

Une erreur habituelle dans la détection par Bounding Boxes est d’utiliser la régression linéaire pour détecter l’emplacement de l’objet.
Effectivement il faut prédire les 4 bords délimitant l’objet pour pouvoir tracer une Bounding Boxe. Et quand on n’a pas le manuel, l’affaire peut s’avérer compliqué.
Mais alors comment structurer son Réseau de Neurones pour la détection par Bounding Boxes ?
C’est ce que nous allons voir tout de suite dans cet article !
Les Données
Premièrement, comment bien préparer ses données ?
Pour la détection d’objets sur image il nous faut évidemment… des images. La plupart des formats classiques feront l’affaire : jpg, png, jpeg, …
Ici l’objectif principal est de convertir nos image en donnée numériques. Pour que le modele de Deep Learning puisse les utiliser.
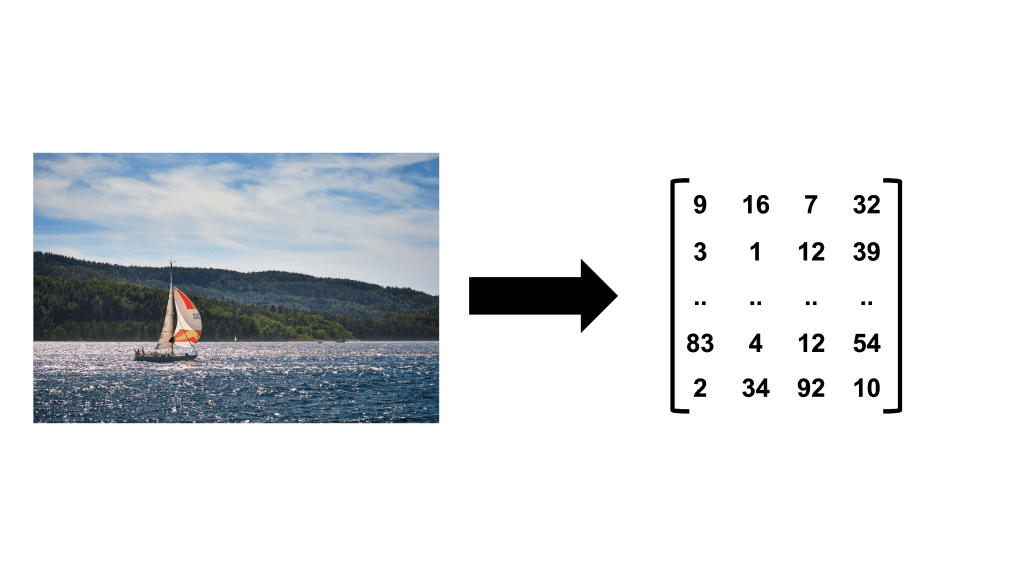
La deuxième étape est de réduire la dimension de l’image. Ce n’est pas une etape obligatoire mais garder a l’esprit que plus vos images sont petite, plus le modele les traitera rapidement. Mais inversement, plus elles sont réduites et moins l’information contenu dedans est pertinente.
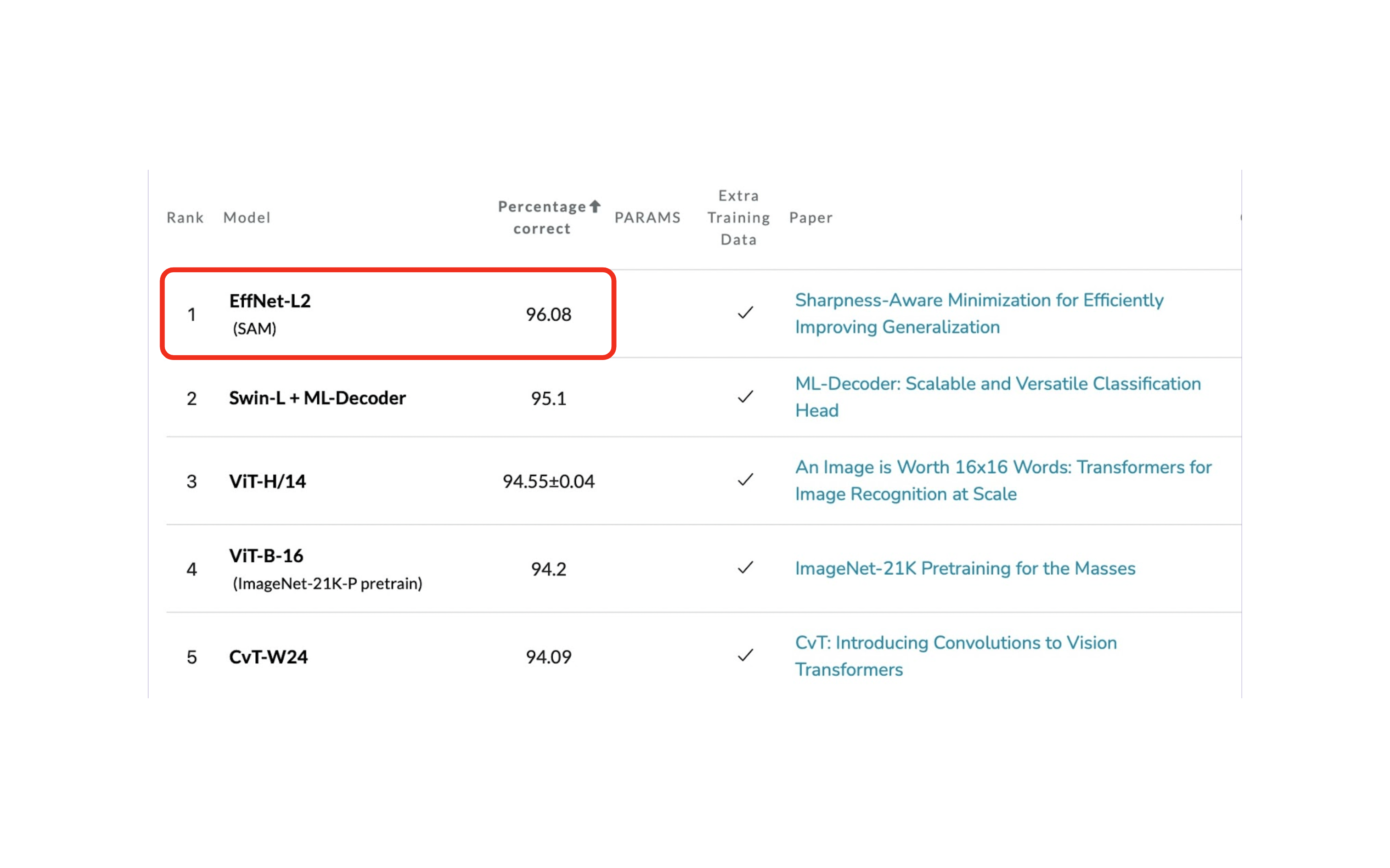
Il faut donc trouver un compromis entre la dimension et la qualité de l’image. À titre d’exemple, pour une tâche de classification sur des images de dimension 32x32pixels (dataset CIFAR) : le modele avec le plus haut score obtient un pourcentage de précision de 96% (source).
Ensuite, pour notre tâche de detection d’objet, nous avons besoin de points d’intérêt. Ces points d’intérêt nous permettront de tracer les Bounding Boxes
Là aussi, on va devoir modifier les points d’intérêt. Mais pas en réduisant leur taille.
En fait, on va les normaliser.
Un point d’intérêt possède des coordonnées : x et y.

La normalisation c’est diviser x par la largeur et y par la longueur.
De cette manière, on aura des coordonnées avec des valeurs compris entre 0 et 1.
Pourquoi normaliser me direz-vous ?
En fait c’est très simple. Il y a deux raisons.
La première est que si on a des coordonnées normalisées, qu’importe les changement de dimensions appliqués à nos image, les coordonnées s’adapteront toujours car il suffira de multiplier x par la nouvelle largeur et y par la nouvelle hauteur.
La deuxième raison est directement liée au réseau neurones et elle est fondamentale..
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Layers & Activation Function
Pour utiliser le Deep Learning avec des images, on va utiliser des couches de convolution (vous pouvez consulter cet article sur les couches de convolution si vous souhaitez vous rafraîchir la mémoire).
Mais si vous êtes arrivé ici, c’est sûrement que vous connaissez déjà le concept de la Convolution.
Nous allons donc nous focaliser sur la prédiction que va effectuer le modèle de Deep Learning. Autrement dit, le type de données qu’il va produire.
En Deep Learning les données de sortie sont gouvernées par une seule chose : la dernière couche du modèle.

Cette couche contient plusieurs informations essentielles:
- Une dimension, ou nombre de neurones
- Une fonction d’activation, qui contrôle la valeur du résultat
C’est cette dernière information qui nous intéresse. La fonction d’activation contrôle le résultat qu’on aura.
Dans notre cas on cherche à avoir en sortie des points de coordonnées normalisées.
Comme vu précédemment, ces coordonnées nous permettent d’être adaptable au changement de dimensions des images.
Mais elles sont aussi aisément calculables par notre réseau de neurones.
En fait, le réseau de neurones doit produire des coordonnées, c’est-à-dire une valeur entre 0 et 1.
Pour connaître la fonction d’activation à utiliser dans ce cas là, c’est simple, on peut se référer à notre tableau sur les fonctions d’activation (trouvable à la fin de cet article). On voit que la fonction d’activation sigmoid correspond parfaitement à notre objectif.
Effectivement la fonction d’activation sigmoïde permet d’avoir des valeurs entre 0 et 1.
Et si je veux quand même utiliser une régression linéaire avec mes coordonnées de base au lieu d’une fonction sigmoïde avec des coordonnées normalisées ?
Eh bien, vous pouvez essayer ! Et je vous encourage à le faire. Cela vous permettra de comprendre les réseaux de neurones de manière pratique.
Vous devriez normalement avoir en résultat des valeurs aléatoires entre -10.000 et 10.000. Des résultats très distants de ce qu’on attend.
En fait, le problème d’une régression linéaire, c’est l’absence de cadre. Vous avez potentiellement une infinité de valeurs, positive comme négative.

A l’inverse, l’avantage de prendre une fonction sigmoïde et des coordonnées normalisées, c’est de donner un cadre au réseau de neurones qui va le guider dans son apprentissage.

Bounding Boxes et plus…
J’aimerais rappeler que, ce qu’on a vu dans cette article s’applique au bounding boxes mais en général à toutes détections de points d’intérêt sur une image.
Que vous en ayez 1, 2 ou 1.000, vous pouvez utiliser cette technique. Il vous suffit d’indiquer la dimension adéquate dans la dernière couche de votre modèle.
Votre modèle à un défaut de performance ? On vous recommande chaleureusement d’utiliser des couches de Batch Normalisation ! On en parle en détail dans cet article, c’est une technique idéal pour améliorer son Deep Learning par image.
A bientôt dans un prochain article 😉
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :




Merci pour vos explications