentiment, la détection d’objets, et bien d’autres.
Le pipeline est une abstraction, c’est-à-dire que, même si, en surface, tu n’utilises qu’une ligne de code, en profondeur, de nombreux leviers seront actionnés.
Selon les paramètres que tu sélectionneras, le pipeline utilisera TensorFlow, PyTorch ou JAX pour construire et mettre à ta disposition un modèle.
Je te conseille d’ailleurs ce super article (en anglais) si tu souhaites approfondir le sujet.
En parlant de code et de paramètres, rentrons un peu plus en détails dans les pipelines.
Importation – Comment utiliser Hugging Face 🤗 Transformers
Pour installer la librairie 🤗 Transformers, il suffit d’utiliser la commande suivante dans ton terminal :
pip install transformersRemarque: si tu travailles directement sur un notebook, tu peux utiliser !pip install transformers pour installer la librairie depuis ton environnement.
Une fois la librairie installée, voilà comment importer un pipeline en Python :
from transformers import pipelinePour l’utiliser, il te suffit d’appeler pipeline() en indiquant les paramètres souhaités entre les parenthèses.
La première chose à noter est que tu peux spécifier la tâche que tu souhaites accomplir en utilisant le paramètre task.
Tu peux simplement choisir la tâche qui t’intéresse, et le pipeline fera le reste pour toi.
Remarque: on plonge en détail dans les différentes tâches réalisables par le pipeline dans les parties suivantes de cet article.
En plus, de task, d’autres paramètres peuvent être modulés pour adapter le pipeline à tes besoins.
Choix des paramètres – Comment utiliser Hugging Face 🤗 Transformers
🤗 Transformers te donne la flexibilité de choisir le modèle que tu souhaites utiliser.
Si tu as une préférence, tu peux l’indiquer grâce au paramètres model. Si tu n’en spécifies pas, le pipeline utilisera automatiquement le modèle par défaut pour la tâche sélectionnée.
Le paramètre config te permet de personnaliser la configuration du modèle. Par exemple, pour des modèles génération de texte, il est possible de régler le nombre de caractères maximum générés.
Le paramètre tokenizer, utilisé lors de tâches de NLP, et feature_extractor, utilisé lors de tâches de vision par ordinateur et lors de tâches multimodales, gèrent l’encodage des données. Encore une fois, si tu ne spécifies rien, le pipeline choisira automatiquement les valeurs par défaut appropriées.
Le choix du framework, que ce soit PyTorch framework=pt ou TensorFlow framework=tf, est également pris en charge.
En plus de ces paramètres clés, le pipeline de 🤗 Transformers offre plusieurs options annexes pour personnaliser ton utilisation.
Par exemple, le paramètre device permet de définir le processeur sur lequel le pipeline sera exécuté: CPU ou GPU.
En utilisant ces paramètres, tu peux adapter facilement le pipeline de 🤗 Transformers à tes besoins spécifique.
Cela rend l’accès à des modèles de pointe pour une variété de tâches plus ouvert que jamais.
À présent que nous avons vu les principaux paramètres de pipeline, voyons concrètement comment utiliser cette classe sur des tâches de :
- Natural Language Processing
- Computer Vision
- Traitement Audio
- Multi-Modal
Natural Language Processing
Une multitude de tâches
Le Natural Language Processing est le traitement de texte par Intelligence Artificielle.
Grâce aux pipelines de 🤗 Transformers on peut réaliser une multitude de tâches dans ce domaine:
conversational: communication textuelle avec des agents virtuels ou des chatbotsfill-mask: remplacement de « masques » par des mots ou des phrases dans un texte pour compléter ou générer du contenuner: Named Entity Recognition – identification et classification des entités nommées (comme les noms de personnes, d’organisations ou de lieux) dans un textequestion-answering: réponse à des questions textuel en extrayant des informations à partir d’un texte donnésummarization: réduction de la longueur d’un texte tout en préservant les informations pertinentes pour créer un résumé concistable-question-answering: réponse à des questions en utilisant des données tabulaires en tant que source d’informationtext2text-generation: génération de texte à partir d’un texte source, pouvant inclure des tâches telles que la traduction, la réécriture ou la paraphrase.text-classification: attribution d’une catégorie ou d’une étiquette prédéfinie à un texte en fonction de son contenutext-generation: création de texte à partir de zéro ou en complétant un texte existanttoken-classification: attribution d’étiquettes à chaque « token » (unité de texte, généralement un mot ou un caractère) dans un texte, souvent utilisé pour l’annotation sémantique ou la détection d’entités (NER)translation: traduction automatique d’un texte d’une langue source vers une langue ciblezero-shot-classification: classification de texte sans nécessiter de données d’entraînement spécifiques à chaque catégorie, en utilisant des modèles pré-entraînés pour prédire des étiquettes
Il est aisé d’utiliser un pipeline pour réaliser chacune de ces tâches.
Utilisation
Par exemple, ici j’utilise un pipeline pour une tâche de text-classification en seulement 3 lignes de code:
from transformers import pipeline
pipe = pipeline("text-classification")
pipe("This restaurant is awesome")Sortie: [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
Le pipeline charge un modèle par défaut automatiquement (ici, le modèle chargé est distilbert-base-uncased-finetuned-sst-2-english). De plus, le pipeline peut directement traiter un texte brut car il prend en charge, en plus de la prédiction, le preprocessing NLP.
À partir de la phrase « This restaurant is awesome » le modèle prédit une tonalité positive de la part de l’auteur.
Il est également possible de traiter plusieurs données en même temps. Pour cela, on passe simplement une liste de string au pipeline:
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
pipe(["This restaurant is awesome", "This restaurant is awful"])Sortie:[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
Ici, le modèle chargé par défaut détermine parfaitement la polarité de nos phrases: positive ou négative.
Computer vision
La Computer Vision est le traitement d’image et de succession d’images (vidéo) par Intelligence Artificielle.
Voici les principales tâches que peut résoudre les pipeline de 🤗 Transformers:
depth-estimation: estimation de la profondeur ou de la distance des objets dans une imageimage-classification: classification d’une image dans une classe prédéfinie ou prédiction de son contenuimage-segmentation: division d’une image en régions ou segments afin d’identifier les objets présents dans l’imageobject-detection: localisation et classification des objets spécifiques dans une imagevideo-classification: classification d’une séquence vidéo dans une classe donnée en fonction de son contenuzero-shot-image-classification: classification d’une image dans une classe non vue pendant l’entraînement du modèlezero-shot-object-detection: localisation et classification d’objets spécifiques dans une image, y compris des objets non vus pendant l’entraînement du modèle
Illustrons la simplicité des pipeline avec une tâche de depth-estimation.
Tout d’abord, importons une image :
from PIL import Image
import requests
from io import BytesIO
image_url = "https://cc0.photo/wp-content/uploads/2016/11/Fluffy-orange-cat-980x735.jpg"
Image.open(BytesIO(requests.get(image_url).content))
Ensuite, on utilise un pipeline pour la traiter. Par ailleurs, on indique un modèle choisi par nos soins: le "Intel/dpt-large".
from transformers import pipeline
estimator = pipeline(task="depth-estimation", model="Intel/dpt-large")
result = estimator(images=image_url)
resultSortie:{'predicted_depth': tensor([[[ 6.3199, 6.3629, 6.4148, ..., 10.4104, 10.5109, 10.3847],...,[22.5176, 22.5275, 22.5218, ..., 22.6281, 22.6216, 22.6108]]]),'depth': <PIL.Image.Image image mode=L size=640x480>}
Le résultat est donné à la fois sous la forme d’un tensor PyTorch et d’une image PIL.
On peut afficher l’image comme ceci:
result['depth']
Grâce au modèle que nous avons sélectionné, le pipeline détermine avec aisance la profondeur de notre image.
Audio
Un domaine de plus en plus populaire en Intelligence Artificielle est le traitement de données audio.
Voici les tâches pouvant être réalisées dans ce domaine avec un pipeline de 🤗 Transformers:
audio-classification: attribution d’une catégorie ou d’une étiquette à un fichier audio en fonction de son contenuautomatic-speech-recognition: conversion de la parole humaine en textetext-to-audio: conversion de texte en fichiers audio, généralement en utilisant des synthétiseurs vocaux ou des techniques de narration automatiséezero-shot-audio-classification: classification de fichiers audio en catégories prédéfinies sans avoir besoin de données d’entraînement spécifiques pour chaque catégorie, en utilisant des modèles pré-entraînés pour prédire les étiquettes.
À partir de l’audio ci-dessous, nous allons effectuer une tâche de automatic-speech-recognition:
from transformers import pipeline
transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")Sortie: {'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
Notre modèle whisper-small de l’entreprise OpenAI transcrit parfaitement un audio en texte.
Multimodal
Le domaine multimodal en IA fait référence à l’utilisation simultanée de multiples modes d’entrée comme le texte, l’image et l’audio.
Les tâches multimodal suivantes peuvent être résolues avec un pipeline:
document-question-answering: réponse à des questions formulées en langage naturel en utilisant des documents comme source d’informationfeature-extraction: extraction de caractéristiques ou d’attributs à partir de données brutesimage-to-text: conversion d’informations visuelles contenues dans une image en texte descriptif ou en métadonnéesvisual-question-answering: réponse à des questions en utilisant des informations visuelles, généralement en se basant sur des images, en combinant le traitement d’images et le traitement du langage naturel pour fournir des réponses
Ici, nous allons demander au modèle ce que la personne sur la photo porte (en anglais, What is she wearing ?):

from transformers import pipeline
oracle = pipeline(model="dandelin/vilt-b32-finetuned-vqa")
image_url = "https://huggingface.co/datasets/Narsil/image_dummy/raw/main/lena.png"
oracle(question="What is she wearing ?", image=image_url)Sortie:[{'score': 0.9480270743370056, 'answer': 'hat'},
{'score': 0.008636703714728355, 'answer': 'fedora'},
{'score': 0.003124275477603078, 'answer': 'clothes'},
{'score': 0.0029374377336353064, 'answer': 'sun hat'},
{'score': 0.0020962399430572987, 'answer': 'nothing'}]
Le modèle multimodal prend en entrée une image et du texte. Cela lui permet, à là fois de comprendre notre photo, mais également, de répondre à notre question.
Où trouver des modèles ? – Comment utiliser Hugging Face 🤗 Transformers
Par défaut 🤗 Transformers charge un modèle lors de l’appel d’un pipeline.
Néanmoins, il est également possible d’utiliser un modèle hébergé par Hugging Face.
Tu peux découvrir la totalité des modèles disponibles sur le site de l’entreprise.
Une fois dessus, suis ces étapes pour trouver le modèle qui correspond à tes besoins :
- Clique sur « Models » en haut de l’écran
- Choisis une tâche dans le menu à gauche
- Copie le nom du modèle de ton choix dans l’encadré principale
- Appelle le modèle copié avec
pipeline(model=nomDuModel)
Ces étapes sont résumées visuellement ci-dessous:
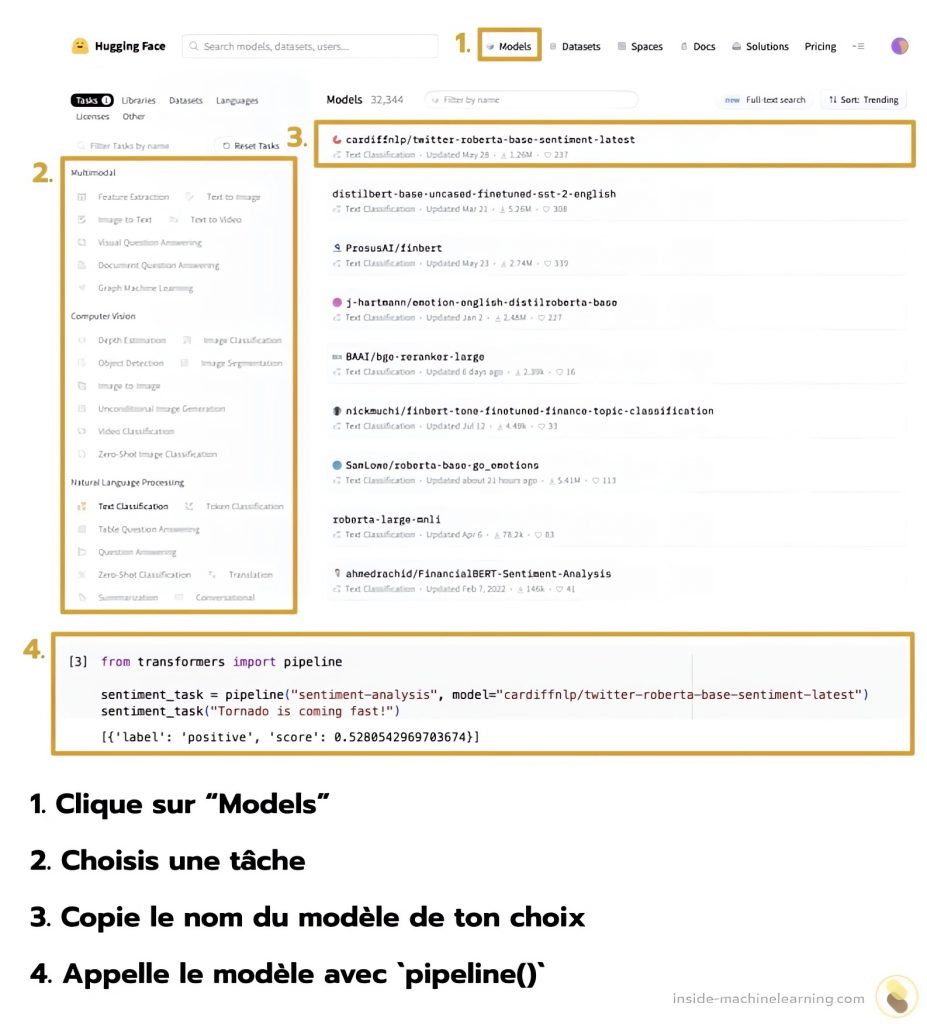
Grâce à son API, Hugging Face propose à ses utilisateurs des modèles à la pointe de la recherche.
Le but de Hugging Face est clair: démocratiser l’IA au sein des entreprises.
Et elle compte bien devenir un acteur majeur du domaine.
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
source: TechCrunch – Hugging Face raises $235M from investors, including Salesforce and Nvidia
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



