

Already 30 minutes on Stack Overflow, 1 hour on Quora and you still don’t understand WHY non-linearity is necessary in a Neural Network ?
If you are also in this scenario, you’ve landed at the right spot !💡
In this article, we explain the reason for non-linearity in Deep Learning from a different angle than our fellow Data Scientists.
The purpose of a Neural Network
To understand the role of nonlinearity we must first get a clear picture of how a Neural Network works
The main purpose of a Neural Network is to learn, to train itself to solve a task.
In other words, it must optimize its performance
In mathematics, to optimize a function, we derive it.
Indeed, with the derivation, we can easily find the value for which the function is optimal.
A concrete example down there, with our function in blue and its derivative in red:
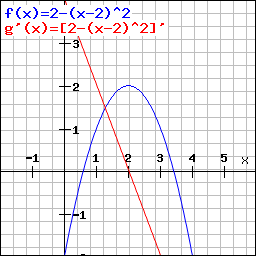
The optimum of a function is easily spotted. It is reached when the derivative g'(x) = 0.
Thanks to this derivative, we can determine the value of x for which f(x) is optimal. In this case when x = 2.
Well, for a Neural Network, it is the same thing.
We’ll derive the network to find its optimum. This is called Gradient Descent.
Just like for a function, the derivative enables us to know for which values of x the network optimizes its performance.
Only here, we don’t have only one x but a multitude !
Indeed, in our Neural Network, we have several functions.
In fact, each layer of a Deep Learning model is a function to optimize.
So when we want to optimize our model, we have to optimize each of its layers.
This is why we call it Deep Learning. The calculation of the derivatives is tremendous which makes it very long or… very deep !
This is the strength of Deep Learning. This learning complexity makes it able to solve complex tasks.
By the way, if your goal is to master Deep Learning - I've prepared the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :
Now we can get back to what I was talking about earlier.

The purpose of non-linearity
But what does non-linearity have to do with all this?
In case you wonder… no, I haven’t forgotten the main topic of this article !
The purpose of non-linearity is to mark a gap between each layer.
Let me explain.
The functions found in the layers of a Neural Network are linear.
The problem is that a succession of linear functions can be easily summarized to a single linear function (the mathematical demonstration can be found on the internet).
In other words, if we had a succession of 100 linear layers, we could simplify them mathematically to only one linear layer.
Immediately, we lose in complexity !
In fact, with only linearity, we lose the main asset of Deep Learning : its depth, the number of layers that follow one another.
So to keep this complexity, we will mark a step between each layer.
This step is the activation function and it is this step that brings the non-linearity.
This non-linearity creates a boundary between each of the layers so that they cannot be simplified.
In other words, non-linearity helps us to maintain the complexity of a neural network.
Thus, a neural network is composed of layers and activation functions that allow, thanks to their non-linearity, to create artificial boundaries between the layers.

Conclusion
Finally, non-linearity is the icing on the cake of the Neural Network. It is what allows it to function.
Without non-linearity, there wouldn’t be any complexity. We would have a single layer network. We would then no longer be talking about Deep Learning but only about Machine Learning.
Therefore in Deep Learning, we need to mark the separation between each layer to reveal their purpose !
To go into more detail on non-linearity, go check our article on the various activation functions and how to use them.
sources :
- Photo by Randall Ruiz on Unsplash
One last word, if you want to go further and learn about Deep Learning - I've prepared for you the Action plan to Master Neural networks. for you.
7 days of free advice from an Artificial Intelligence engineer to learn how to master neural networks from scratch:
- Plan your training
- Structure your projects
- Develop your Artificial Intelligence algorithms
I have based this program on scientific facts, on approaches proven by researchers, but also on my own techniques, which I have devised as I have gained experience in the field of Deep Learning.
To access it, click here :



