

Featurization is a technique to improve your Machine Learning model. It allows to enrich your dataset with new data.
Basically, Featurization is a synonym of Feature Engineering, a concept on which we have already written a detailed article.
To put it simply, Feature Engineering is another word for Preprocessing.
Preprocessing represents all the techniques used to transform our data.
Following preprocessing, we can train a Machine Learning model.
An example of preprocessing is the following: transforming text data into numerical format.
Ok then:
Featurization = Feature Engineering = Preprocessing
The problem: nobody uses the word Featurization anymore.
It has been forgotten for a few years (I only found 4 articles about it on the internet).
To the extent that the word Featurization has changed its meaning.
While participating in Kaggle competitions, I saw it used by various experts.
Featurization now refers to a specific technique.
What is Featurization?
Since there is no real definition, here is the one I propose:
Featurization is the set of techniques used to obtain new information from pre-existing data in a dataset.
A simple example:
- A dataset gathers the games of Scrabble players with two columns: difficulty level and result of the match (win or not)
- The goal is to predict the player’s score
In this case, an example of Featurization would be to add a third column Number of Victories allowing us to know if the player was performing in his previous games:
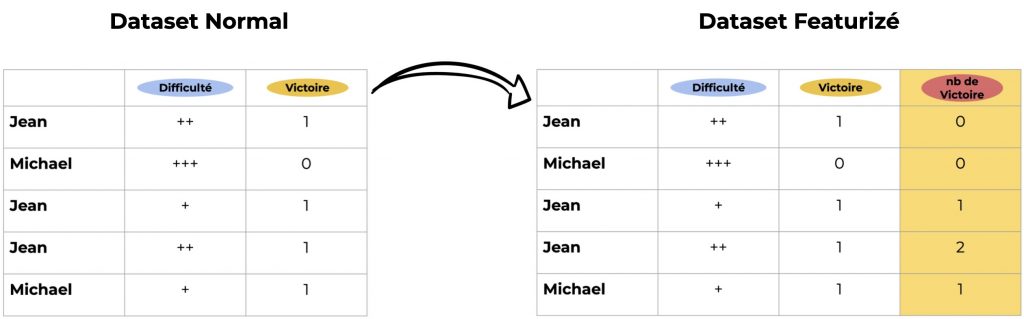
Featurization takes advantage of pre-existing data to add value to the dataset.
Thus, I consider Featurization as a kind of Data Augmentation.
The final goal of this technique is obviously to improve the performance of the Machine Learning model.
Keep in mind, however, that Data Augmentation allows to add rows to our dataset, whereas here we‘re adding columns.
Enough of blabla. Let’s get down to business!
Dataset
In this tutorial we will take a simplified version of the Kaggle competition dataset: Scrabble Player Rating.
The goal is to predict the score of a player in a scrabble match.
Each row represents a match against a robot.
We have 11 columns:
- nickname – player’s name
- score – player’s score at the end of the match
- rating – rating on woogles.io BEFORE the game is played (the column to predict)
- bot_name – the name of the bot the player played against
- bot_score – the bot’s score at the end of the game
- bot_rating – bot’s rating on woogles.io BEFORE the game is played
- game_end_reason – how the game ended
- winner – the winner, 0 if the player and 1 if the bot
- created_at – the date of the game
- game_duration_seconds – the duration of the game in seconds
We start by importing the datasets that I stored on github:
!git clone https://github.com/tkeldenich/datasets.gitThen you can open the dataset we are interested in with the pandas library :
import pandas as pd
df = pd.read_csv('/content/datasets/simplified-scrabble-player-rating.csv', index_col='game_id')
df.head()
We will quickly deal with the preprocessing since it is not the main topic of the article.
Here we only need to transform our text categorical data into numerical categorical data.
Preprocessing
For this we use the category_encoders library which makes the task much easier:
!pip install category_encodersWith it we can transform categorical data like the game_end_reason column.
It has 4 categories:
df.game_end_reason.unique()Output: ‘STANDARD’, ‘RESIGNED’, ‘TIME’, ‘CONSECUTIVE_ZEROES’
Instead of these textual data, we will have only numbers: 1,2,3,4. Without this we could not train a Machine Learning model.
We use the OrdinalEncoder function which encodes all our categories into numerical data.
BEWARE, it is not because you know that there are categorical data in your dataset that Python has detected them. To see if it has recognized your data, use df.types, the categorical columns should be noted “category” or “object“.
We see that there is a problem. Our categories have the type “object” but the created_at column also.
This is not good. If we leave the dataset like that, all our created_at data will be transformed into a simple number.
To counter this, we tell Python that our column is of type “datetime“:
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
df['created_at'] = pd.to_datetime(df['created_at'])We can now use the OrdinalEncoder function on the whole dataset.
It will detect the objects and transform them into numbers:
import category_encoders as ce
X = df.copy()
X = ce.OrdinalEncoder().fit_transform(X).drop("rating", axis=1)
y = df["rating"]We check that everything is ok:
X.head()
And we can move on to the next step!
Training without Featurization
In this part, we will train a Machine Learning model without Featurization.
This will allow us to see the difference when we use the technique.
We choose our model from the lightgbm (Light Gradient Boosting Machines) library:
from lightgbm import LGBMRegressor
model = LGBMRegressor(n_estimators=1000, verbose=-1, random_state=42)Next, we separate our dataset into training and test data:
X_train = X[:int(len(X)*0.8)].drop('created_at',axis=1)
X_valid = X[int(len(X)*0.8):].drop('created_at',axis=1)
y_train = y[:int(len(X)*0.8)]
y_valid = y[int(len(X)*0.8):]I should point out that the created_at column will not be used for training. We can’t use it because this column doesn’t contain only numbers. Nevertheless, it will be used for the Featurization.
We train the model:
model.fit(X_train,y_train)Then we compute the final score:
model.score(X_valid,y_valid)Output: 0.898
The accuracy is 89% which is already very good!
Our goal now is to use Featurization to increase this score.
Note for curious mathematicians: to calculate the precision in a regression, we use the coefficient of determination.
Featurization
We arrive at the eagerly awaited technique: Featurization.
The objective of Featurization is to add information to our dataset to enrich it.
Here I propose to add the column: Player’s win count.
Reminder: each line corresponds to the match of a player against a robot. We will have here a new column corresponding to the player’s win count.
The column created_at, allows us to have the date of each match and the column winner allows us to know who is the winner.
With Featurization, we merge the information from these two columns to create a new one. This allows us to create information that we would not have had before.
In our case we get the number of wins of the player in the current match.
Here is the function to create the column called cumm_player_wins :
import numpy as np
def create_cumm_player_wins(df):
df = df[["nickname", "created_at","winner"]]
df= df.sort_values(by="created_at")
df["cumm_player_wins"] = np.zeros(len(df))
for nickname in df["nickname"].unique():
df.loc[df["nickname"]==nickname, "cumm_player_wins"]= np.append(0, df[df["nickname"]==nickname]["winner"].expanding(min_periods=1).sum().values[:-1])
df[["cumm_player_wins"]] = df[["cumm_player_wins"]].fillna(0)
df = df.sort_index()
return df[["cumm_player_wins"]]We use the function with create_cumm_player_wins(X.copy()) while adding the newly created column in X with X.join() :
X_featurize = X.join(create_cumm_player_wins(X.copy()))We can display the result:
X_featurize.head()
And finally, we repeat the same process as before, splitting our data between training and validation:
X_featurize_train = X_featurize[:int(len(X)*0.8)].drop('created_at',axis=1)
X_featurize_valid = X_featurize[int(len(X)*0.8):].drop('created_at',axis=1)
y_train = y[:int(len(X)*0.8)]
y_valid = y[int(len(X)*0.8):]We initialize the model :
model = LGBMRegressor(n_estimators=1000, verbose=-1, random_state=42)We train it :
model.fit(X_featurize_train,y_train)And we compute the score:
model.score(X_featurize_valid,y_valid)Output: 0.923
We obtain an accuracy of 92.3%!
This is an increase of 3% compared to the last model, it’s huge!
It’s your turn to you to use Featurization in your own projects now.
And if you FURTHER want to increase your accuracy, other techniques exist!
Check out our articles presenting them:
See you soon on Inside Machine Learning 😉
sources :
- Full Walkthrough (EDA + FE + Model Tuning) – Iain Cruickshank
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



