

The mechanism of Attention is a fundamental process in Deep Learning to understand the most recent high-performance models.
Today, most AI researchers integrate Attention in their neural networks.
To apprehend Attention, you need to know the principle of Encoders-Decoders, a Deep Learning model explained in this article.
Indeed, the mechanism of Attention is an improvement of the encoding-decoding system.
And this is what we will see in this article !
The Attention Role
Encoder-Decoders allow in most cases to translate a sentence from one language to another (the other problems addressed by Encoder-Decoders and Attention are detailed in the conclusion).
At the end of our article on the subject, we saw that there was a flaw in this approach. The vector created by the Encoder is fix and this causes problems when translating long sentences.
Fortunately, the Attention mechanism will, on the one hand, overcome this problem, and on the other hand improve the capabilities of the Encoder-Decoder.
Thus, for a translation problem, the Attention mechanism will be much more efficient than the classical approach.

How does Attention work?
Encoder – Attention
Attention is an improvement of Encoder-Decoder, a 2.0 version of the model.
In fact, the neural network behind an Encoder is a RNN. A very peculiar type of network.
Classical approach is to collect the output of the Encoder and transmit it then to the Decoder which will give us the result of our model.
With the Attention mechanism, it is different.
Instead of focusing only on the final output of the RNN, Attention take information at each step of the RNN (see diagram below):
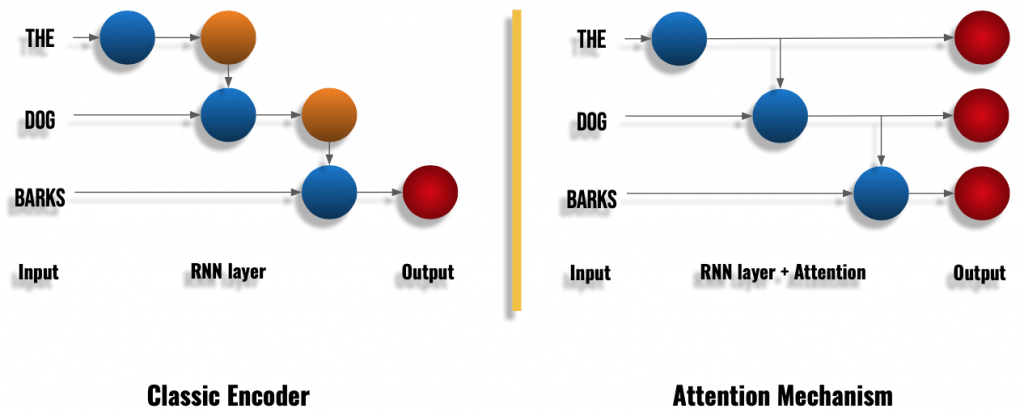
We can see above that in a classical RNN layer we have an output for each word. Each output (or result) will be used to compute the output of the next word and so on. This is the recurrence.
In a RNN layer with Attention, we also have this recurrent calculation on each word. But in addition to that, we keep each of these recurrent outputs in memory to form the final output.
In other words, the Attention Encoder will transmit much more information to the Decoder than in the classical approach.
Intuitively, this extra information explains why the final translation will be of better quality.
Indeed, the more information we have about a sentence, the better we understand it !
Decoder – Attention
After this encoding step, we use another neural network called here : Decoder.
Attention Decoder also uses an RNN but then adds other more complex calculations.
Its main function is to understand the relationship between each word.
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.
This relationship will allow us to identify the links between words. Thus our model will understand which verb relates to which subject, which subject is associated with which adjective, etc.
For more clarity, we can display the connections interpreted by the Attention Decoder :
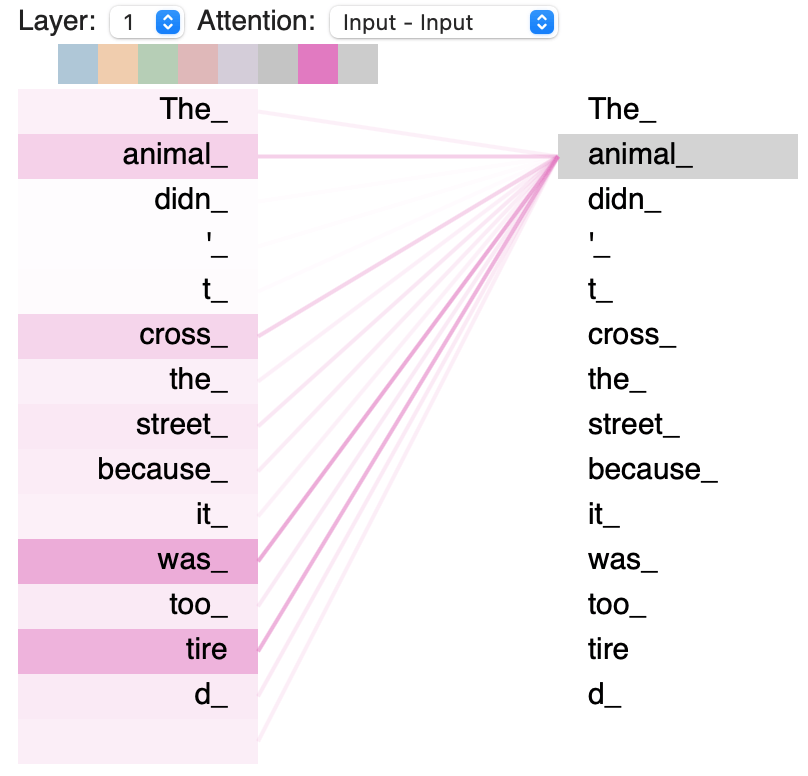
In this diagram, we can see the relationship between the words in the sentence “The animal did not cross the street because it was too tired” after using the Attention mechanism.
If we focus on the word “animal”, we can see that it is directly linked to “was” and “tired”.
This makes sense because it was the animal that was exhausted ! But is it as obvious for a computer as for a human ?
Well, here Attention proves that even if the words are very far apart in the sentence, the computer may understand their relationship.
This is the power of the Attention mechanism. When training neural networks, the model focuses its attention on each word in the sentence.
Thus the model can detect the context of the words and have a global understanding of the sentence.
You can also visualize the links identified by the Attention mechanism and play with the model parameters. It is on this link in the Display Attention section.
Conclusion
Attention is a major breakthrough in Deep Learning and we have presented in this article a brief overview of this mechanism.
It was created to solve translation problems but its field of application is getting wider and wider.
Thus, it is used in NLP tasks, word processing and also in Computer Vision.
It is still preponderant today with for example the DINO model. A research paper unveiled by facebook.ai in April 2021 (Mathilde Caron, et al.).
Attention allows here to separate the main object from the background. And this in self-supervised learning (i.e. the model has understood by itself to solve the task).
I let you see the result by yourself :

In fact, this Deep Learning model proposed by facebook.ai doesn’t just use Attention… it uses Transformers.
A version 3.0 of the Encoders-Decoders ? Read our next article to find out !
En fait, ce modèle de Deep Learning proposé par facebook.ai n’utilise pas que l’Attention… il utilise les Transformers.
Une version 3.0 des Encodeurs-Décodeurs ? À voir dans notre prochain article !
sources :
- Jason Brownlee – MachineLearningMastery
- Jay Alammar – GitHub
- Tensor2Tensor – Google Colab
- Facebook.ai – DINO and PAWS
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



