

Dans cet article, je vous propose de réaliser votre premier projet Keras avec Python pour apprendre le Deep Learning.
Tout débutant en Deep Learning se doit de connaître Keras.
C’est une librairie simple et facile d’accès pour créer vos premiers Réseaux de Neurones.
Keras fait partie d’une librairie plus étendue enocre : TensorFlow.
En apprenant à utiliser Keras vous apprenez aussi a utiliser TensorFlow ce qui vous donnera les bases pour atteindre un niveau plus avancé.
Commençons dès maintenant ce premier projet Keras !
Premier Pas – Premier Projet Keras
Data
Un projet en Deep Learning ne se fait pas uniquement avec Keras.
Ici nous allons utiliser la librairie Pandas pour charger nos données. Tout d’abord, importons la librairie :
import pandas as pdMaintenant, on peut charger notre dataset.
Pour ce projet nous allons utiliser le dataset pima-indian-diabete.
Ce jeu de données provient du National Institute of Diabetes and Digestive and Kidney Diseases.
L’objectif de ce projet est de prédire si un patient est diabétique ou non, sur la base de certaines mesures diagnostiques incluses dans le jeu de données.
Vous pouvez le télécharger sur ce Github.
Une fois que vous l’avez, mettez le dans votre environnement de code (Notebook ou dossier) et chargez le grâce à la fonction read_csv. Vous pouvez ensuite l’afficher avec la fonction head :
df = pd.read_csv('pima-diabetes.csv')
df.head()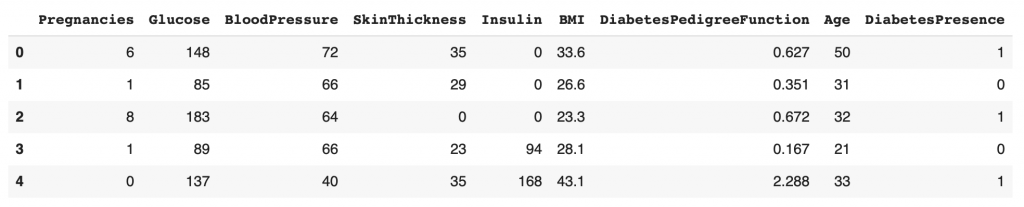
On a maintenant notre fichier CSV chargé dans un DataFrame Pandas. Ce DataFrame nous permet de facilement manipuler nos données.
Vous pouvez voir qu’il y a en tout neuf colonnes :
- Pregnancies – Nombre de Grossesses
- Glucose – Glucose
- Blood Pressure – Pression artérielle
- Skin Thickness – Épaisseur de la peau
- Insulin – Insuline
- BMI – IMC
- Diabetes Pedigree Function – Fonction du pedigree de diabète
- Age – Age
- Diabetes Presence – Présence de diabète
Notre deuxième étape est d’extraire les données X et Y. Nos features et notre target.
Les features sont les données qui nous permettront de prédire notre target.
Dans notre cas, on veut utiliser les données diagnostique de chaque patient pour prédire la présence de diabète (DiabetesPresence).
X = df.loc[:, df.columns != 'DiabetesPresence']
Y = df.loc[:, 'DiabetesPresence']X contient tout le dataset sauf la colonne DiabetesPresence. Y contient uniquement la colonne DiabetesPresence.
Dans la colonne DiabetesPresence :
- 1 indique la présence du diabète
- 0 indique l’absence de Diabète.
Deep Learning
Nos données sont maintenant prêtes à être utilisées.
Nous pouvons enfin voir ce que Keras à dans le ventre !
Ici, on importe deux fonctions :
Sequentialpour initialiser notre modèleDensepour ajouter des couches Dense à notre modèle
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import DenseOn peut maintenant utiliser ces fonctions.
Tout d’abord on initialise le modèle. Puis on lui ajoute des couches :
model = Sequential()
model.add(Dense(12, input_shape=(8,), activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))Ici le modèle est assez simple. Il possède 4 couches :
- Entrée + Couche cachée :
model.add(Dense(12, input_shape=(8,), activation='relu')) - Cachée :
model.add(Dense(8, activation='relu')) - Sortie :
model.add(Dense(1, activation='sigmoid'))
Remarquez que la premiere couche possède en fait deux couches.
Effectivement cette première couche possède un couche d’entrée indiquée par l’input_shape de 8. Et une couche cachée Dense, dans laquelle on indique la dimension 12 et la fonction d’activation relu (plus d’informations sur ces fonctions en fin d’article).
Pour les couches d’entrée et se sortie, il faut indiquer la taille de notre dataset. Dans notre cas, les features possèdes 8 colonnes. On indique donc 8 dans la couche d’entrée. La target possède une seule colonne. On indique donc 1 dans la couche de sortie.
Ainsi notre modèle de Deep Learning va prendre en entrée nos features et nous donnera en sortie une prédiction de notre target.
Ensuite, on va pouvoir compiler notre modèle : on indique à notre modèle la loss function, l’optimisateur et la métrique à utiliser.
Ce sont des concepts que nous n’aborderons pas dans ce tutoriel. Mais gardez en tête que ces fonctions sont la cerise sur le gateau qui permet d’entraîner notre modèle de Deep Learning.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])Finalement, on peut entraîner notre modèle.
Entraînement
Pendant l’entraînement, le modèle va itérer plusieurs fois sur nos données. Il tente des prédictions et les compare aux résultats qu’il doit prédire. Ensuite il ajuste ses poids grâce aux fonctions définies lors de la compilation.
Les poids et le processus d’apprentissage sont décrit plus en détails dans cet article.
Ces itérations sont appelées des epochs. Lorsque epochs=100, le modèle itèrera 100 fois sur le dataset complet.
model.fit(X, Y, epochs=100)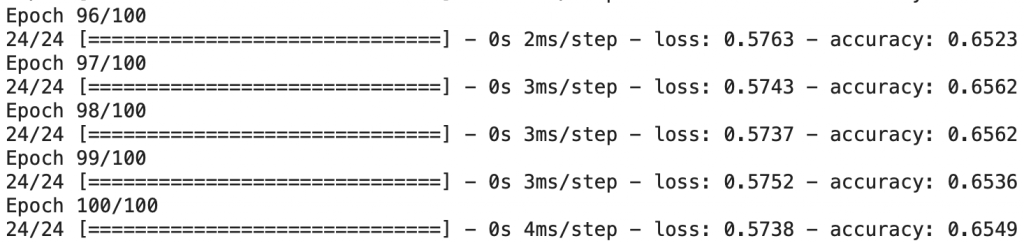
Le modèle est maintenant entraîné !
On peut ensuite évaluer ses performances sur nos données. Pour cela, on utilise la fonction evaluate.
_, accuracy = model.evaluate(X, Y)
print('Accuracy: %.2f' % (accuracy*100))Sortie : 73.83
Notre modèle a une précision de 73.83%. C’est pas mal mais…
…cela ne représente pas la précision réelle de notre modèle.
Effectivement, en Deep Learning, on veut entraîner un modèle d’Intelligence Artificielle pour qu’il soit performant en toute situation.
Si on évalue notre modèle avec les données sur lequel il a été entraîné, il sera forcément plus performant que sur des données qu’il n’a jamais vu.
Et c’est précisément cela qui nous intéresse. Savoir si notre modèle de Deep Learning est capable d’utiliser ses connaissances sur des données qu’il n’a jamais vu. S’il y arrive, on dit que le modèle est capable de généraliser.
Dans cette première partie, nous avons utilisé un seule et même dataset pour l’entraînement et l’évaluation de nos données. Mais en réalité, un projet ne se passe pas comme ça.
En fait cette partie nous a permis de valider qu’on peut:
- utiliser nos données
- résoudre notre problème avec un modèle de Deep Learning
Pour aller plus loin, je vous propose cette deuxième partie. Dedans, nous allons voir comment vérifier que notre modèle sait généraliser.
Aller plus loin – Premier Projet Keras
Data
Notre dataset contient 789 lignes. Autrement dit, nous possédons les données médicales de 789 patients.
Comme on l’a vu dans la première partie, nous avons besoin de plusieurs types de données : l’une pour entraîner notre modèle et l’autre pour évaluer ses performances.
Ces données ont un nom :
- Les données d’entraînement :
df_train - Les données d’évaluation :
df_test
Le problème ? Nous n’avons qu’un seul jeu de données.
Alors, nous allons nous même créer ces deux jeux de données à partir de notre CSV.
Une large partie de ce dataset sera utiliser pour l’entraînement et une plus petite pour l’évaluation.
Nous allons prendre 80% de ces données pour entraîner notre modèle et 20% pour l’évaluer.
Heureusement Pandas nous permet de faire cela facilement :
df_train = df.sample(frac=0.8)
df_test = df.drop(df_train.index)Premièrement, on prend aléatoirement dans notre dataset 80% des lignes.
Puis, nous prenons les lignes restantes pour les données d’évaluation.
On peut afficher nos données d’entraînement pour vérifier que nos données sont bien prélevées aléatoirement :
df_train.head()
On voit que les index sur la colonne toute à gauche ne se suivent pas. Cela indique que le dataset a bien été mélangé avant de prélever df_train.
Mais pourquoi faire un prélèvement aléatoire ?
Cela nous permet de nous assurer que la séparation réalisée n’est pas biaisée. Effectivement, le dataset tel qu’on l’a peut être trié préalablement sans qu’on soit mit au courant.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Si par exemple les patients avec diabète étaient présent seulement au début, et les patients sans diabète seulement à la fin. Cela nous donnerais des données d’entraînement contenant uniquement des diabétiques. Pas idéal si notre modèle de Deep Learning doit apprendre à généraliser.
Pour être capable de généraliser, notre modèle doit s’entraîner sur des données dissemblables.
Je vous invite donc à vérifier votre dataset avant d’effectuer une quelconque opération dessus.
Une bonne pratique est de toujours faire une séparation aléatoire pour être sûr qu’on ne se retrouve pas avec des données biaisées.
À partir de ces données, on peut créer les X features et Y target. Le processus est le même que dans la première partie :
X_train = df_train.loc[:, df.columns != 'DiabetesPresence']
Y_train = df_train.loc[:, 'DiabetesPresence']
X_test = df_test.loc[:, df.columns != 'DiabetesPresence']
Y_test = df_test.loc[:, 'DiabetesPresence']Modèle
Reprenons la structure de notre modèle de Deep Learning précédent :
model = Sequential()
model.add(Dense(12, input_shape=(8,), activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))On peut maintenant afficher son diagramme pour comprendre plus en détails le Réseau de Neurones que nous venons de créer.
Le diagramme d’un Réseau de Neurones nous permet de mieux comprendre sa structure. Pour cela on utiliser la fonction plot_model :
from tensorflow.keras.utils import plot_model
plot_model(model, to_file="model.png", show_shapes=True, show_layer_names=False, show_layer_activations=True)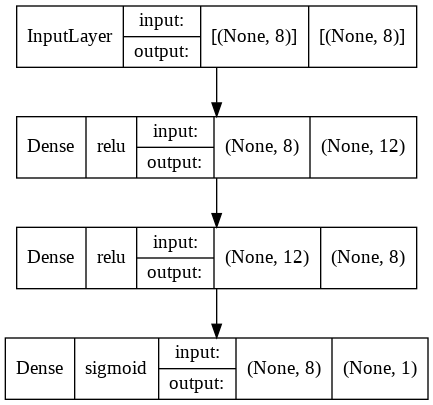
Le diagramme nous permet de visualiser les quatres couches de notre Réseau de Neurones, leur fonction d’activation, leur entrée et leur sortie.
Par exemple, notre troisième couche a comme fonction d’activation relu et a en entrée 12 neurones, pour 8 en sortie.
Maintenant, nous pouvons compiler notre modèle :
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])Passons finalement à la partie la plus importante : l’entraînement.
Ici nous allons faire quelques changements par rapport au code précédent.
Tout d’abord ajoutons la validation_split ce paramètre va séparer nos données d’entraînement en 2 sous-dataset :
- données d’entraînement
- données de validation
À noter : les données de validation ne sont pas les mêmes que les données d’évaluation. La validation permet de valider les performances au fil de l’entraînement. L’évaluation permet d’évaluer le modèle à la fin de l’entraînement.
Ces concepts vont s’éclairer au fil de cet article.
On indique aussi qu’on veut récupérer l’historique de cet entraînement. Cela nous permettra d’analyser plus en détails notre modèle. Pour cela on indique history en début de ligne.
Lançons l’entraînement :
history = model.fit(X_train, Y_train, validation_split=0.2, epochs=50, batch_size=10)
Analyse
Une fois l’entraînement terminé, on peut analyser visuellement ce qu’il s’est passé pendant ce process.
Pour cela on utilise la librairie Matplotlib :
from matplotlib import pyplot as pltNotre variable history a enregistré toutes les informations sur l’entraînement de notre modèle.
À chaque epoch le modèle :
- émet des prédictions sur les données d’entrainement ET de validation
- compare ses prédictions sur les données d’entrainement ET de validation avec le résultat attendu
- change ses poids en fonctions de ses performances sur les données d’entrainement UNIQUEMENT
Les données de validation sont seulement présente pour valider les résultats du modèle sur des données extérieur. Sur lesquels il ne s’entraîne pas.
En fait, cela permet de contrer ce qu’on appelle l’overfitting.
L’overfitting survient lorsque le modèle se spécialise trop sur les données d’entraînement.
Il devient performant sur ces données d’entraînement mais n’arrive pas à prédire de bon résultats sur les autres données.
Les données de validation sont utiliser pour vérifier que cela n’arrive pas.
Affichons les résultats :
plt.plot(history.history['accuracy'], color='#066b8b')
plt.plot(history.history['val_accuracy'], color='#b39200')
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()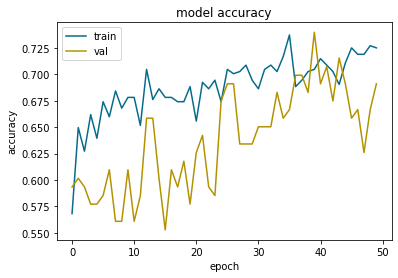
En bleu les résultats sur les données d’entraînement. En orange les résultats sur les données de validation.
Si la courbe orange suit la courbe bleu l’entraînement est bien réalisé. Lorsque le modèle augmente ses performances sur les données d’entraînement, il augmente aussi ses performances sur les données de validation. Cela indique que le modèle généralise bien.
Visuellement on peut voir l »overfitting lorsque la courbe de validation dévie de la courbe d’entrainement. Ici on peut voir qu’elle commence a dévier à partir de l’epoch 45 pour revenir sur le droit chemin à l’epoch 50.
Gardez en tête qu’il y aura toujours un gap entre les résultats de la courbe d’entraînement et ceux de la courbe de validation. C’est parce que le modèle est entraîné explicitement sur les données d’entraînement. Il est donc plus performant dans ce contexte.
Notre objectif est que ce gap reste le plus petit possible et que les courbes se suivent.
À l’epoch 50, le gap de précision entre les données d’entraînement et de validation est inférieur à 0.5. On considère que c’est acceptable.
Si ce n’avait pas été le cas, on aurait dû relancer l’entraînement avec d’autres paramètres.
Prédictions
Maintenant comment faire des prédictions sur de nouvelles données ?
On peut réutiliser notre modèle pour lui faire prédire la présence de diabète sur de nouvelles données. Pour cela rien de plus simple, on utiliser la fonction predict :
predictions = model.predict(X_test)On obtient un tableau de prédiction.
Affichons le premier élément :
predictions[0]Sortie : array([0.7407335], dtype=float32)
Ici qu’on obtient ni 1, ni 0 mais un chiffre à virgule 0.74. En fait c’est une probabilité.
On peut établir cette règle : si la probabilité est au dessus de 50%, il y a diabète sinon, il n’y a pas de diabète.
Modifions le résultat de ces prédiction pour avoir uniquement des 0 et 1 :
predictions = (model.predict(X_test) > 0.5).astype(int)Maintenant, au lieu d’avoir des probabilités nous avons des 0 et des 1 représentant la présence de diabète selon la règle établie plus haut.
Nous pouvons afficher les premieres prédictions et les comparer aux résultats attendu :
for i in range(5):
print('%s => Prédit : %d, Attendu : %d' % (X_test.iloc[i].tolist(), predictions[i], Y_test.iloc[i]))Sortie :
[8.0, 183.0, 64.0, 0.0, 0.0, 23.3, 0.672, 32.0] 1ere index => Prédit : 1, Attendu : 1
[10.0, 115.0, 0.0, 0.0, 0.0, 35.3, 0.134, 29.0] 2eme index => Prédit : 1, Attendu : 0
[2.0, 197.0, 70.0, 45.0, 543.0, 30.5, 0.158, 53.0] 3eme index => Prédit : 1, Attendu : 1
[1.0, 189.0, 60.0, 23.0, 846.0, 30.1, 0.398, 59.0] 4eme index => Prédit : 1, Attendu : 1
[7.0, 107.0, 74.0, 0.0, 0.0, 29.6, 0.254, 31.0] 5eme index => Prédit : 0, Attendu : 1
Le modèle fait de bonnes prédictions sur la majorité des cas.
On pourrait continuer pour évaluer ligne par ligne chaque prédiction de notre modèle.
Mais on préférera la fonction inclus dans Keras evaluate pour déterminer ses performances :
_, accuracy = model.evaluate(X_test, Y_test)
print('Accuracy: %.2f' % (accuracy*100))Sortie : 72,73
Le résultat est satisfaisant. Nous sommes très proches de la valeur obtenue dans la premiere partie de 73.83. Cela indique que le modèle réussi à généralisé.
Pour finir
Vous avez développé votre premier Réseau de Neurones avec Keras et avec une prédiction impressionnante de 72% !
Arriverez-vous à dépasser ce résultat ?
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources :
- MachineLearningMastery – Your First Deep Learning Project in Python with Keras Step-By-Step
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



