

Le mécanisme de l’Attention est un processus fondamental en Deep Learning pour comprendre les modèles les plus performants.
Aujourd’hui, la plupart des chercheurs en IA intègrent ce mécanismes dans leurs réseaux de neurones.
Pour comprendre l’Attention il faut connaître le principe des Encodeurs-Décodeurs, une architecture de réseau de neurones expliquée dans cet article.
Le mécanisme de l’Attention est en fait une amélioration de ce système d’encodage-décodage.
Et c’est ce que l’on va voir dans cet article !
L’apport de l’Attention
Les Encodeurs Décodeurs permettent, dans la plupart des cas, de traduire une phrase d’une langue à une autre.
À la fin de l’article, on a vu qu’il y a un défaut à cette approche : le vecteur créé par l’Encodeur est fixe.
Cela pose problème pour traduire de longues phrases.
Heureusement, le mécanisme de l’Attention va, d’une part, déjouer ce problème, et d’autre part améliorer les capacités de l’Encodeur-Décodeur.
Pour un problème de traduction, le mécanisme de l’Attention va être bien plus performant que l’approche classique.

L’Attention comment ça marche ?
Encodeur – Attention
L’Attention est une amélioration des Encodeurs-Décodeurs, une version 2.0 du modèle.
Dans la version 1.0, la couche derrière l’Encodeur est un RNN. Un type bien particulier de couche détaillée dans cette article.
Le RNN analyse chaque mot tout en gardant en mémoire le précédent. Cela lui permet d’analyse efficacement des phrases
Mais le mécanisme de l’Attention est différent.
C’est une amélioration du RNN.
Au lieu de se concentrer uniquement sur la sortie finale du RNN, l’Attention préleve des informations lors de chacune des étapes du RNN (voir schéma ci-dessous) :
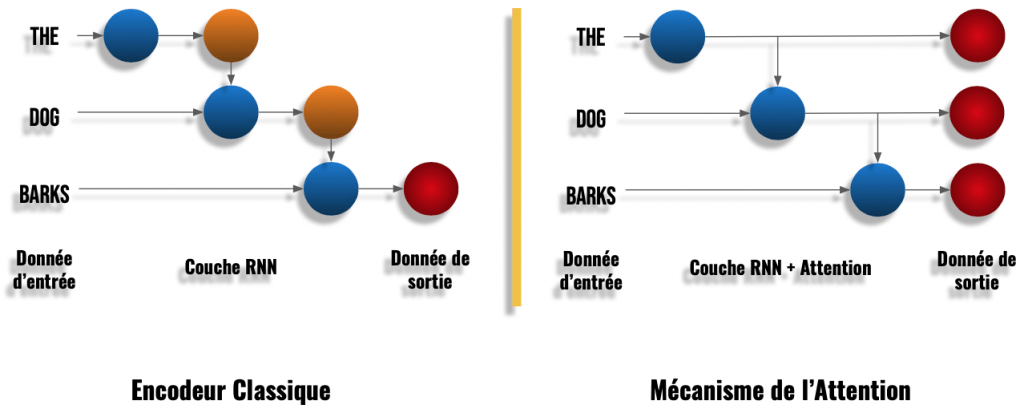
On peut voir ci-dessus que dans une couche RNN classique on a une sortie pour chaque mot. Chaque sortie sera utilisé pour calculer la sortie du mot suivant et ainsi de suite. C’est la récurrence.
Dans une couche RNN avec Attention, on a aussi ce calcul récurrent sur chaque mot. Mais en plus de cela, on garde chacune de ces sorties récurrentes en mémoire pour former la sortie finale.
Dit autrement, l’Encodeur de l’Attention va transmettre beaucoup plus d’informations au Décodeur que lors de l’approche classique.
Intuitivement, ce surplus d’informations explique que la traduction finale sera de meilleure qualité.
Ehh oui, plus on a d’informations sur une phrase, mieux on peut la comprendre !
Décodeur – Attention
Après cette étape d’encodage, on utilise un autre réseau de neurones appelé ici : Décodeur.
Le Décodeur de l’Attention utilise, lui aussi, un RNN mais il ajoute ensuite d’autres calculs plus complexes.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Sa fonction principale est de comprendre les relations entre chacun des mots.
Cette relation va nous permettre d’identifier les liens qui unissent les mots entre eux. Ainsi notre modèle va comprendre quel verbe se rapporte à quel sujet, quel sujet est associé à quel adjectif, etc.
Pour plus de clarté, on peut afficher les liens interprétés par le Décodeur de l’Attention :
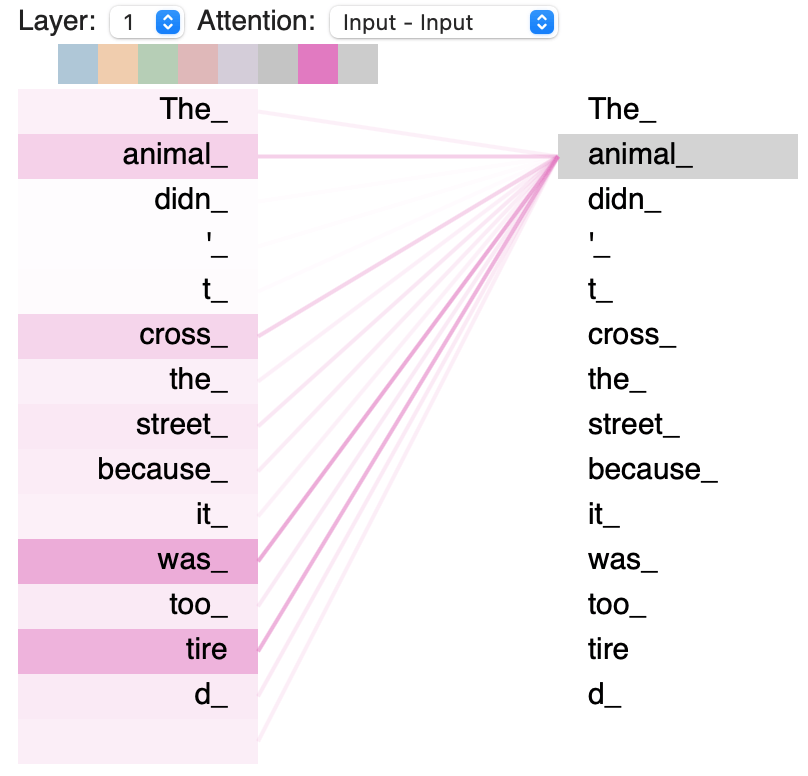
Sur ce schéma, on peut voir les liens qui unissent les mots de la phrase « L’animal n’a pas traversé la rue car il était trop épuisé » (en anglais) après avoir utilisé le mécanisme de l’Attention.
En se focalisant sur le mot « animal », on peut voir qu’il est directement relié à « était » et « épuisé ».
C’est logique car c’est bien l’animal qui était épuisé ! Mais est-ce aussi évident pour un ordinateur que pour un humain ?
Eh bien, ici, l’Attention nous prouve que même si les mots sont très éloignés dans la phrase, l’ordinateur peut comprendre leurs relations.
C’est l’avantage du mécanisme de l’Attention.
Lors de l’entraînement des réseaux de neurones, le modèle focalise son attention sur chaque mot de la phrase.
Ainsi le modèle peut détecter le contexte des mots et avoir une compréhension globale de la phrase.
Tu peux, toi aussi, visualiser les liens détectés par le mécanisme de l’Attention et jouer avec les paramètres du modèle. C’est sur ce lien à la section Display Attention.
Conclusion
L’Attention est une avancée majeure en Deep Learning et tu as vu dans cet article un bref aperçu de ce mécanisme.
Il a été créé pour résoudre des problèmes de traduction mais son champ d’application s’élargit de plus en plus.
Ainsi, il est utilisé dans des tâches de NLP, traitement de texte mais aussi en Vision d’ordinateur.
Il est encore prépondérant aujourd’hui.
Il a été utilisé par exemple dans le modèle DINO. Un papier de recherche dévoilé par facebook.ai en avril 2021 (Mathilde Caron, and al.).
L‘Attention permet ici de séparer l’objet principal de l’arrière-plan. Et cela en apprentissage auto-supervisé (c’est-à-dire que le modèle a compris de lui-même comment résoudre la tâche).
Je te laisse voir le résultat par toi-même :

Ce modèle de Deep Learning proposé par facebook.ai n’utilise pas que l’Attention… il utilise les Transformers.
Une version 3.0 des Encodeurs-Décodeurs ? À voir dans notre prochain article !
sources :
- Jason Brownlee – MachineLearningMastery
- Jay Alammar – GitHub
- Tensor2Tensor – Google Colab
- Facebook.ai – DINO and PAWS
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



