

Déjà 30 minutes sur Stack Overflow, 1 heure sur Quora et tu ne comprends toujours pas POURQUOI la non-linéarité est nécessaire dans un Réseau de neurones ?
Si toi aussi tu es dans ce cas, tu es tombé au bon endroit !💡
Dans cet article, on explique le pourquoi de la non-linéarité en Deep Learning sous un angle différent de nos collègues Data Scientists.
Le but d’un Réseau de Neurones
Pour comprendre le rôle de la non-linéarité il faut d’abord se représenter clairement comment fonctionne un Réseau de Neurones
Le but principal d’un Réseau de Neurones est d’apprendre, de s’entraîner à résoudre une tâche.
Dit autrement, il doit optimiser ses performances
En mathématique, pour optimiser une fonction, on la dérive.
En effet, avec la dérivé, on peut facilement repérer la valeur pour laquelle la fonction est optimal.
Un exemple concret avec en bleu notre fonction et en rouge sa dérivée :
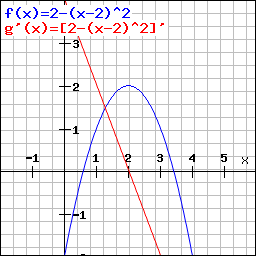
L’optimum d’une fonction est facilement repérable. Il est atteint lorsque la dérivée g'(x) = 0.
Grâce à cette dérivée, on peut connaître la valeur de x pour laquelle f(x) est optimal. En l’occurence lorsque x = 2.
Eh bien pour un Réseau de Neurones, c’est la même chose.
On va dériver le réseau pour trouver son optimum. C’est ce qu’on appelle la Descente de Gradient.
De même que pour une fonction, la dérivée nous permet de savoir pour quels valeurs de x le réseau optimise ses performances.
Seulement ici, on pas un seul x mais une multitude !
Effectivement, dans notre Réseau de Neurones, on a plusieurs fonctions.
En fait chaque couche d’un modèle de Deep Learning est une fonction à optimiser.
Ainsi lorsqu’on veut optimiser notre modèle, il faut optimiser chacune de ses couches.
Là, on comprend mieux pourquoi on appelle cela du Deep Learning, ou Apprentissage Profond. Le calcul des dérivées est démentiel ce qui le rend très long ou… très profond !
C’est d’ailleurs ce qui fait la force du Deep Learning. Cette complexité d’apprentissage lui permet justement de résoudre des tâches complexes.
Le but de la non-linéarité
Mais alors que vient faire la non-linéarité dans tout ça ?
Car non je n’ai pas oublié de le sujet principale de cet article !
Le but de la non-linéarité est de marquer un cap entre chaque couche.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
Je m’explique.
Les fonctions que l’on trouve dans les couches d’un Réseau de Neurones sont linéaires.
Le problème c’est qu’une succession de fonctions linéaires peut-être résumé très facilement à une seule fonction linéaire (la démonstration mathématique est trouvable sur internet).
Dit autrement, si on avait une succession de 100 couches linéaires, on pourrait les simplifier mathématiquement à seulement une couche linéaire.
On perd tout de suite en complexité !
En fait, avec uniquement la linéarité, on perd l’atout principal du Deep Learning : sa profondeur, le nombre de couche qui se succède.
Ainsi pour garder cette complexité, on va marquer une étape entre chacune des couches.
Cette étape, c’est la fonction d’activation et c’est elle qui apporte la non-linéarité.
Cette non-linéarité crée une frontière entre chacune des couches pour qu’elles ne puissent pas se simplifier.
Dit autrement, la non-linéarité permet de maintenir la complexité d’un Réseau de Neurones.
Ainsi un réseau de neurones est composé de couche et de fonctions d’activation qui permettent grâce à leur non-linéarité de créer des frontières artificielles entre les couches.
Conclusion
Finalement la non-linéarité c’est un peu la cerise sur le gateau du Réseau de Neurones. C’est ce qui lui permet de fonctionner.
Sans la non-linéarité pas de complexité. On aurait un Réseau d’une seule couche. On ne parlerait alors plus de Deep Learning mais seulement de Machine Learning.
Ainsi en Deep Learning, on a besoin de marquer la séparation entre chacune couche pour révéler leur utilité !
Pour rentrer plus en détails dans la non-linéarité, n’hésitez pas à aller voir notre article sur les différentes fonctions d’activation.
Aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources :
- Photo by Randall Ruiz on Unsplash
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



